はじめに
SIGNATEの 【練習問題】お弁当の需要予測 をDataikuで実施しました。
本記事では、Dataikuを用いてノーコードで回帰分析を行う手順について解説します。
概要
曜日やメニュー等の複数の情報からお弁当の需要予測をします。
使用データ
使用するデータは、以下の2種類です。(ダウンロードはこちら)
学習用データ(train.csv)
評価用データ(test.csv)
評価指標
本コンペティションでは RMSE(Root Mean Squared Error) を指標としてモデルの制度を評価します
RMSEとは?
予測値と実際の値のズレを測る指標です。誤差を二乗して平均を取り、平方根を求めることで、大きな誤差を強調しつつ全体の誤差を表します。値が小さいほど精度が高いです。

投稿方法
提出するファイルは、以下の形式の csv(ヘッダなし) で作成します。
1列目に日付(yyyy-m-d)、2列目に販売数を記載し、SIGNATE上で投稿します。
| 日付 | 販売数 |
| 2012-2-3 | 1928 |
| 2013-1-2 | 2784 |
| … | … |
使用レシピ一覧
今回のプロジェクトでは、以下のレシピを使用しました。
Visual recipes(データ処理)
Stack:複数のデータセットをユニオン
Prepare:様々な前処理を実施
Parse to standard date format:日付型を指定した形式に変換
Create if, then, else statements:条件分岐の式を作成
Unfold:ダミー変数化
Fill empty cells with fixed value:欠損値を特定の値で補間
Format date with custom format:指定した日付形式に変換
Split:1つのデータセットを複数データセットに分割
Lab(機械学習)
AutoML Prediction:機械学習モデルを自動構築
Other recipes(その他)
Score:学習済みモデルを用いて予測データのスコアリング
ハンズオン
データ確認
統計データの確認
trainをダブルクリックして、右上のStatisticsタブをクリックします。- Automatically suggest analysesのUnivariate analysis on all variablesを選択して、グラフを作成します。
- 作成したグラフを確認してみましょう。
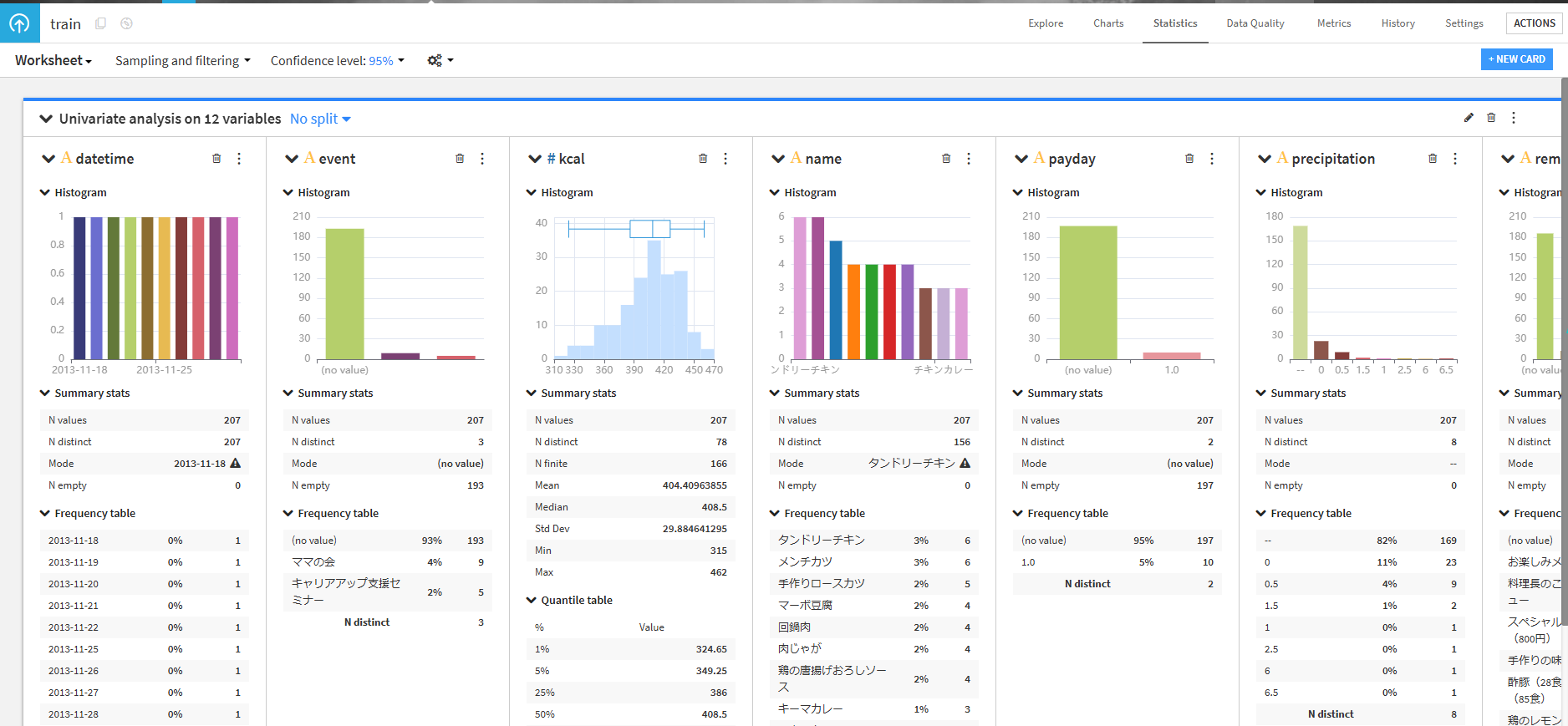

