はじめに

- 本記事では LangChain を用いて任意の URL から情報を抽出するシステムの minimum viable product について紹介します。
- 特定のページを対象に情報抽出を行ったところ、ベースラインとしてはある程度の抽出精度が期待できる結果となりました(多様なページに対する定量評価も今後行う予定です)。
- 一方で一部のクエリに対して抽出誤りが見られました。電話番号や株価など抽出誤りが許容されない情報については、あくまで抽出支援として、人が介在する運用を検討する必要があると改めて感じました。
- 結論としては、高精度に情報抽出できる従来のクローラと併せて、互いの苦手な領域を補っていく仕組みを整えていきたいなと思います。
おことわり
- 著者は自然言語処理エンジニアとして絶賛勉強中です。記事の誤り、推奨される方法等がありましたらご指摘いただけますと幸いです。
- 本記事は読者層を明確に想定した上で書かれたものではありません。就職先として弊社を考えている学生の方々、弊社クローラサービスの利用を検討されているお客様、著者と同様に絶賛勉強中のエンジニアなど、特定の個人に刺さる内容であれば幸いです。
背景
外部環境 (Opportunity)
近ごろ ChatGPT (OpenAI)、文心一言 (Baidu)、Bard (Google)、Bing (Microsoft)、Stable Chat (Stability AI) のような大規模言語モデルを用いた生成 AI によるサービスが注目を集めています。
それに伴い、大規模言語モデルを用いて、社内文書などの外部知識を適切に扱うための枠組みについてもいくつか提案されています。
例えば、API のような外部ツールと連携を図る Toolformer や、推論時に言語モデルによる外部知識の参照を可能にする LlamaIndex (GPT Index) や LangChain などが挙げられます。
さらには、様々な形式の外部知識を読み込むためのデータローダに関するコンペティション Chat Your Data Challenge も直近で開催されていました。
内部環境 (Weakness)
弊社には 「Web サイトをクローリングし、必要なデータを抽出することで、組織の意思決定を支援する Web スクレイピングサービス」として ShtockData というものがあります。
ShtockData の基盤となるクローラについては、高精度な情報抽出が可能であるという特徴に加えて、スケジュール設定機能、BI ツールによるレポート機能、通知機能、画像取得機能など、コスト・拡張性の側面から見ても魅力的な特徴が多く挙げられます。
しかし弊社クローラを含む一般的なクローラ技術は、ページ構造を理解した上でセレクタを指定するため、ページ構造が統一されていない大規模なサイト集合に対する情報抽出を苦手としています。
AI を用いた情報抽出
そこで事前にページ構造が分からない場合でも情報抽出を可能にすることを目的として、弊社では AI を用いた情報抽出の開発を行なっていこうというプロジェクトが立ち上がっています。
本記事では、その活動を推進するための第一歩として、オープンドメイン質問応答技術を用いた情報抽出について紹介します。
抽出結果を提示する前に、本記事で対象とするオープンドメイン質問応答について簡単に説明した後、LangChain を用いた AI による情報抽出について紹介します。
オープンドメイン質問応答
オープンドメイン質問応答とは、特定の知識源を指定せずに与えられたファクトイド型(解答が一意に定まる)質問に回答する質問応答タスクです。
本タスクの入出力は以下の通りです:
-
[Input] 質問(”電話番号” といったユーザが欲しい情報のクエリ)
[Output] 質問に対する回答(”03-6384-5911″ といったクエリに対応する情報)
BERT のような言語モデルが登場して以来、一般的に ①質問に関連する文書を任意の知識集合から検索し ②検索結果の関連文書に基づいて抽出型質問応答モデルが質問に回答する、という二段階のアプローチが採用されています(Karpukhin+’20)。

https://github.com/cl-tohoku/AIO2_DPR_baseline より引用
この二段階推論をベースに、retrieval-augmented(Lewis+’20; Izcard+’22)や複数の観点に基づく対照学習(Zhang+’22; Hong+’22)、教師なし学習(Izcard+’21; Xu+’22)、ベクトル表現の圧縮化(Izcard+’20; Yamada+’21)、など様々な手法が提案されています。
近年では、抽出型に対して生成型の質問応答モデルが広く使用されており(Luo+’22)、Fusion-in-Decoder や InstructGPT のようなモデルが使用されています(Jong+’22; Izcard+’22; Yu+’23; Sun+’23)。
