海外の自然言語処理活用事例シリーズはこちらです。  Part.1・
Part.1・ Part.2・
Part.2・ Part.3・
Part.3・ Part.4・
Part.4・ Part.5
Part.5
第三回 文章分類
第二回では、固有表現抽出を用いたテキストデータ解析について、分類の技術的背景とエンジン構築への応用例を紹介しました。第三回では固有表現抽出や感情分析などを用いた後、特定のカテゴリを適用して分類する文章分類について、技術の中身と活用事例を紹介します。
文章分類とは

設定した分類下で意味上のタグを付け分類する自然言語処理の手法の一つです。
第一回で取り上げた感情分析は、文章の単語や文脈を基に、書き手がどのように思っているのか、AIが判断する、という技術でした。紹介した事例では「ポジティブ」「ネガティブ」「ニュートラル」の3分類でしたが、例えば「喜び」「怒り」「悲しみ」「恐れ」「好き」の5分類に解析するツールや、文体を「確信的」「あいまい」など判断するツールも開発されています。
感情分析だけでなく、あらゆる文章データに対して応用することが可能です。「スポーツ」「旅行」「ペット」等の分類を設定してニュース記事を分類するなど、分析者のニーズに合わせて分類を設定できるため、目的に応じて適切な分類を設定することで、欲しい結果を得ることができます。
日常生活における文章分類
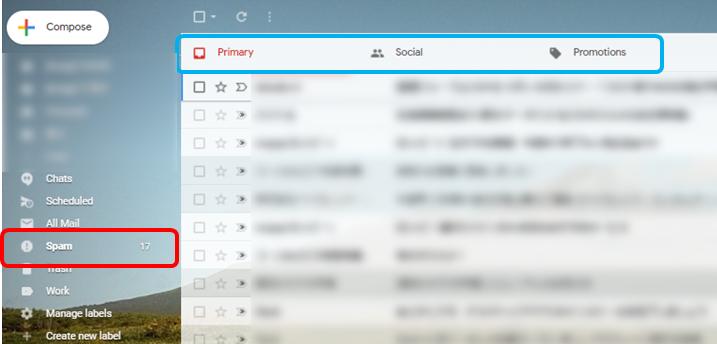
もはや日常生活や仕事になくてはならないツールとなったメール。この画面(図1)に見覚えはありませんか?実はここにも文章分類は使用されています。
図1赤枠の”Spam”(迷惑メール)に、大事なメールが入っており、筆者もあわてた経験があります。Gmailをはじめとしたメールツールでは、文章の内容を基に自動で判断し、通常メールと迷惑メールに振り分けるアルゴリズムが採用されています。また、通常メールのうち広告だと判断された場合はPromotion, ソーシャルメディア由来の通知はSocialといった図1青枠のタブに振り分けられ、内容と宛先の両方から判断する仕組みとなっているのです。
では、次にビジネスに応用する事例を見ていきましょう。
文章分類の応用事例
顧客分析
事前に学習した分類を基に文章分類を行うことで、属性ごとの顧客の声を大量に処理できます。調査プラットフォームをソフトウェアとして提供している米国のRetently社は、文章分類を適用して顧客の声を基に自社のサービスを分析し、弱みを強みに変えた実績があります。
同社は”Net Promoter Score”(NPS)を使用した顧客満足度の数値化を図るとともに、その理由を自由回答として調査しました。(図2)
「Product Features」「Product UX」や「Customer Support」、などのタグを作成し、自由回答の文章を分類しました。そして、タグごとのフィードバック数とNPSを算出しました。結果、「Product UX」や「Customer Support」はおおむね良い評価でしたが、「Product Features」の評価が悪くこの属性に課題があると認識し、より重要な機能をヒアリング・実装に集中して取り組みました。(図3)
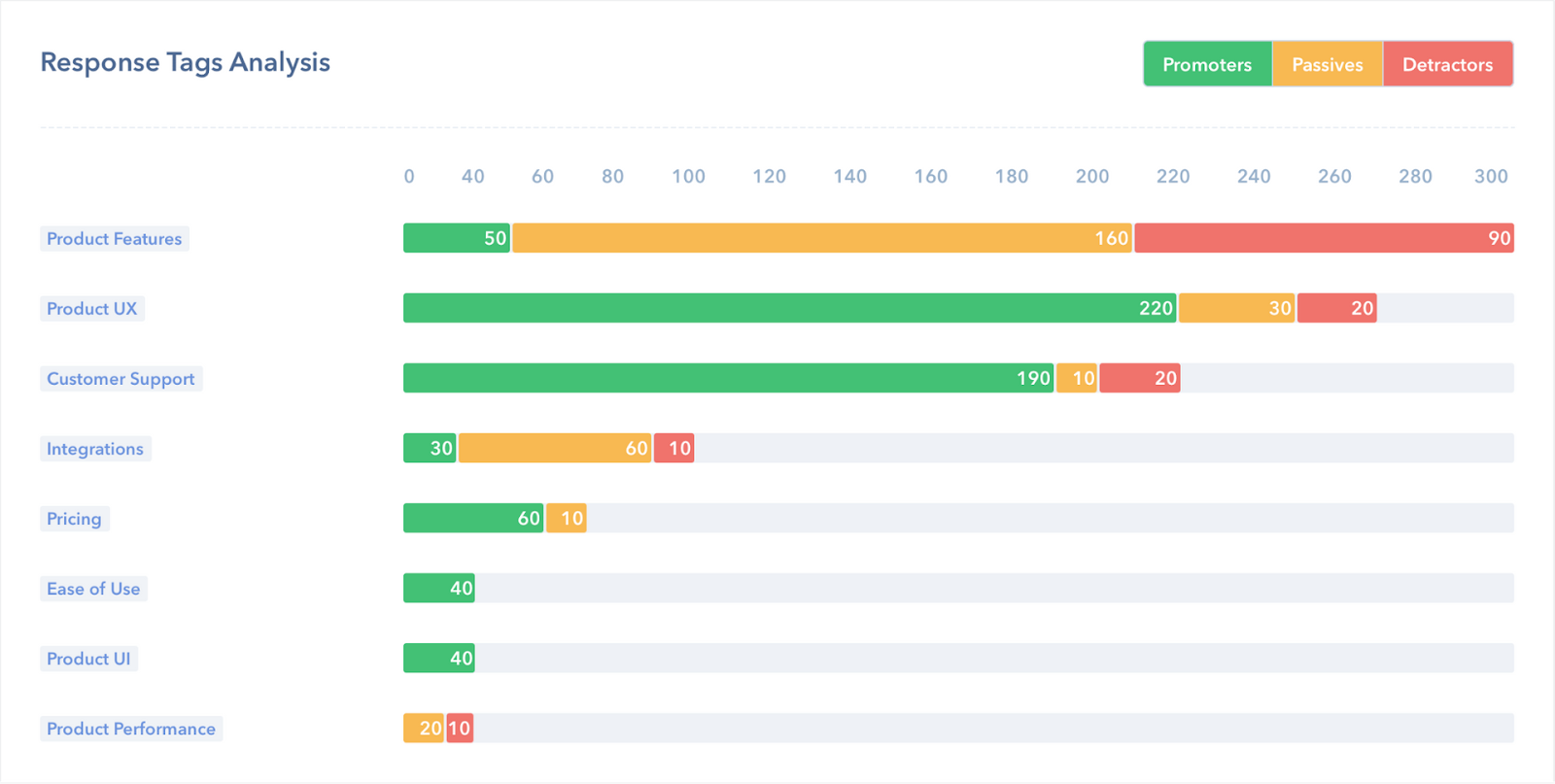
