Solution | Lead Scoring
https://knowledge.dataiku.com/latest/solutions/financial-services/solution-lead-scoring.html
前回の「Dataikuでリードスコアリングをやってみた(前処理編)」にて、データの前処理までが完了しました。今回はリードが顧客になるか否か分析のためのモデルの作成〜評価までの手順について説明します。
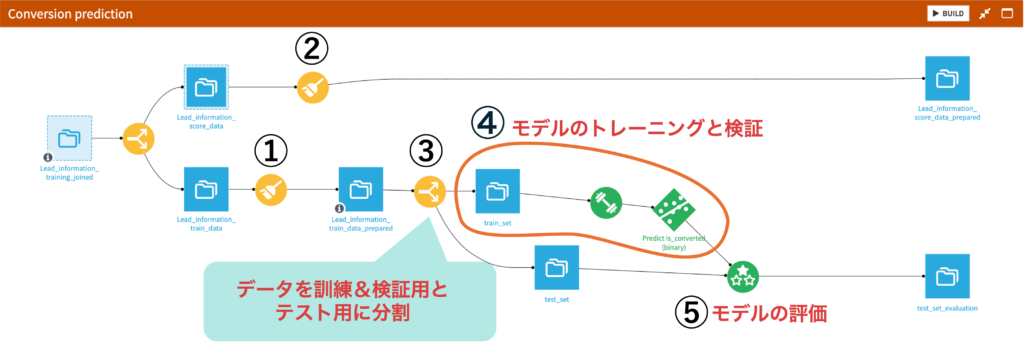
具体的には、次のDataikuフローの①-⑤のプロセスについて順番に辿っていきます。
3.3 モデルの作成から評価まで
① PrepareレシピでLead_information_train_dataのoriginal_datasetカラムを削除
Prepareレシピでカラムを削除する方法については前回のブログをご参照ください。
出力データ名:Lead_information_train_data_prepared
② PrepareレシピでLead_information_score_dataのoriginal_dataset, conversion_date, is_convertedカラムを削除
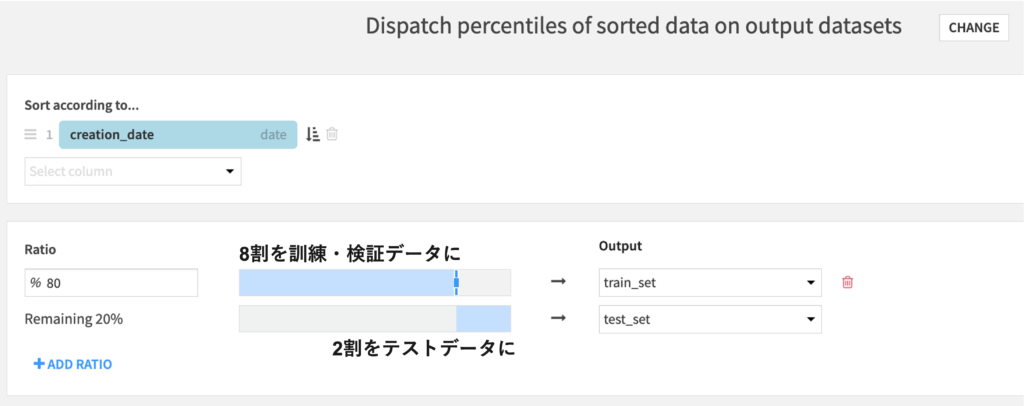
出力データ名:Lead_information_score_data_prepared③ Splitレシピでデータを分割:訓練&検証8割, テスト2割