ここまでの話はテキストが対象としていますが、外部知識の参照が必要な視覚情報に対する質問応答タスク(Outside Knowledge Visual Question Answering)についても、下図のように画像の説明文をテキストで記述して GPT-3 のような大規模言語モデルで推論する枠組みが提案されており(Yang+’22; Gao+’22; Gui+’22; )、WebQA のベースラインの一つとしても使用されています。
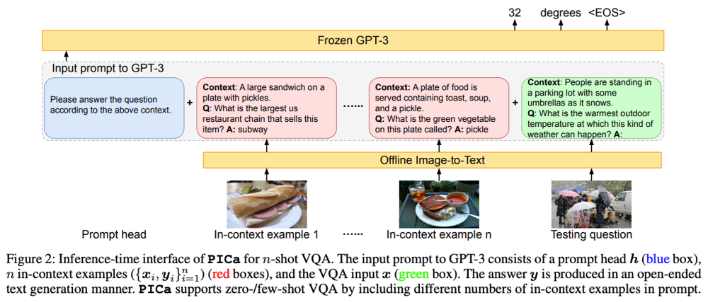
Yang+’22 – An Empirical Study of GPT-3 for Few-Shot Knowledge-Based VQA (AAAI)
LlamaIndex (GPT Index) や LangChain では、PDF, PowerPoint, YouTube, Slack, Notion, Google Documents など様々なデータ形式を読み込むためのデータローダが定義されていますが、上画像の PICa と同様に、これら様々なデータをテキストとして記述することで GPT-3 等の言語モデルによる推論を行っています (参考:Llama Hub)。
LangChain を用いた質問応答
LangChain は外部知識との連携を容易にすることで、大規模言語モデルを用いた質問応答やチャットボットなどのアプリケーション開発を支援することを目的とした Python ライブラリです。
本記事では、ユーザが欲しい情報(クエリ)に対する情報抽出を、①任意の WEB ページからクエリに関連する文章を検索、②検索した関連文章に基づいてクエリに対応する情報を出力する、というオープンドメイン質問応答タスクに落とし込んでいます。
LangChain では Agents と呼ばれるエージェントが定義されており、それぞれ ReAct や Self-Ask という枠組みが実装されています。
ReAct は「推論」フェーズと「行動」フェーズの両者を駆使して言語タスクに取り組みます。
「推論」フェーズにおいては Chain of Thought と呼ばれる推論過程を誘導するプロンプトを用いています。以下の few-shot の設定(解答例をいくつか提示する設定)では、単に解答を出力させるのではなく、文脈情報の状態と、状態に基づく演算過程も同時に出力するよう誘導しています。
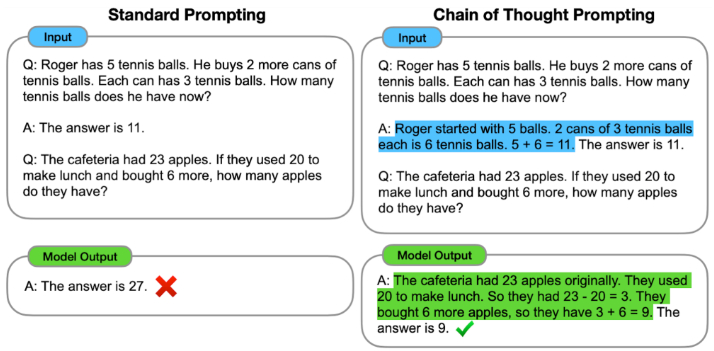
https://ai.googleblog.com/2022/05/language-models-perform-reasoning-via.html
モデルの内部的な推論に依存させずに知識の更新などを柔軟に行うために、「行動」フェーズでは事前に Tools として提示された選択肢からエージェントが実行する行動を選択します。
具体的には SerpApi (Google Search API) や NewsAPI 等の呼び出しや、優れた計算能力を持つ言語モデルの使用などが挙げられます。
ここで ReAct による実際の推論過程を見てみましょう。
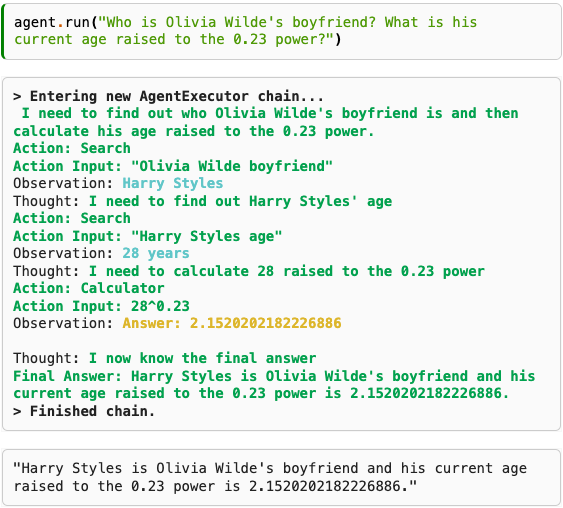
Wei+’22 – Chain-of-Thought Prompting Elicits Reasoning in Large Language Models (NeurIPS)
上の例では「Olivia Wilde の彼氏は誰?彼の現在の年齢を 0.23乗 にすると何?」という問いかけをモデルにしています。
ReAct では、この質問に対して以下のような推論を行います。
-
(思考) Olivia Wilde の彼氏が誰なのかを調べて、0.23乗の年齢を計算する必要があります。
(行動) Olivia Wilde の彼氏を検索
(行動結果)Harry Styles
(思考) Harry Styles の年齢を調べる必要がある (行動) Harry Styles の年齢を検索 (行動結果)28 歳
(思考) 28 の 0.23乗 を 計算する必要がある (行動) 28^0.23 を計算 (行動結果)2.1520202182226886
(思考) 私は今、最終的な答えを知っている (回答) Harry Styles は Oivia Wilde の彼氏で、現在の年齢を 0.23 乗すると 2.15202182226886 になる。
ここでは LangChain で実装されている ReAct の例を説明しました。
LangChain には他にも様々な実装がされており、本記事ではその一つであるオープンドメイン質問応答における二段階推論を利用しました。
質問応答(情報抽出)アーキテクチャ
前処理