このように文章分類を使用したテキストデータ解析により、良い洞察と次のアクションにつながりました。
ニュースのキュレーション

特に雑然とした大量のテキストデータを取り扱う際、文章分類を使用して必要なデータだけをそろえ、解析をしやすくするように工夫することができます。米国のスタートアップであるCB Insights社はデータの収集・分析・可視化を取り扱っています。この会社の事業として、企業に対し求人情報や退職情報を測定し人材が滞留していないかどうかを評価する取り組みに本技術が採用されています。
求人情報や採用・退職は企業の長期計画・戦略や新陳代謝を反映しています。例えば、CTOの新規募集・着任は今後テクノロジー分野への進出を考えていることの反映かもしれません。逆に営業部長の退任は売上高の減少が原因かもしれません。データの利活用により企業の中でしか見えない活動を推測することができます。
こうした企業活動を推測し、企業の状態を測定するため、この会社は既存の正解データ(ここでは、人材系ニュースかそうでないか)を学習したうえで、解析対象の大量のテキストデータが人材系のニュースかどうか、という分類を短時間で行うように工夫しました。Python言語のScikit-learnモジュールを使用し、①前処理及び特徴量抽出②特徴量選定③分類④評価及び他の分類器との比較⑤分類器の選定と評価、を行っています。(技術の詳細はTracking Movers & Shakers: Tackling Human Resources News Classification (cbinsights.com)(外部リンク)をご覧ください。)
これまで大量のテキストデータを解析しきれていない、という企業にとっては、文章分類を使用することでデータを絞り、解析しやすい状態にするという意味で前処理の一環として検討できるかもしれません。
まとめ
複雑な文章を意味上のカテゴリに分類し、タグごとに解析を行う文章分類によって、必要な情報抽出や属性ごとの詳細な分析ができ、結果分析者を助けるツールとなりえるのではないでしょうか。
株式会社キーウォーカーでは、自然言語処理プラットフォームを展開し、教師データの作成から分析・可視化まで一通りのサービスを提供しています。BERTなどを使用したアルゴリズムにより、ドキュメント内に表現されている様々な意味属性を認識し、タグ付けをおこない、意味カテゴリごとに分類してテキストデータ解析をサポートできる体制が整っています。大量のテキストデータを分類し、詳細な解析を行い、より踏み込んだ問題の可視化に貢献できるでしょう。
次回連載では、テキストの自動要約を取り扱います。
参考
How Retently Automated Customer Feedback Analysis Using MonkeyLearn
Tracking Movers & Shakers: Tackling Human Resources News Classification
諸外国に学ぶ自然言語処理の最前線
関連記事
自然言語処理モデル「BERT」を使用した実践的な感情分析の応用例は、下記をご覧ください。
自然言語処理モデル「BERT」を用いたECサイトレビューデータの感情分析
自然言語処理モデル「BERT」を用いたECサイトレビューデータの感情分析(エンジニア向け)