新しいデータにモデルを適用した時の精度を評価するために、データを訓練&検証用とテスト用に分割します。これはDataikuのSplitレシピで可能です。具体的な操作方法については前回のブログもご参照ください。Splittingタブのパラメータは下記のように設定します。
④ LABでモデルを作成してベストモデルをデプロイする
train_setを選択した状態でLABをクリック→ Visual analysisのところに”New Analysis”というメニューが現れるのでそれをクリック
→ 分析の名前を”New analysis name”に入れ、”CREATE ANALYSIS”をクリック
→ ”CREATE FIRST MODEL”→”AutoML Prediction”の順に選択
→ ”Create prediction model on”の後のドロップダウンリストでは、今回予測したい”is_converted”を選択して”CREATE”をクリック
ここまで進んだらDESIGNタブでモデル作成のための各種設定をしていきましょう。
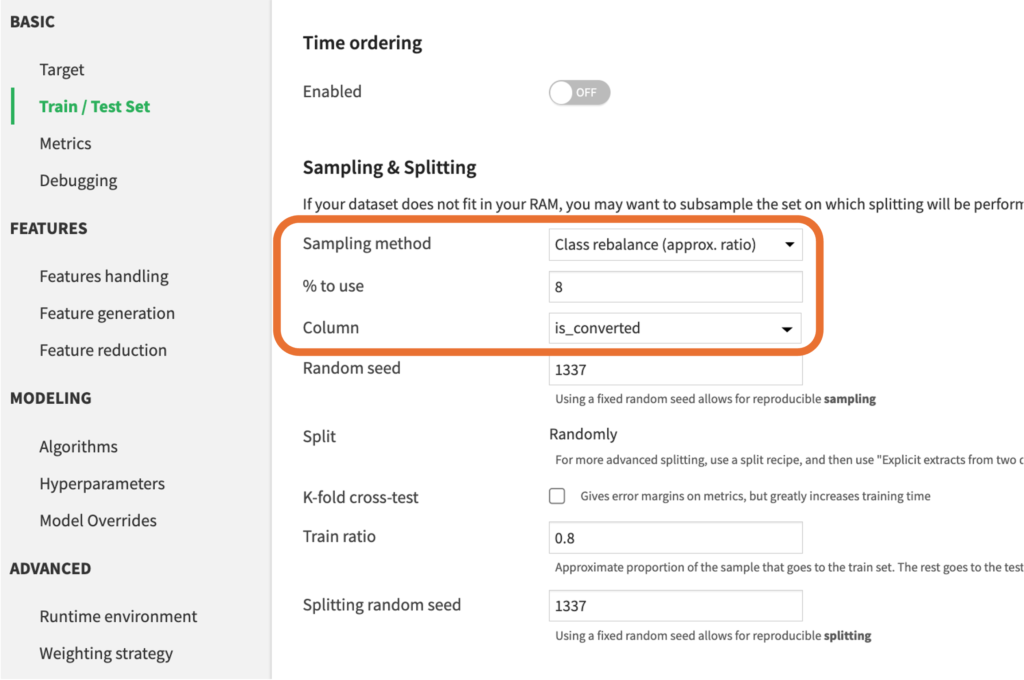
1. Train/Test setタブでアンダーサンプリングの設定をする
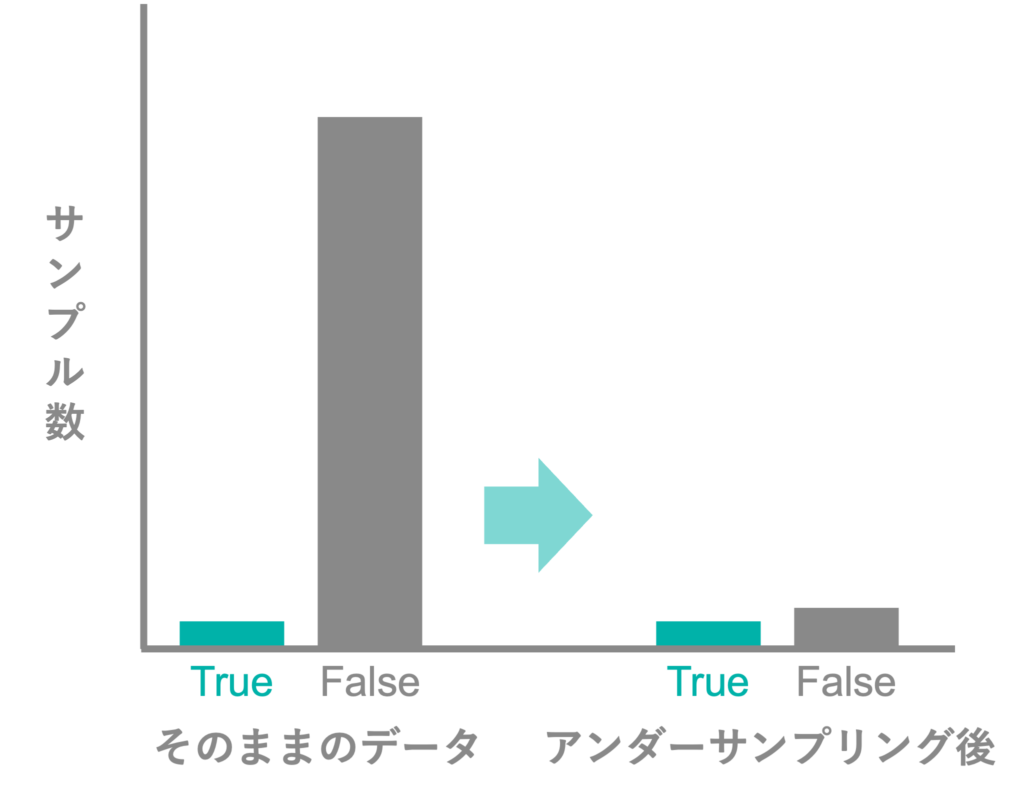
