海外の自然言語処理活用事例シリーズはこちらです。  Part.1・
Part.1・ Part.2・
Part.2・ Part.3・
Part.3・ Part.4・
Part.4・ Part.5
Part.5
大量のデータを素早く解析 固有表現抽出
第一回では、感情分析を利用して顧客の声を正しく抽出し、次のアクションにつなげるヒントを紹介しました。第二回ではテキストデータから固有名詞などを取り出し、それらが文脈上どのような分類に該当するか、というタスクを自動的に行う固有表現抽出について、技術の中身と活用事例を紹介します。
固有表現抽出とは
前回記事で感情分析を使い、TwitterなどSNS(ソーシャル・ネットワーク・サービス)のコメントを解析した事例を見てきました。しかしナイキ社のようなコメントの偏りを防ぐため、できるだけ多くの必要な情報を短時間でアクセスして客観性や意見の幅を担保する必要があります。自然言語処理の一種である固有表現抽出を活用することで、大量のデータから必要な情報をタグ付けし分類することができます。ここで言う「必要な情報」とは、例えば、「佐藤さん」といった人名、「Google」といった組織名などいわゆる「固有名詞」に加え、「2時間」「10%」など時間や割合などの具体的な数字を指します。
「吉井さんは7月14日、4000円のウニを食べに積丹半島に行くため、朝6時に起床した。」潜在顧客に対するマーケティングの一環でこんなコメントを発見し、解析したいとしましょう。固有表現抽出を正しく使用すると、この文章に対する機械の認識は以下の通りとなります。
「<person>吉井さん</person>は<date>7月1日</date>、<money>4000円</money>のウニを食べに<place>積丹半島</place>に行くため、<time>6時</time>に起床した。」
→≪人名:吉井さん 日付:7月1日 金額:4000円 土地名:積丹半島 時間:6時≫
“<>”の中は分類名(後述)、”/”(スラッシュ)は固有表現の終わりを意味しています。「は」などの助詞や「ウニ」「起床した」などその他の語はまとめて区別されます。大量のテキストデータからこうした固有表現を素早く分類する技術が固有表現抽出です。
固有表現の種類と拡張固有表現階層
固有表現はその分類に議論を重ねてきており、いまだ国際的にゆらぎがあります。最も古い定義とされているのは、1996年に米国の評価型プロジェクトであるMUC(Message Understanding Conference)が定義した7種類とされています(図1)。日本では、情報検索・抽出のワークショップであるIREX (Information Retrieval and Extraction Exercise)が、 上記の7分類に「固有物名」を足した8分類を固有表現の定義としています(Sekine et al., 2000)。

(図1:MUCが定義した固有表現分類。Grishman and Sundheim, 1996をもとに筆者作成)
MUCやIREXの定義を元に、ニューヨーク大学の関根聡らは2002年約150種類の分類からなる拡張固有表現階層(Sekine et al., 2002)を提唱しました(最終更新:2016年)。英語の新聞から頻度が高く使用されると考えられる名詞句に対しラベルの改変を行い、さらに百科事典・シソーラスなどの電子辞書を使用して試行錯誤したものをクラスとしたものです(図2)。
(※詳細は関根の拡張固有階層表現(外部リンク)の、「概要」欄をご覧ください。)
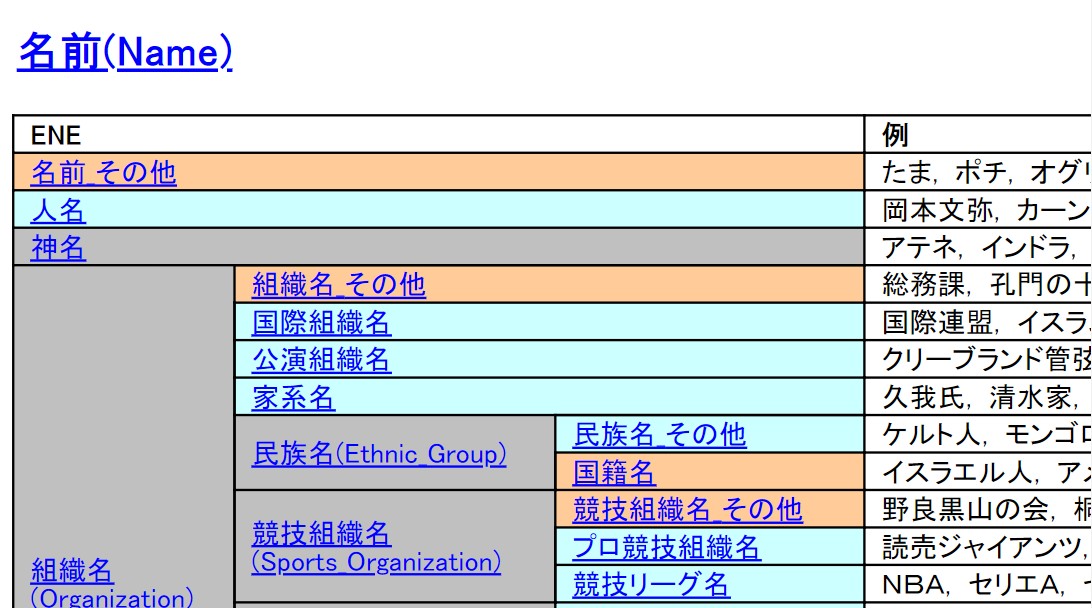