いくつかの列で欠損値が確認できました。
week を見てみると、月から金までしか曜日がないようです。
詳細分析
下記のグラフを作成し、どのような傾向があるか確認しましょう。また、ご自身で気になるデータを分析してみましょう。
- 売上の時系列グラフ
- 曜日や天気、特記事項毎の箱ひげ図
- 売上とその他の数値データとの相関図
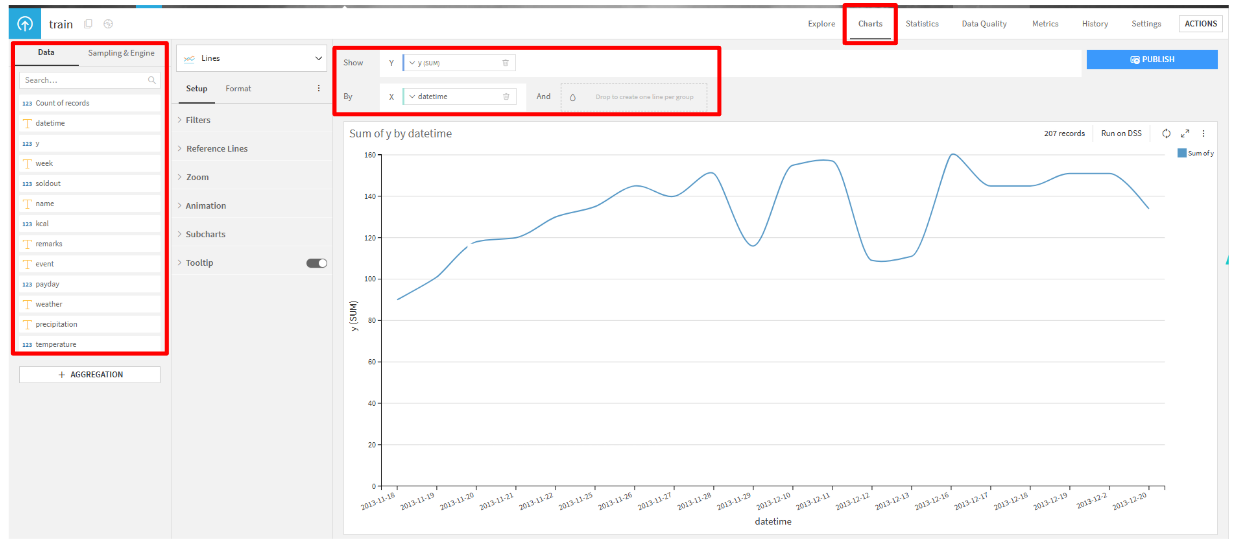
グラフ作成方法(売上の時系列グラフ)
trainをダブルクリックして、画面右上のChartsタブをクリックします。- YやXに左側のDataの項目からドラッグ&ドロップします。