今回使用するデータではis_converted=TrueがFalseに比べて大幅に少なくなっています。このままFalseのデータが非常に多く、Trueのデータが極端に少ないデータでモデルを構築すると、予測結果はFalseとなることが多く、本来Trueであるデータを精度良く予測することが困難となります。そのため、今回は多数派であるFalseのデータを削りTrueのデータと同程度のサンプル数にしてモデルを構築していきます。
このような方法でクラス間のサンプルの均衡を取ってモデルを構築することをアンダーサンプリングと呼びます。
TrueとFalseのサンプル数の均衡を取るために、今回は使用するデータの割合を8%に設定します。
アンダーサンプリング済みのトレーニングデータセットの内訳は次の図のようになっています。

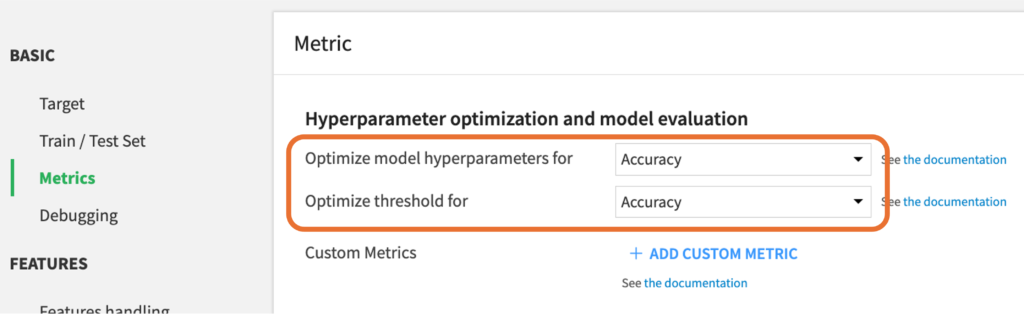
2. Metricsタブで最適化するパラメータとモデル評価の指標をAccuracyに設定
リードスコアリングの目的上、TrueをTrue, FalseをFalseと正しく予測するモデルが適切であるため、最適化するパラメータとモデル評価の指標をAccuracyに設定します。Accuracy:全体のうちどれだけ正解があるかを表す指標


MetricsタブのOptimize model hyperparameters forとOptimize threshold forをAccuracyに設定します。
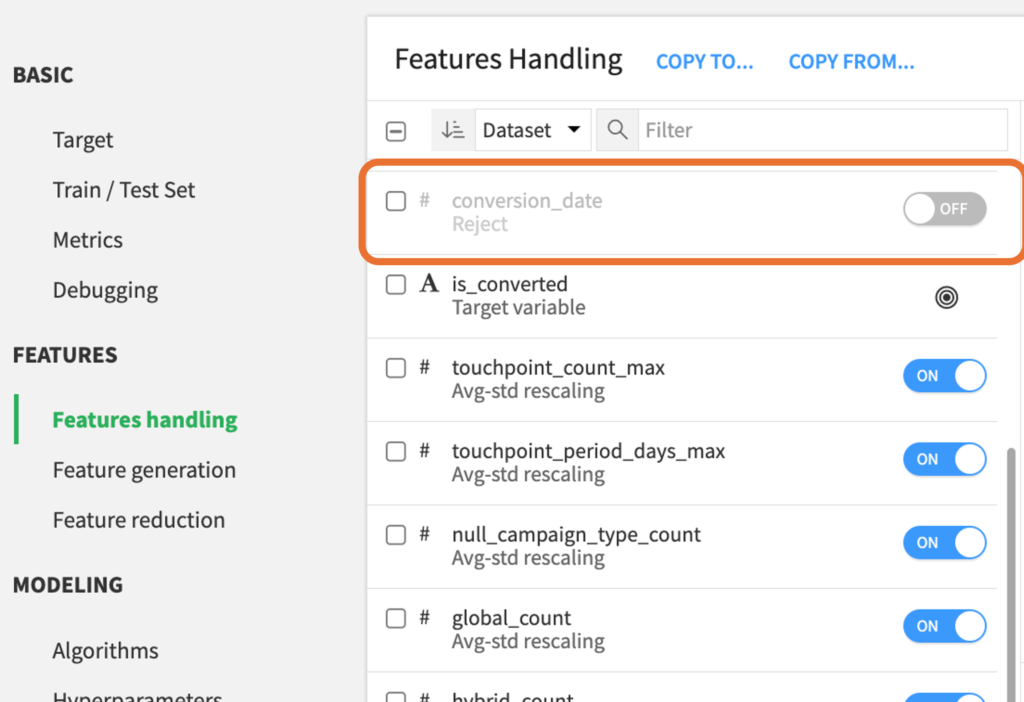