(図2:拡張固有表現階層の一部。まず、「名前」「時間表現」「数値表現」とのカテゴリに大別し、それぞれのカテゴリ内で「組織名」>「民族名」などと小分類分けを行い、それぞれの分類に該当する言葉を表示しています。出典:拡張固有表現階層)
固有表現抽出の応用例
検索・レコメンドエンジン構築
宿泊施設予約サービスのBooking.comでは、目的地や諸条件の検索から、旅行後の顧客レビューまで、多くのテキストデータを収集しています。同社のデータサイエンティストによれば、固有表現抽出により適切な品詞定義およびタグ付けを複数のモデル間で行い、検索エンジンを使用した検索結果やレコメンド機能として期待できる結果を表示する速度や精度に改善があったといいます(図3)。
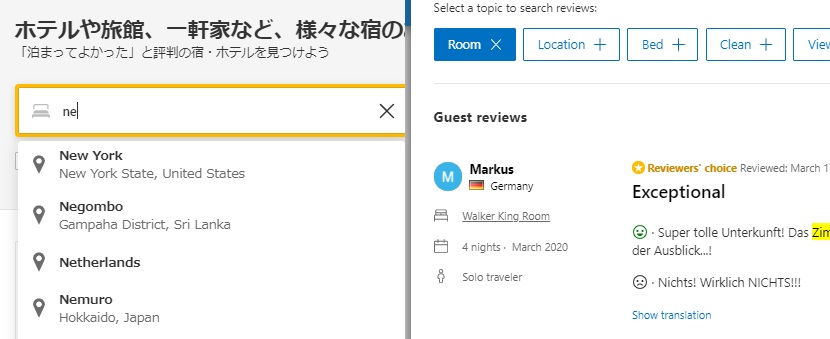
(図3 Booking.comにおける固有表現抽出の応用例。 左:Booking.comにて、「ne」と打った時にレコメンドとして「ニューヨーク」「オランダ」「根室」など、よく検索される行き先がすぐに提示される。 右:宿泊施設ごとに口コミを分析したタグ付けとよくあるタグ表示を行っており、旅行者はタグをクリックすることで関連する口コミにすぐにアクセスできる。)
具体的には、①構造化サポートベクトルマシン(Structured SVM)モデル(Tsochantaridis et al., 2005)、②単語埋め込み(Word Embedding)を施した再帰的ニューラルネットワーク(Recurrent Neural Network)(Mesnil et al., 2013)、③Learning2Search(Chang et al., 2015)、の3モデルをそれぞれ使用しました。各モデルを使用し大量の仮想テキストデータ(教師データ)を「目的地」「設備」「宿タイプ」のうちいずれかに分類し、教師データと照合したPresicion(適合率)とRecall(再現率)を用いてモデルの優劣を議論しました。
(※比較検討の結果や各モデルの詳細など詳細はNamed Entity Classification(外部リンク)をご覧ください。)
電子新聞へのアクセス

オランダの新聞社であるEuropeanaは、同国の図書館において同新聞の過去記事に素早くアクセスでき、かつ検索語を目立たせた上で付近を表示するシステムを開発しました。これまでOCRの解読システムの精度が低く、かつ1000万ページ以上もある過去記事は膨大な情報処理となり、時間がかかる背景がありました。そこでスタンフォード大学が開発したCRF-NERモデル(参考:The Stanford Natural Language Processing Group)を使用し、機械学習により単語やその分類を学習したうえでデータを解析、タグ付けを繰り返して元データと比較しました。結果、PrecisionとRecallに一定の満足いく値を得たため、本モデルは使用可能であると判断、運用して利便性が向上したといいます。
まとめ
固有表現抽出を用いることで、大量のテキストデータを素早く解析し重要な情報の抽出に役立ちます。Booking.comの事例の通り様々なモデルが開発されており、日本語にも対応できる環境が構築されつつあります。大量のテキストデータを扱う際にぜひ固有表現抽出の活用を検討してみてはいかがでしょうか。
株式会社キーウォーカーでは、自然言語処理プラットフォームを展開し、教師データの作成から分析・可視化まで一通りのサービスを提供しています。特に固有表現抽出に関しては、文章中の様々な表現から「場所」「人名」「組織」「製品やサービス」「イベント」「企業の強みや弱み」など、独自のアルゴリズムで構築した意味カテゴリごとに抽出することができます。