おまけ:BIツールTableauを用いて、ダッシュボードを作成してみました。(ダッシュボードはこちら)

ユニオン(前処理を1回にするため)
trainとtestをユニオンします。
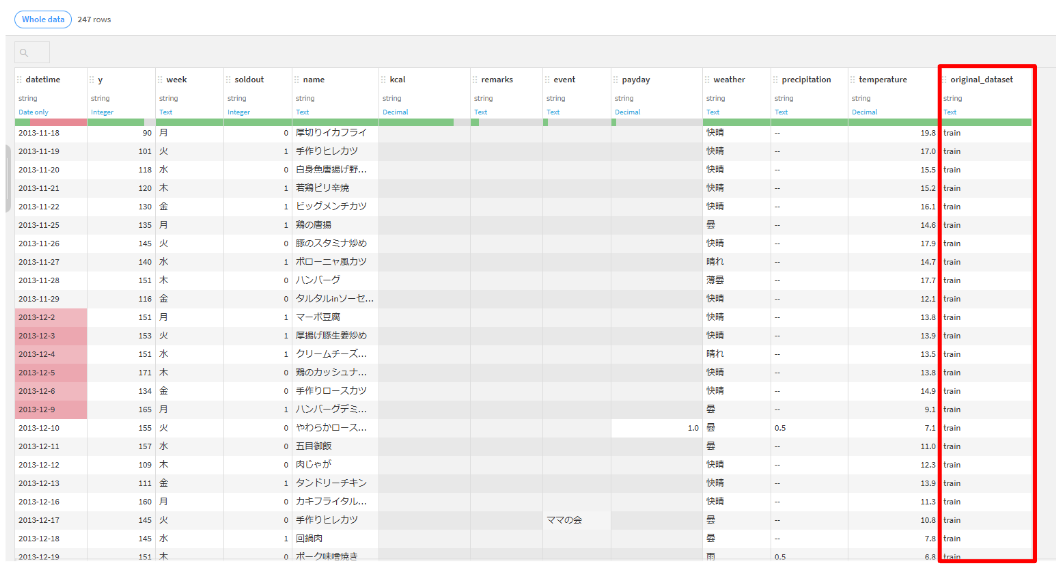
trainを選択して、Visual recipesのStackをクリックします。- Inputsに
trainとtestを選択して、レシピを実行します。 - Origin columnsタブをクリックして、設定を「On」に変更して実行します。

前処理
train_stackedを、Visual recipesのPrepareを用いて前処理を行っていきます。
データ型の変換
datetime
- ADD A NEW STEPから、
Parse to standard date formatを選択してデータ型を変換します。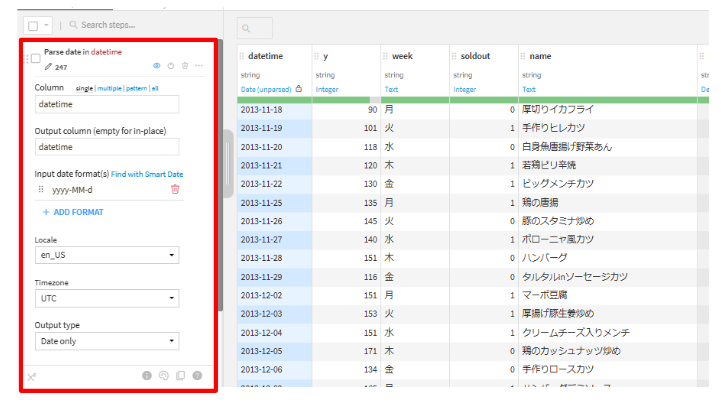