Web ページの取得と前処理として、beautifulsoup4 を用いて不要なタグ情報等を除去したのち、html2text でマークダウン言語に変換しました。
質問応答モデル
前述したオープンドメイン質問応答を行うため、本記事では、①クエリに対する関連文書の検索 ②関連文書に基づいた生成モデルによる回答生成、の二段階推論を採用します。
- クエリに対する関連文書の検索モデルとして、OpenAI の
text-embedding-ada-002を使用しました。 - 関連文書に基づいた質問応答モデルとして、OpenAI の
text-davince-003を使用しました。
なお LangChain では、OpenAI の text-embedding に加え、100 以上の多言語埋め込み表現を提供する cohere 、transformers のモデルなどを使用するための Embeddings モジュールが提供されています。
また Embeddings モジュール同様、LangChain では様々な LLM モジュールが提供されています。
インターフェース
FastAPI を用いて、curl で呼び出しを行なっています。
任意ページに対する推論
抽出元のページは、2023.02.20 現在の 弊社の採用ページ としました。
クエリは以下の通りです。
- 修士卒データサイエンティストの初任給はいくら?(A. 27万円)
- 社会保険を列挙してください(A. 健康保険、厚生年金、雇用保険、労災保険)
- データサイエンティストの有給休暇は何日?(A. 10日)
- データサイエンティストの所定労働時間は一日あたり何時間?(A. 7時間45分)
この ①抽出元のページリンク ②クエリ集合、をモデル入力として、クエリパラメータに指定しています。
クエリに対応する採用ページの領域は以下のようになっています。

LangChain の MapRerankDocumentsChain を用いた推論結果
今回のタスクは関連文章集合に対する情報抽出で、マルチホップ推論の必要がないため、各文章ごとに独立して LLM モジュールを呼び出す Map-Rerank を使用しました。
実際の抽出結果は以下の通りです。
{
"url": "https://recruit.keywalker.co.jp/",
"qas": [
{
# 正解
"question": "修士卒データサイエンティストの初任給はいくら?",
"answer": "27万円",
"score": 100,
"reference": "auによるデータの可視化など\n\n【取り扱うデータ一例】 \n商品データ/店舗データ/企業情報/求人情報/不動産情報/ニュース/テレビ番組/SNS/口コミ/Webアナリティクス/人口統計データ\n\n### 勤務条件\n\n月給 | 学部卒 25万円 \n修士課程修了 27万円 \n※月給のうち、1ヶ月25時間分の時間外勤務手当40,875〜44,125円を含む \n \n---|--- \n賞与 "
},
{
# 正解
"question": "社会保険を列挙してください",
"answer": "健康保険、厚生年金、雇用保険、労災保険",
"score": 100,
"reference": "険 | 健康保険、厚生年金、雇用保険、労災保険 \n近距離住宅手当 | 月3万円(会社の近距離に住居を借りた場合) \n所定労働時間 | 7時間45分 \n休日休暇 | 完全週休二日制 \n土曜 日曜 祝日 \n夏季、年末年始休暇 \nバースデイ休暇 \n有給休暇 | 入社日に10日付与 \n \n### コンサルティング営業\n\n### 仕事の内容\n\nクライアントの課題をヒ"
},
{
# 正解(不要な文字列を含む)
"question": "データサイエンティストの有給休暇は何日?",
"answer": "入社日に10日付与",
"score": 100,
"reference": "険 | 健康保険、厚生年金、雇用保険、労災保険 \n近距離住宅手当 | 月3万円(会社の近距離に住居を借りた場合) \n所定労働時間 | 7時間45分 \n休日休暇 | 完全週休二日制 \n土曜 日曜 祝日 \n夏季、年末年始休暇 \nバースデイ休暇 \n有給休暇 | 入社日に10日付与 \n \n### コンサルティング営業\n\n### 仕事の内容\n\nクライアントの課題をヒ"
},
{
# 不正解(正解は「7時間45分」)
"question": "データサイエンティストの所定労働時間は一日あたり何時間?",
"answer": "所定労働時間は1日8時間です。",
"score": 100,