次回連載では、固有表現抽出の上で文章自体を分類する文章分類(クラスタリング)を取り扱います。
参考
Grishman R. and Sundheim B., 1996. Design of the MUC-6 evaluation. [DESIGN OF THE MUC-6 EVALUATION, accessed on 30th April, 2021.]
Sekine S. and Eriguchi Y. 2000. Japanese Named Entity Extraction Evaluation – Analysis of Results -. [Japanese Named Entity Extraction Evaluation – Analysis of Results -, accessed on 30th April.]
Sekine S., Sudo K. and Nozaki C. 2002. Extended Named Entity Hierarchy. [Extended Named Entity Hierarchy, accessed on 30th April, 2021.]
「関根の拡張固有表現階層」定義(2016年9月16日最終更新)
Tsochantaridis I., Joachims T., Hofmann T. and Altun Y. 2005. Large Margin Methods for Structured and Interdependent Output Variables. Journal of Machine Learning Research 6 1453–1484. [Large Margin Methods for Structured and Interdependent Output Variables, accessed on 1st May, 2021]
Mesnil G., He X., Deng L. and Bengio Y. 2013. Investigation of Recurrent-Neural-Network Architectures and Learning Methods for Spoken Language Understanding. Interspeech [Investigation of Recurrent-Neural-Network Architectures and Learning Methods for Spoken Language Understanding, accessed on 1st May, 2021]
Chang K.W., He H., Daume H. and Langford J. 2015. Learning to Search for Dependencies. [Learning to Search for Dependencies, accessed on 1st May, 2021]
3 Replies to “Named Entity Recognition for digitised newspapers”
諸外国に学ぶ自然言語処理の最前線
関連記事
自然言語処理モデル「BERT」を使用した実践的な感情分析の応用例は、下記をご覧ください。
自然言語処理モデル「BERT」を用いたECサイトレビューデータの感情分析
自然言語処理モデル「BERT」を用いたECサイトレビューデータの感情分析(エンジニア向け)