ダミー変数化
詳細分析の結果、remarksに’お楽しみメニュー’がある場合に売上が高かったので、’お楽しみメニュー’のダミー変数化をしていきます。また、nameを見てみるといくつかグループ化できそうな値もあるのでそちらも対応していきます。
ダミー変数化とは?
カテゴリデータを機械学習モデルが扱える数値データに変換する方法です。
| 定食 |
|---|
| 焼き魚 |
| ハンバーグ |
| 唐揚げ |
各カテゴリ毎に列を作成して、該当する行にフラグ(1)を入力します。
| 焼き魚 | ハンバーグ | 唐揚げ |
|---|---|---|
| 1 | 0 | 0 |
| 0 | 1 | 0 |
| 0 | 0 | 1 |
ダミー変数化を行う理由
- ほとんどのモデルはカテゴリデータをそのまま入力できないため
- 数値の大小による影響を防ぐため
- 例えば、
焼き魚=1, ハンバーグ=2, 唐揚げ=3のように数値を割り当てると、モデルが「ハンバーグ(2)は 焼き魚(1)より大きい」など誤った関係を学習してしまう。
- 例えば、
remarks
- ADD A NEW STEPから、
Formulaを選択します。(列名:fun_flg)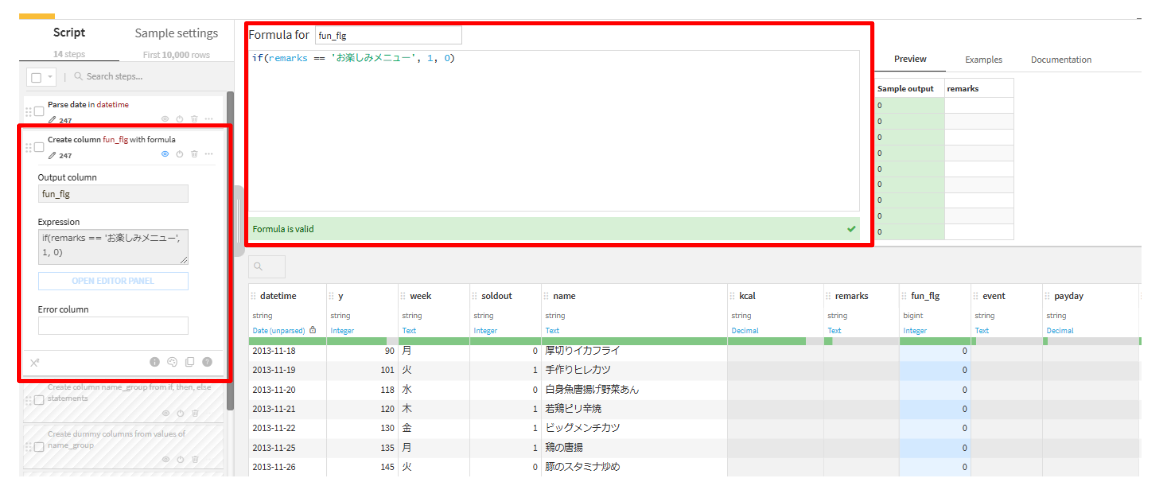

name
Create if, then, else statementsを追加します。(列名:name_group)
if(name contains カレー) Then (name_group = カレ) Else if (name contains カツ) Then (name_group = カツ) Else if (name contains 唐揚) Then (name_group = 唐揚) Else if (name contains ハンバーグ) Then (name_group = ハンバーグ) Else if (name contains チキン) Then (name_group = チキン) Else (name_group = その他)
Unfoldで、ダミー変数化をします。(name_group_)
Fill empty cells with fixed valueで、欠損値を0で補完します。Columns multiple:name_group_その他, name_group_カツ, name_group_カレー, name_group_チキン, name_group_ハンバーグ, name_group_唐揚 Value to fill with:0