"reference": "auによるデータの可視化など\n\n【取り扱うデータ一例】 \n商品データ/店舗データ/企業情報/求人情報/不動産情報/ニュース/テレビ番組/SNS/口コミ/Webアナリティクス/人口統計データ\n\n### 勤務条件\n\n月給 | 学部卒 25万円 \n修士課程修了 27万円 \n※月給のうち、1ヶ月25時間分の時間外勤務手当40,875〜44,125円を含む \n \n---|--- \n賞与 "
}
],
}
クロール結果を構造化データとして提供するためには後処理が必要になりそうですが、質問応答の性能としてはある程度の期待が持てそうです。
最後の「所定労働時間」に関する質問については不正解で、参照した文章(reference)を見ても正解の「7時間45分」という文字列が含まれていないことが分かります。
今後の展望としては、生成モデルが文章中に含まれない単語列を生成した場合の後処理を行うとともに、検索モデルについても改良をしていくことが挙げられます。
LangChain の ReAct を用いた推論結果
ReAct を試してみたかったので、LangChain の zero-shot-react-description を使用して推論を行いました。
推論時には LlamaIndex (GPT Index) というツールを用いてクエリに関連する文章を検索できるようにしています。
{
"url": "https://recruit.keywalker.co.jp/",
"qas": [
{
# 正解(不要なトークン列を含む)
"question": "修士卒データサイエンティストの初任給はいくら?",
"answer": "修士卒データサイエンティストの初任給は27万円です。"
},
{
# 正解
"question": "社会保険を列挙してください",
"answer": "健康保険、厚生年金、雇用保険、労災保険"
},
{
# 不正解(正解は「7時間45分」)
"question": "データサイエンティストの所定労働時間は一日あたり何時間?",
"answer": "データサイエンティストは、一日あたり平均13時間39分の労働時間を持つと考えられます。"
},
{
# 不正解(正解は「10日」)
"question": "データサイエンティストの有給休暇は何日?",
"answer": "データサイエンティストの休暇日数は、企業の具体的な休暇規定によって異なります。"
}
]
}
抽出結果については一部のクエリで正解しているものの GPT-3 が内部知識を参照してしまい、指定した採用ページを正しく参照できていない結果となりました。
またモデルが反復的に改良を行うため、推論速度が 2 分程度と遅く、実務で使用するには改善の余地がありそうです。
LangChain の Self-Ask を用いた推論結果
LangChain の self-ask-with-search を使用して推論を行いました。
なお Self-Ask では、メインの質問に対する解答の情報が不足している場合に、追加の関連質問することで “Follow up” を行います。

Press+’22 – Measuring and Narrowing the Compositionality Gap in Language Models
抽出結果は、以下の通りです。
{
"url": "https://recruit.keywalker.co.jp/",
"qas": [
{
# 正解
"question": "修士卒データサイエンティストの初任給はいくら?",
"answer": "27万円"
},
{
# 正解(不要なトークン列を含む)
"question": "社会保険を列挙してください",
"answer": "健康保険、厚生年金、雇用保険、労災保険など"
},
{
# 不正解(正解は「7時間45分」)
"question": "データサイエンティストの所定労働時間は一日あたり何時間?",
"answer": "未指定"
},
{
# 正解
"question": "データサイエンティストの有給休暇は何日?",
"answer": "10日"
}
]
}
「社会保険を列挙してください」というクエリついて、モデルの出力が正解しているように思えます。
しかし中間生成物の内容をチェックしてみると、
-
Intermediate answer:
社会保険とは、企業や個人が健康保険、厚生年金、雇用保険、労災保険などの社会保険に加入し、損害や災害などの病気などの生活保護を行うものです。
Follow up: 上記の社会保険を列挙してください
Intermediate answer:
健康保険、厚生年金、雇用保険、労災保険などがあります。
So the final answer is: 健康保険、厚生年金、雇用保険、労災保険など
と、社会保険についての Follow up において、社会保険の参照対象が誤っていることが分かります。
MapRerankDocumentsChain で提示した検索結果を含め、こうした推論過程は回答の根拠となりうるため、ユーザに提示すべき重要な情報となります。