3. Features handlingタブで予測の答えとなる変数や予測に不要な変数を除外
conversion_dateはリードが顧客になった日を表す変数で、顧客になったリードには日付のデータが入っており、そうでないリードのデータはNULLになっています。したがって、is_convertedの予測に用いるのは不適切であるためFeatures handlingタブで除外します。また、lead_idの作成日の変数であるcreation_dateは予測に必要ないと考えられるため、同じく除外します。
4. Algorithmsタブでアルゴリズムを選択
今回はデフォルトのRandom ForestとLogistic Regressionを選択します。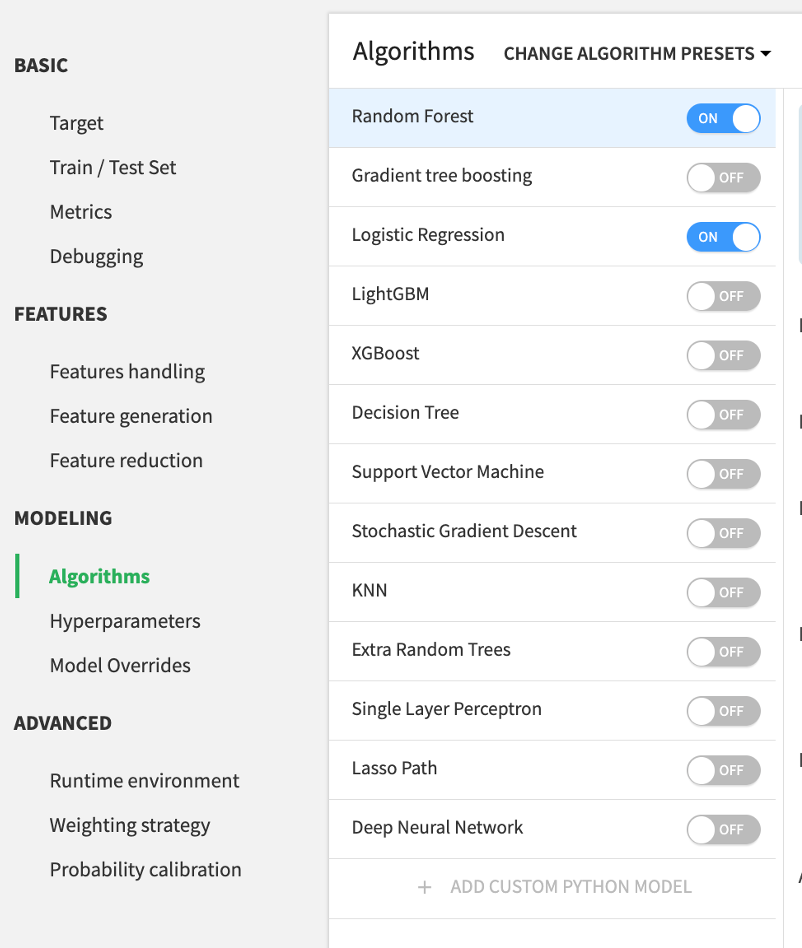
以上1〜4より、下記の設定にてis_convertedを予測するモデルを作成します。この設定で右上の”TRAIN”をクリックして学習を開始します。
アルゴリズム:ランダムフォレスト・ロジスティック回帰
説明変数:leadの属性とキャンペーンの変数計18
最適化するハイパーパラメータ・分類の閾値:Accuracy
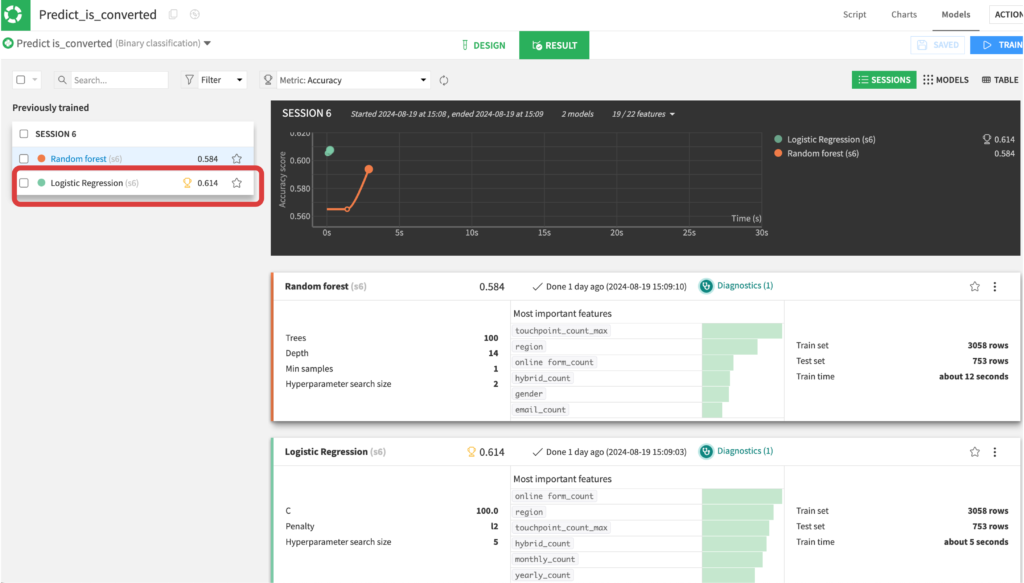
5. 学習の結果をRESULTSタブで確認
トロフィーのアイコンが表示されているモデルがベストモデルです。ロジスティック回帰の方がわずかに精度が良いという結果になっています。Logistic regressionをクリックすると、分類結果の詳細を確認することができます。