event、payday
Formula で、ダミー変数化します。
event_flg

payday

week
nameと同じ要領で、ダミー変数化していきます。
Unfold(week_)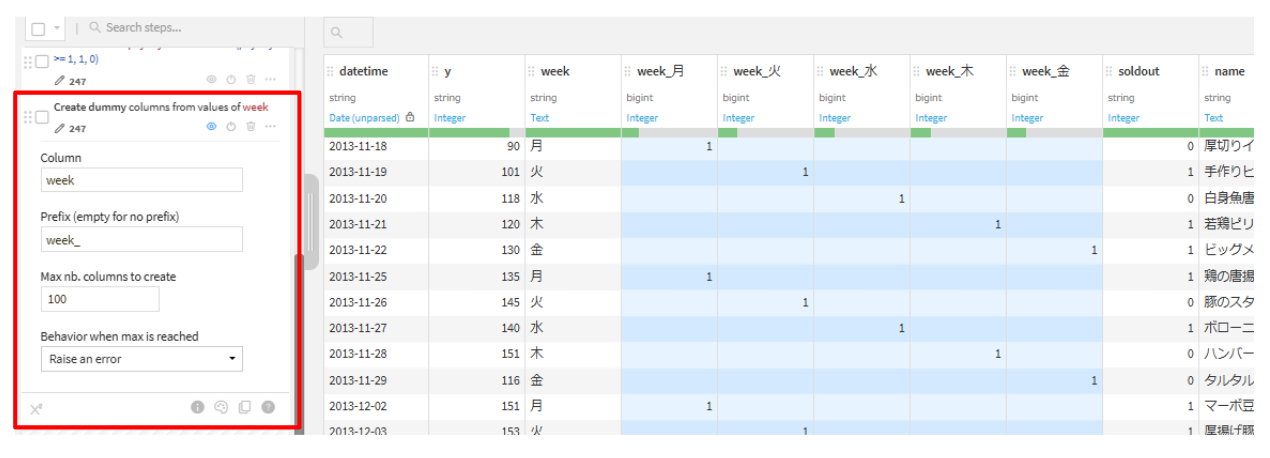
Fill empty cells with fixed value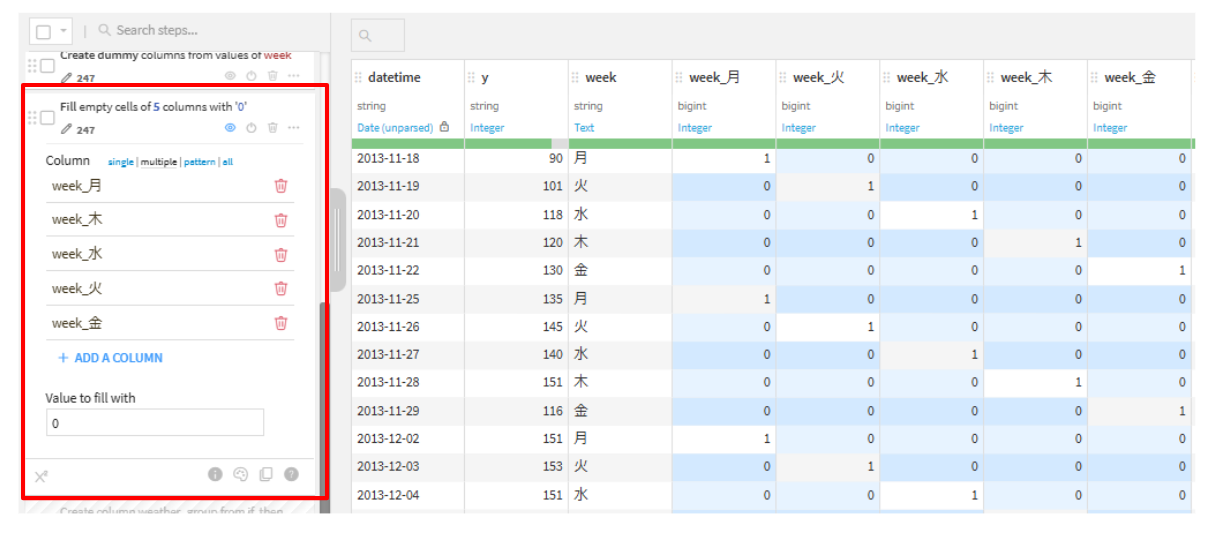


weather
こちらも同様です。
Create if, then, else statements(列名:weather_group)
if(weather contains 晴)
Unfold(weather_group_)Fill empty cells with fixed value
Columns multiple:weather_group_晴, weather_group_雲, weather_group_悪天候
Then (weather_group = 晴) Else if (weather contains 雲)
Then (weather_group = 雲)
ELSE (weather_group = 悪天候)


Value to fill with:0

欠損値埋め
欠損値を補完する理由
- モデルがデータを適切に処理できるようにするため
- バイアス(偏り)を防ぐため
kcal
- 空の値をクリックします。
Fill empty rows with…をクリックします。- Averageを選択します。

値の置換
precipitationの’—’(半角’-’が2つ)を数値型に変換します。
- ADD A NEW STEPから、
Find and replaceを選択して置換します。
Column:precipitation
Output column(empty for in-place)
Replacements:— → -1