また推論速度においては 5 分ほど時間がかかってしまい、実務で使用する場合には改善の余地がありそうです。
おわりに
本記事では LangChain を用いて任意の Web ページからデータ抽出を行いました。
実際に推論してみたところ、ベースラインの抽出性能としては期待できそうな一方で、まだまだ改善の余地がありそうな結果となりました。
また今回は単純なページ構造を対象にしていたため、抽出の難易度がそもそも低かった可能性があります。 今後は様々な改良を行うとともに、多様なページに対して適切な定量評価を行っていきたいと思います。
また GPT-4 の公開が予定される中、我々の仕事が奪われてしまうのではないかといった懸念がよく議論されますが、少なくとも GPT-4 公開前の現状としては、完全に互換される可能性は高くないと感じました。
生成モデルを使用している以上、抽出誤りが許容されない分野では、言語モデルが生成した解答の根拠を提示し、最終的に人が判断を下すような仕組みづくりが必要になると改めて感じました。
将来の展望
- 前処理の際に HTML をマークダウン言語に変換したのち単語長によってチャンク分割を行いましたが、Pix2Struct や MarkupLM で使用されているような前処理およびサブツリーを考慮したチャンク分割方法も検討していきます。
- Hallucination 関連についても勉強しつつ対策を講じていこうと思います。
- より効率的な推論を行うため、batch prompting なども検討していきたいです。
- LangChain ではモデルやプロンプトのカスタマイズが可能であるため、自作した検索・質問応答モデルの運用も取り入れたいと思います。
- モデルのアーキテクチャ上、抽出型質問応答モデルの方が特定ドメインに対して頑健である可能性について、第3回AI王でも議論されていましたが、今後も抽出型質問応答との併用も検討していくつもりです。個人的には Fusion-in-Decoder 推しなので FiDO なども検討していきたいです。
- 本記事では任意の Web ページを対象にしましたが、PDF やその他のデータ形式についても同様に有効性を検証していこうと思います。
参考
- Morris+’22 – A Brief Survey of Text Retrieval in 2022
- AI王 ~ クイズAI日本一決定戦 第三回最終報告会
- 浅井+’22 – より多くの言語での情報検索・質問応答実現のために(招待公演:AI王 ~ クイズAI日本一決定戦 第三回最終報告会)
- AI王 ~ クイズAI日本一決定戦 第二回最終報告会
- 加藤 and 宮脇+’22 – DPR ベースラインによるオープンドメイン質問応答の取り組み(第二回AI王最終報告会)
- 山田+’21 – オープンドメイン質問応答技術の最新動向(招待講演:言語処理学会年次大会(NLP2021)ワークショップ「AI王 ~ クイズAI日本一決定戦」)
- ACL2020 Tutorial: Open-Domain Question Answering
- 森羅 2023 最終報告会
- AI王 ~ クイズAI日本一決定戦 第3回最終報告会
- Rajani+’23 – What Makes a Dialog Agent Useful? (Huggingface Blog)
- Wei and Zhou+’22 – Language Models Perform Reasoning via Chain of Thought (Google Research Blog)
- Yao and Cao+’22 – ReAct: Synergizing Reasoning and Acting in Language Models (Google Research Blog)
解説記事ほか
- oshizo+’23 – gpt-index(0.2.5)をOpenAI APIなし&日本語で動かす (note)
- Ryo+’23 – 【Prompt Engineering】LLMを効率的に動かす「ReAct」論文徹底分解! (Zenn)
- npaka+’23 – GPT Index の使用方法 (note)
- npaka+’22 – LLM連携アプリの開発を支援するライブラリ LangChain の使い方 (1) – LLMとプロンプト・チェーン (note)
- らむね+’23 – GPT indexの仕組みを理解する (note)
- メガゴリラ+’23 – LangChainのチュートリアルメモ
- @Ssk1029Takashi+’23 – GPT-3を使って根拠付きで正確に質問応答してくれるシステムを作ってみる (Acroquest Technology)
著者:宮脇峻平(データサイエンス部) [プロフィール]
最終更新日: 2023.02.16