6. Feature importanceのタブで予測に貢献していない変数を確認して除外
Feature importanceのタブでは、Shapley valueを元に各変数がどの程度予測に貢献しているのかを確認することができます。特徴量Xがモデルに加わることによる予測値の変動量(限界貢献度)を、特徴量の全ての順序の組み合わせで計算し、平均を取ることでShapley valueが求まります。ここではnull_campaign_type_countとtouchpoint_period_days_maxが予測に全く貢献していないことがわかります。DESIGNタブのFeature Handlingでこれらの変数を除外して再度学習させましょう。
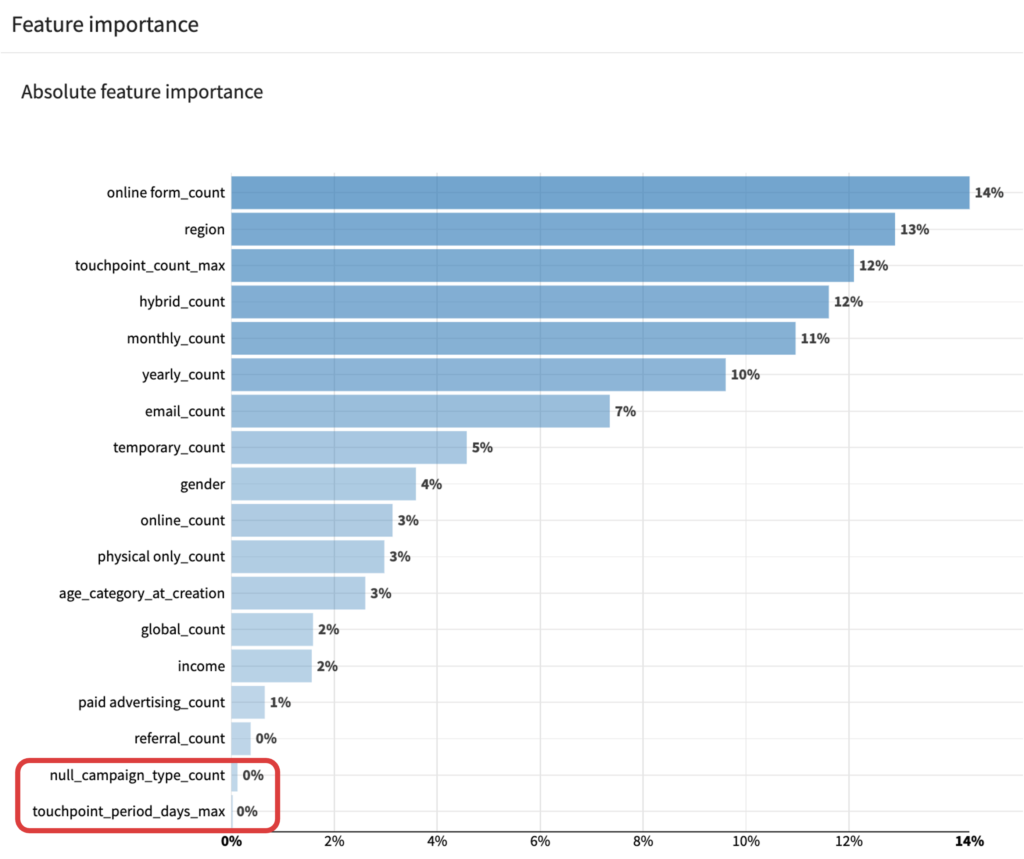
7. ベストモデルの解釈
予測に貢献しない変数を除外→再度学習というプロセスを繰り返して得られたベストモデル(ロジスティック回帰)の精度を、Confusion matrixタブで確認します。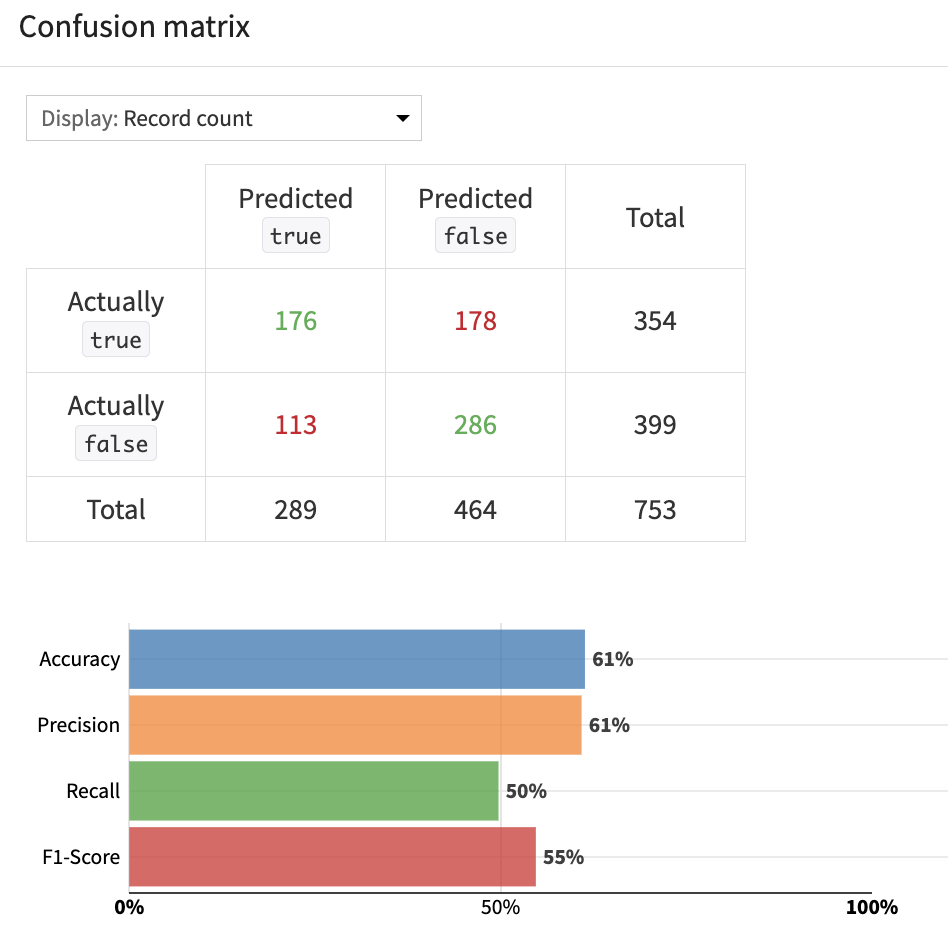
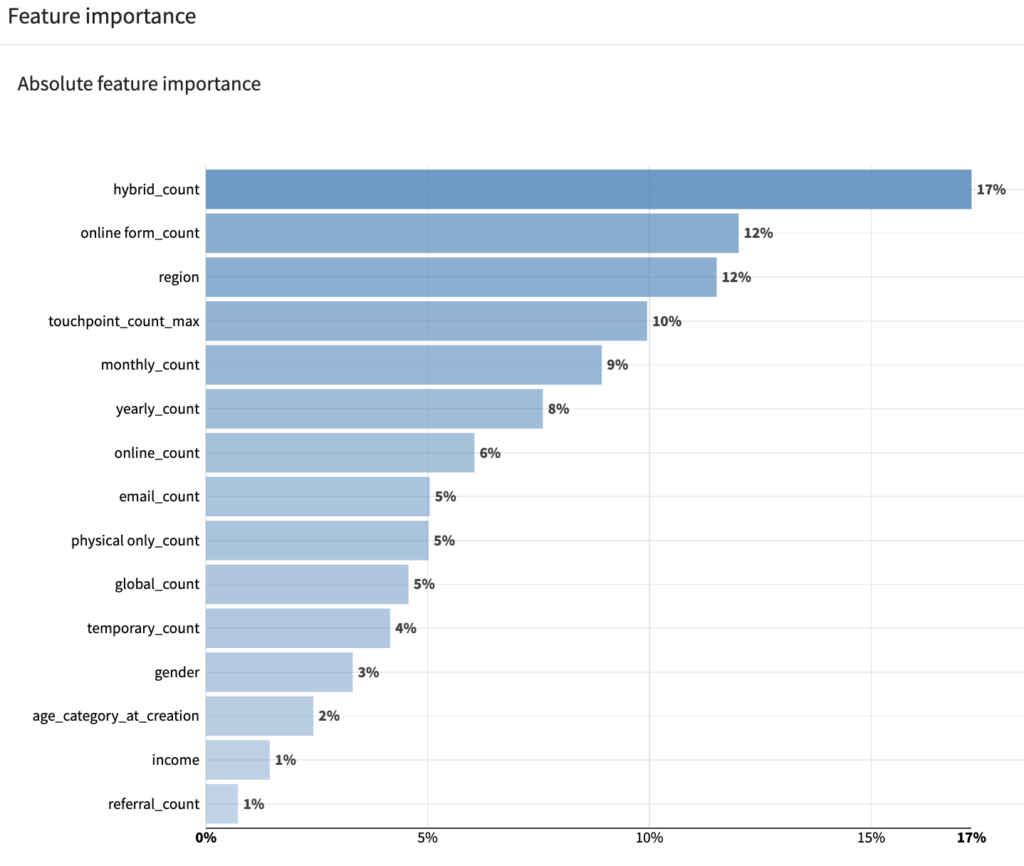
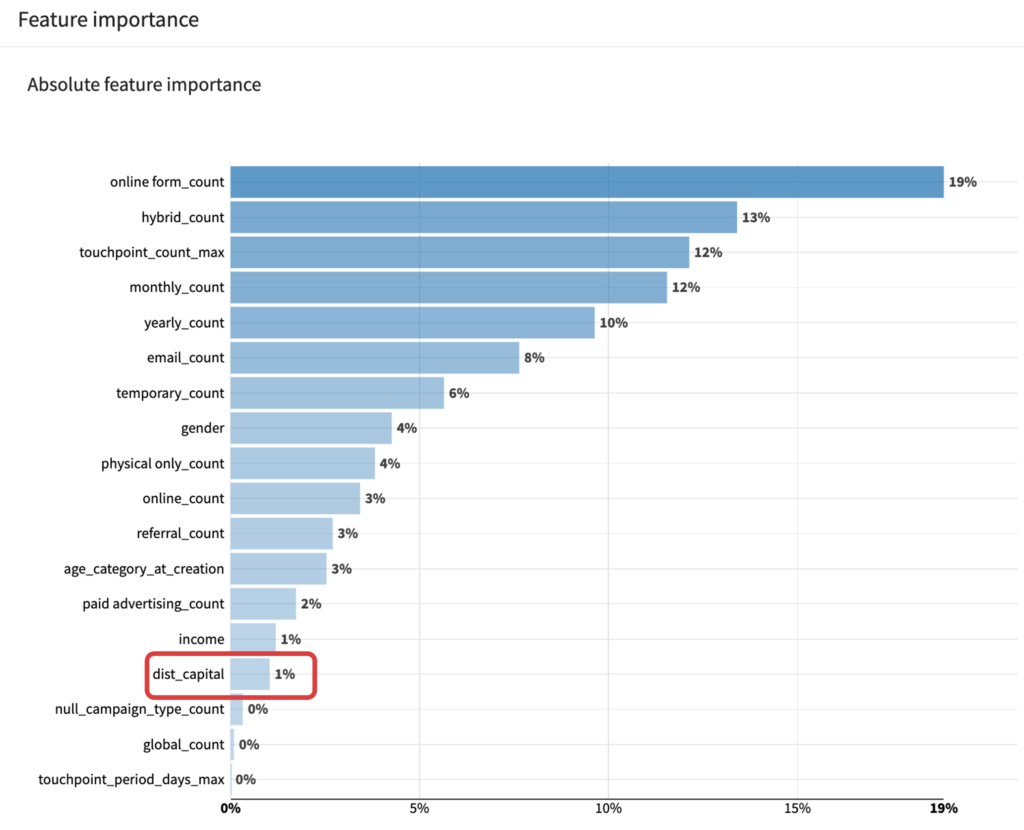
次にFeature importanceのタブで、各変数がどの程度予測に貢献しているのかを確認します。