これで前処理は終了です。

ユニオンデータの分割
ユニオンしたデータをtrainとtestに分割します。
- Visual recipesの
splitを選択します。 - Outputに
train_splitとtest_splitを作成して、レシピを作成します。 - Splittingタブで分割する列(
original_dataset)を指定します。
| Value | Output |
|---|---|
| train | train_split |
| Other values | test_split |
学習
いよいよモデル構築に移っていきたいと思います。
train_splitを選択して、LABのVisual MLから、AutoML Predictionをクリックします。- 目的変数に
yを設定して、Quick Prototypesを選択したらモデルを構築します。
trainデータのサンプリング(Basic)
- BASICの「Train/Test Set」タブをクリックします。
- Sampling & SplittingのK-fold cross-testにチェックを入れます。
K-fold cross-testとは?
データをK個に分割し、そのうち1つをテストデータ、残りを学習データとして使用します。このプロセスを、すべてのグループが一度ずつテストデータとなるようにK回繰り返し、それらの結果の平均を最終的な評価指標とする方法です。

K-fold cross-testを行う理由
- データが少ない場合でもバランスよく使用できるため
- データの分割による偏りを減らすため
- 過学習の防止
- 異なるデータパターンで繰り返し評価することで、モデルが特定のデータに依存しすぎるのを防ぐ。
評価指標の設定(Metrics)
ハイパーパラメータを今回の評価指標であるRoot Mean Square Errorに変更します。
説明変数の設定(FEATURES)
-
- FEATURESの「Features handling」タブをクリックします。
- ダミー変数化する際に使用した下記の項目を削除します。
アルゴリズムの選定(MODELING)
今回はLasso Regressionを選択します。
Lasso Regressionとは?
最小二乗法に正則化(過学習を防ぐための手法)を加え、不要な説明変数の回帰係数をゼロにする方法です。これによりモデルが重要な特徴量に焦点を当て、シンプルで解釈しやすいモデルになります。
以上で、設定は完了したので「TRAIN」をクリックします。
モデルの評価(EXPLAINABILITY)
Feature importance
特徴量の重要度:temperatureやfun_flg(remarks=お楽しみメニュー) が予測に貢献している。

Feature effects
特徴量毎の影響:temperatureが低い方が売り上げが良い。

予測
デプロイした、Predict y (regression)を選択して、Apply model on data to predictからScoreをクリックします。
Inputでtest_splitを選択して、レシピを作成して予測値を確認します。

提出
- Visual recipesから
Prepareを選択します。 Delete/Keep columns by nameを選択して、提出に必要なカラムを選択します。datetime, prediction
Format date with custom formatを用いて指定された日付形式に変換して、実行します。Input column:datetime Date format:yyyy-MM-d Locale:en_US Default timezone:UTC Output column(empty for in-place):datetime
- 出力したデータセットを、csv形式(ヘッダなし)でダウンロードします。
- SIGNATEで、提出します。
結果
ここまでの手順通りにモデルを構築して提出した結果は、41.35でした。
この予測モデルで予測した場合、大体40個くらいはずれる可能性が有る、という理解ができます。ただし、RMSEの特徴として外れ値の影響を強く受けるため、特定の日の予測値のずれが非常に大きいと、RMSEはそれにつられて大きくなります。
また、そのずれが小さい方(欠品が発生する)にずれているのか、大きい方(廃棄が発生する)にずれているのかにも注意が必要です。
対策として、縦軸が予測値で横軸が実測値の散布図などをプロットし、本当に大きくずれているのか、大きい方小さい方どちらにずれているのかを確認することが有効です。

また、以下の改善策を行うことでRMSEを10.06まで改善することができました。
改善策
- 前処理の見直し
- 例えば、
nameのグループ化の方法を変更する
- 例えば、
- 新しい変数を作成する
weatherやprecipitation、temperature等を掛け合わせて新しい変数を作成する。
- 異なるモデルを使用する
まとめ
初回構築では良いモデルを作成することができませんでしたが、上記の改善策を実施することで精度を10.06まで向上させることができました。Dataikuは前処理やモデル構築が非常に簡単で、短時間で検証を行えるため、思いついた施策を次々と試すことができる点が大きなメリットだと感じました。
今回の記事を参考に、商品の売上や需要予測など、さまざまなシナリオでDataikuを活用して回帰分析を試してみてはいかがでしょうか。