キャンペーンの効果としてはonline_formでの接触回数やmonthlyキャンペーンでの接触回数、リードの属性としては居住地域が貢献していました。
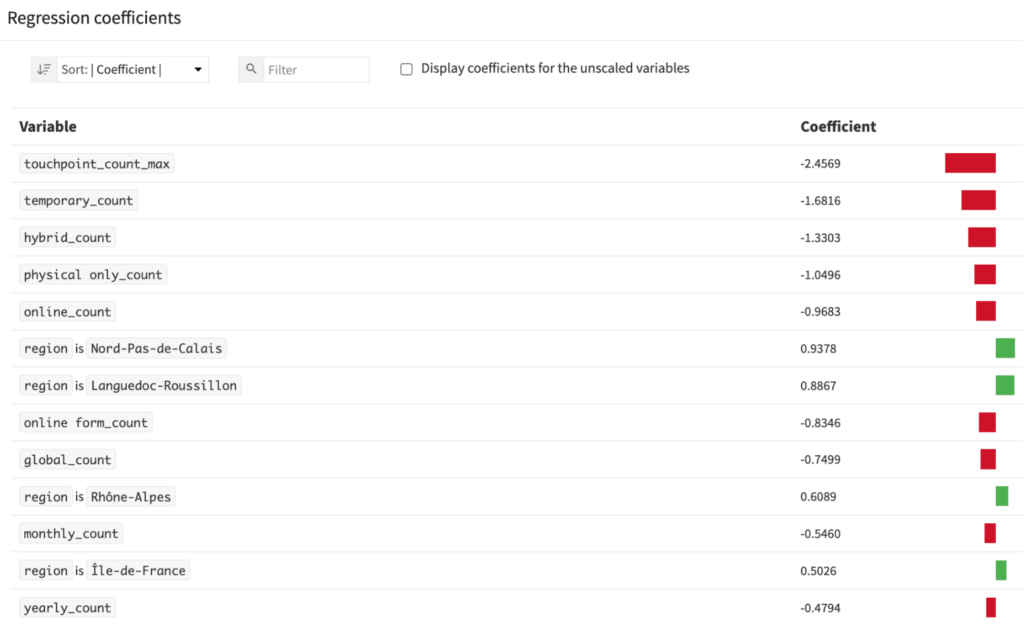
各変数が顧客になるか否かに正負どちらの影響をもたらしているのかはRegression coefficientsで確認できます。貢献度が高かったキャンペーンの効果は軒並み負のようです。顧客になることとキャンペーンとの間の因果関係はわかりませんが、少なくともリードへのキャンペーンはうまくいっていなさそうです。
一方で顧客の属性の特徴量の一つであるregion(居住地域)の効果を見てみると、顧客になりやすい地域があるようです。このregionというカテゴリ変数はあまりにも多いので(全部で22個)何らかの形で1つの連続変数にできないでしょうか。
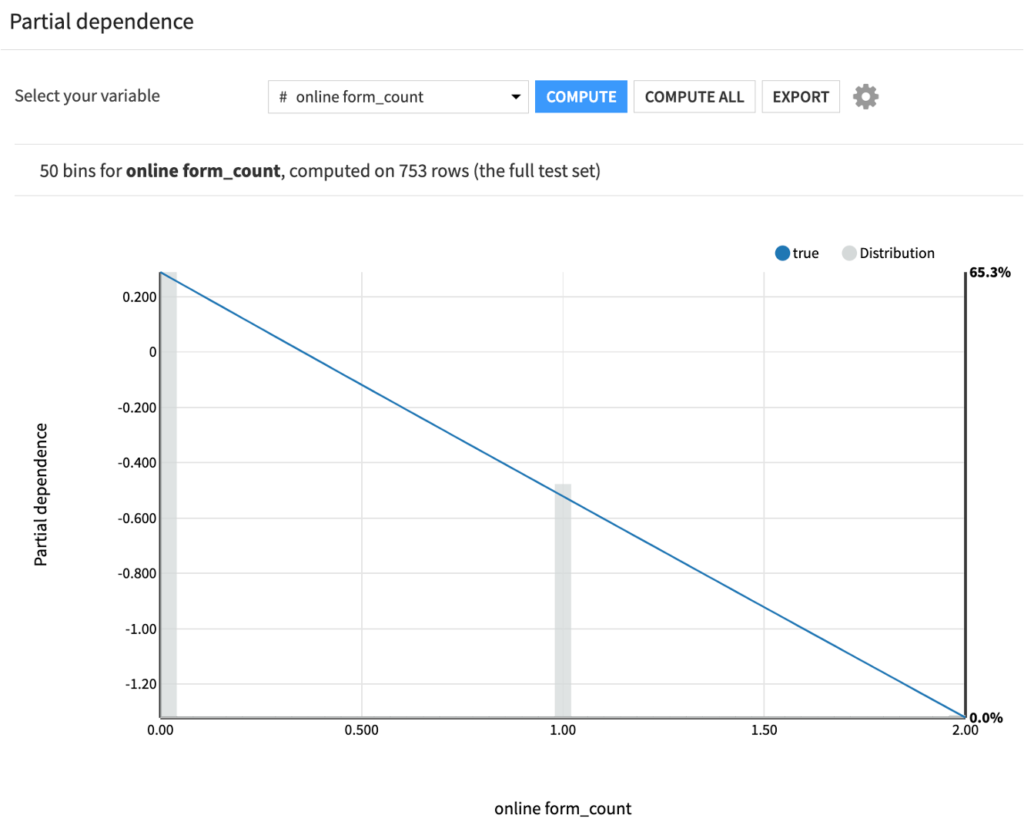
Partial dependence でも最も予測に貢献していた特徴量online_form_countの効果を見てみると、他のすべての条件が同じであれば、online_form_countの回数が多いサンプルほど顧客になる見込みが平均的な値よりも低くなる傾向が出ています。
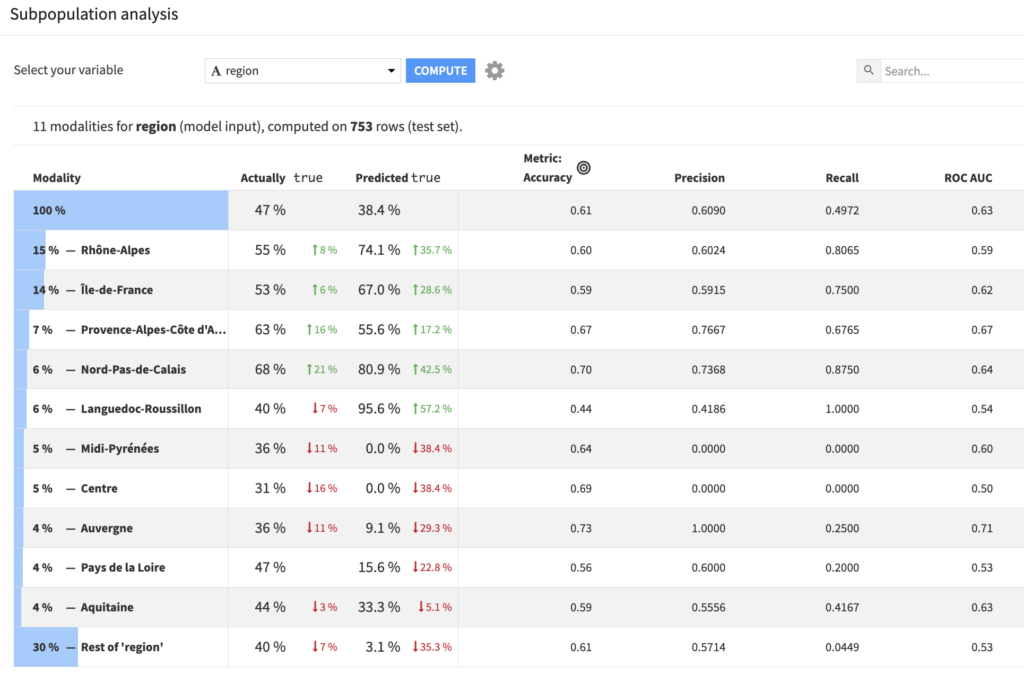
Subpopulation analysisはモデルが部分集団間で同じように振る舞うかどうかを評価するのに役立ちます。そこで、Subpopulation analysisのタブで各regionのサンプルの予測精度を確認してみると、精度はregionによってまちまちであることがわかります。
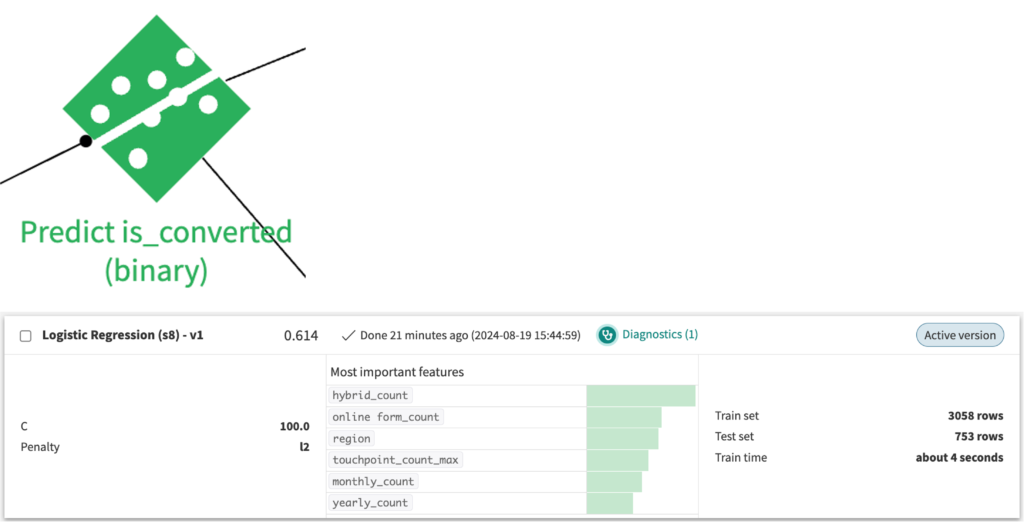
それではこのベストモデルをデプロイします。デプロイするとフローに2種類の緑のアイコンが追加され、Predict_is_convertedの方を開いてみると、先ほどのベストモデルがActiveとなっているのが確認できます。
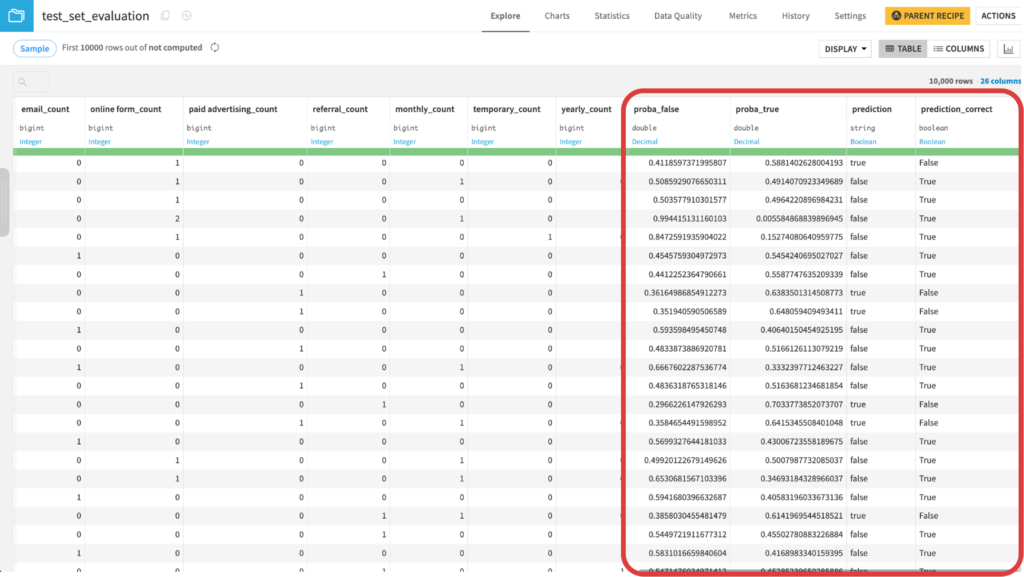
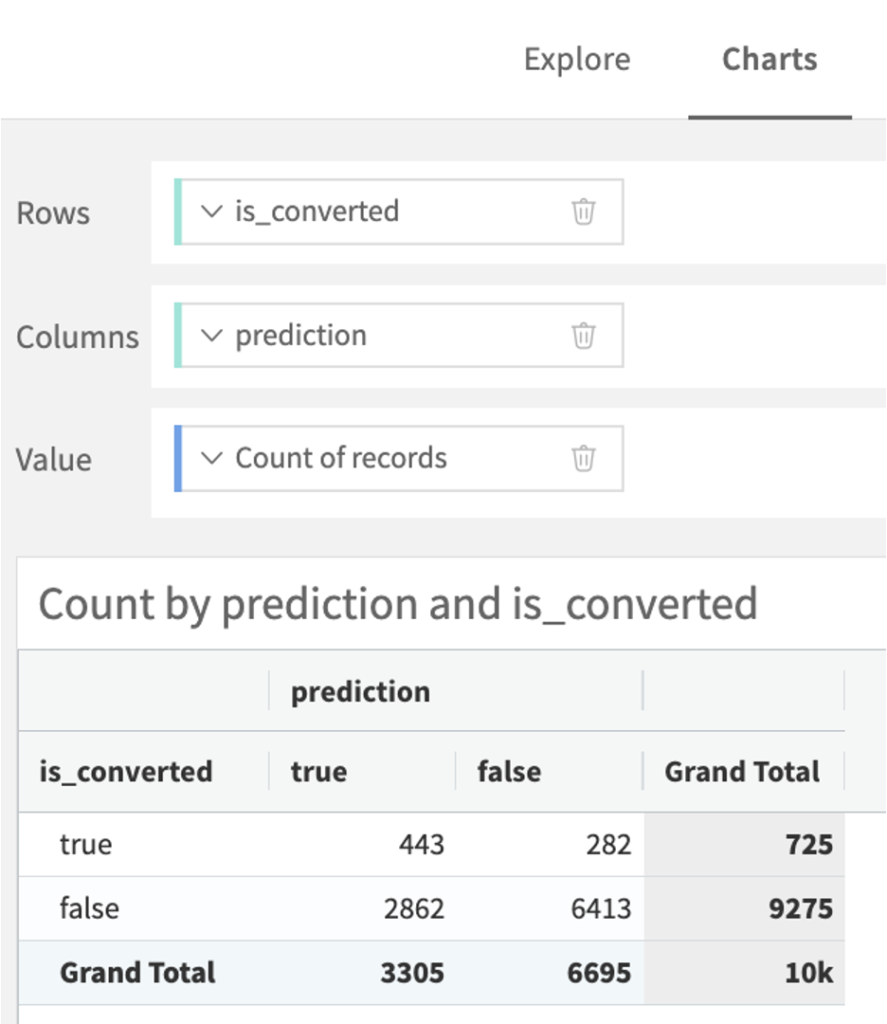
⑤ Evaluateレシピを用いてテストデータにベストモデルを適用
Evaluateレシピを用いてtest_setにベストモデルを適用します。出力データ名はtest_set_evaluationとしておきます。 それではtest_set_evaluationデータについて、ChartsでConfusion matrixを作り分類結果を確認しましょう。Accuracyを計算すると(TP + TN) / (TP + FP + TN + FN)=(443+6413)/(443+2862+6413+282)=約0.69になりました。
Trueの判別がうまくいっていないようです。どうすれば精度を改善できるのでしょうか?
3.4 精度の向上に向けた実践と考察
今回はカテゴリ変数もその水準数もそれぞれ多いので、計算量が非常に多くなっています。加えて、この状態ではモデルの生成時に存在しなかったデータの活用ができないため、カテゴリ変数の取り扱いについて何らかの工夫をする必要がありそうです。今回はregionデータを首都からの距離のデータに変換することで、上記の問題を解決した上で精度の向上を目指してみます。
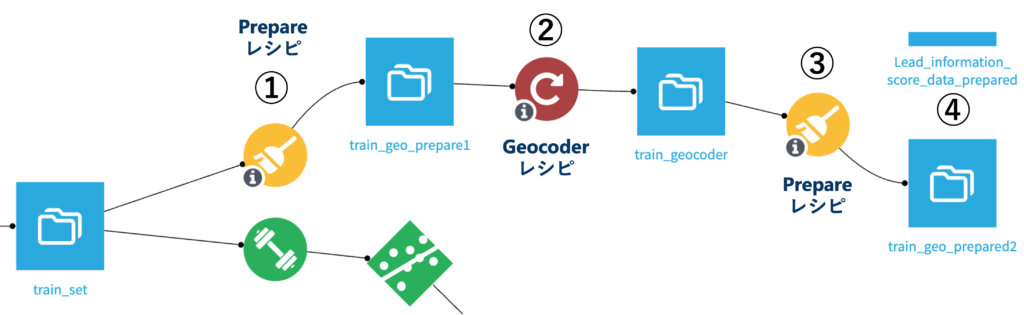
① Prepareレシピでregionをユニークな値に変換
formulaに”join([region, “France”],”,”)と入力して実行(カラム名:address)② Geocoderレシピでaddress列を元にregionの緯度経度を取得
Geocoderレシピを使うことで、ユニークな住所から緯度経度情報を取得することができます。”Geocoder” pluginは”Forward geocoding”を選択してください。そして以下のパラメータの設定をしてレシピを実行します。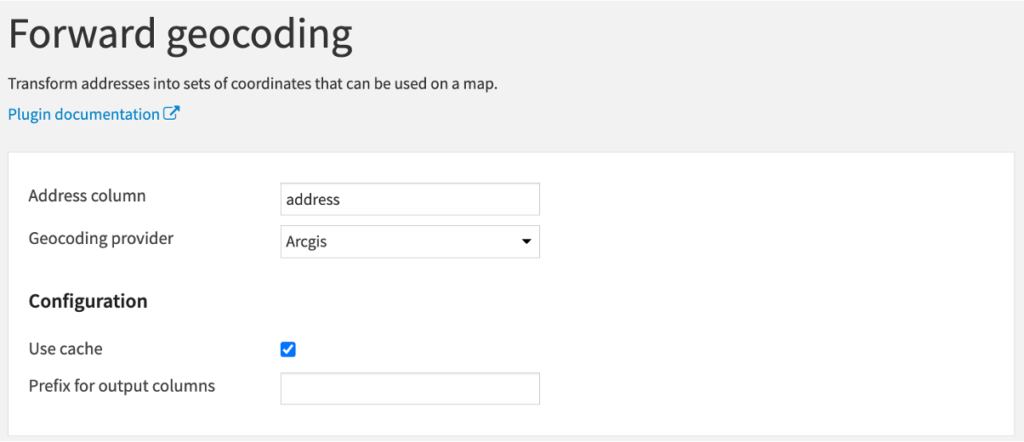
③ Prepareレシピで緯度経度列をGeopointに変換して、首都があるregionであるÎle-de-Franceからの距離を計算
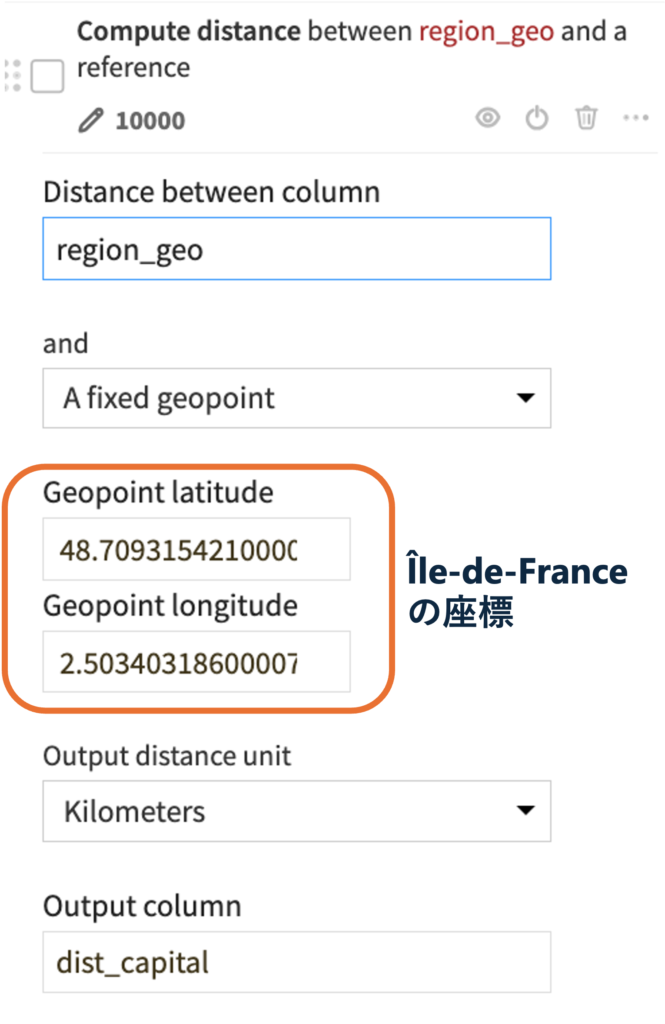
1. Create geopoint from latitude & longitudeで緯度経度カラム(latitudeとlongitude)を指定して、Geopointを含むregion_geo列を出力2. Compute distance between geospatial objectで以下の設定をして、各regionの中心座標から首都がある地域Île-de-Franceまでの距離を計算(dist_capitalカラム)
④ LABでregion変数を変換したモデルで再度学習
dist_capitalカラムを含め不要なカラム(regionカラムやdist_capitalカラムに変換するまでの過程のカラム)を除外した上で、データを学習させました。 Accuracyはやや低下してしまいました。regionを首都からの距離に変換した変数は、モデルへの貢献度がとても低いです。他の変換方法も検討した方が良いかもしれません(地域の人口や都市化の程度など)。
リードが顧客になるか否かの予測はまずまずの結果で、モデルとしては改善の余地が多々ありそうです。今後考えられるモデルの工夫としては、年齢や年収のような順序尺度の説明変数をダミー変数として扱った上で、順序が隣り合うカテゴリの回帰係数を滑らかに変化させるような罰則付き推定をするという方法などが考えられます。この場合はノーコードというわけにはいかず、PythonやRのコードレシピを挟む必要がありそうです。もし実際のデータを用いてリードスコアリングをする場合には、情報量を落とさないために年齢や収入をカテゴリではなく実際の値で取得するといった工夫も考えられます。
このようにDataikuは、ノーコードでデータを一括管理し機械学習のモデル構築を可能にします。
弊社では長年培ってきたデータソリューションの知見を活かし、Dataikuの環境構築から運用支援までトータルでサポートします。
社内に散在しているデータを統合し活用したい皆様からのお問い合わせをお待ちしております。
