初めに
dltとはELTのExtractとLoadが可能なPythonライブラリで、CSVやJSONなどのファイルやREST API、SQLデータベースといった様々なデータソースから、PostgreSQLなどのデータベースやSnowflakeなどのDWHへデータを転送することが可能です。
今回は、dltの技術検証の一環で、OpenWeatherMapから取得したデータをdltを用いてDuckDBに格納してみます。
DuckDBとは
DuckDBとは、OLAP系の組み込み型データベースの一つです。
- OLAP:蓄積された大量のデータを高速に集計することが可能な、データ分析に適したデータベースの形式。対照的な形式は、トランザクションデータの高頻度な処理に適したOLTP。
- 組み込み型:アプリケーションの内部で動作し、別途サーバーを立ち上げる必要がない形式。
主なDuckDBの強み
- 手軽に使用できる
上でも触れましたが、サーバーを立ち上げる必要がないため環境構築の手間がかかりません。今回はPythonからDuckDBに接続し、処理を実行しました。
- 処理が高速
こちらも上でも触れましたが、OLAPデータベースのためデータ処理が非常に高速です。
- SQLに対応
既存のSQLに対応しているため、新しく言語を覚える必要がありません。
OpenWeahterMapの前準備
Sign inページからアカウントを作成し、My API keysを取得します。コードはこちらの”Built-in API request by city name”を基に実装しました。
import requests
import json
from pprint import pprint
url = "https://api.openweathermap.org/data/2.5/weather?q={city_name}&units=metric&appid={API_key}"
#都市名と取得したMy API keysを入力
url = url.format(city_name = "Tokyo", API_key = "My_API_keys")
jsondata = requests.get(url).json()
pprint(jsondata)
以下のように気温、湿度など様々な情報を取得できます。
{'base': 'stations',
'clouds': {'all': 20},
'cod': 200,
'coord': {'lat': 35.6895, 'lon': 139.6917},
'dt': 1740475634,
'id': 1850144,
'main': {'feels_like': 5.98,
'grnd_level': 1020,
'humidity': 58,
'pressure': 1022,
'sea_level': 1022,
'temp': 9.7,
'temp_max': 10.44,
'temp_min': 9.21},
'name': 'Tokyo',
'sys': {'country': 'JP',
'id': 268395,
'sunrise': 1740431819,
'sunset': 1740472324,
'type': 2},
'timezone': 32400,
'visibility': 10000,
'weather': [{'description': 'few clouds',
'icon': '02n',
'id': 801,
'main': 'Clouds'}],
'wind': {'deg': 180, 'speed': 9.26}}
パイプラインの作成と実行
パイプラインとはdltの構成要素で、データソースから目的のデータ基盤へデータを格納するために使用されます。
初めに、以下のパッケージをインストールします。
pip install "dlt[duckdb]"
次に、以下のコードを実行します。リクエストまでは前準備でのAPI実行とほぼ同じで、追加でデータを格納するパイプラインを設定します。今回はDuckDBにロードするのでdestination = ‘duckdb’とし、残り2つは任意の名前をつけます。最後にpipelin.run() を実行すると、DuckDBにデータがロードされます。
import dlt
from dlt.sources.helpers import requests
url = "https://api.openweathermap.org/data/2.5/weather?q={city_name}&units=metric&appid={API_key}"
#都市名と取得したMy API keysを入力
url = url.format(city_name = "Tokyo", API_key = "My_API_keys")
#リクエストを行う
response = requests.get(url)
#パイプラインの構成
pipeline = dlt.pipeline(
pipeline_name="weather_test",
destination="duckdb",
dataset_name="weather_data",
)
#実際のコードでは@を_に変えてください
load_info = pipeline.run([response.json()], table@name = "weather")
結果
以下のコマンドを実行すると、パイプラインによってロードしたテーブルの情報を見ることができます。
dlt pipeline weather_test show
実行するとStreamlitのアプリがブラウザ上で立ち上がり、作成されたデータセットを確認できます。前準備の時とカラム名が異なりますが、中身は問題なくロードできています。今回は東京、大阪、神戸で3回実行したため3行がロードされています。
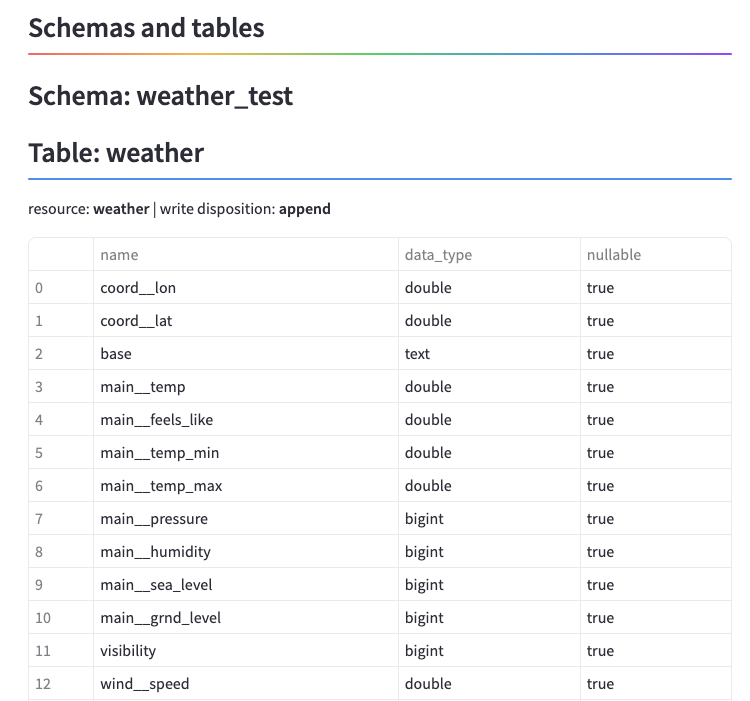
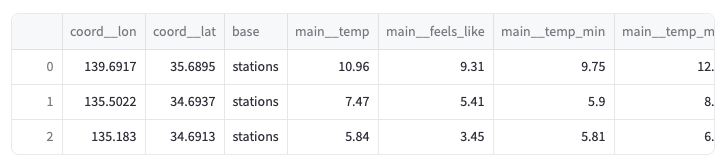
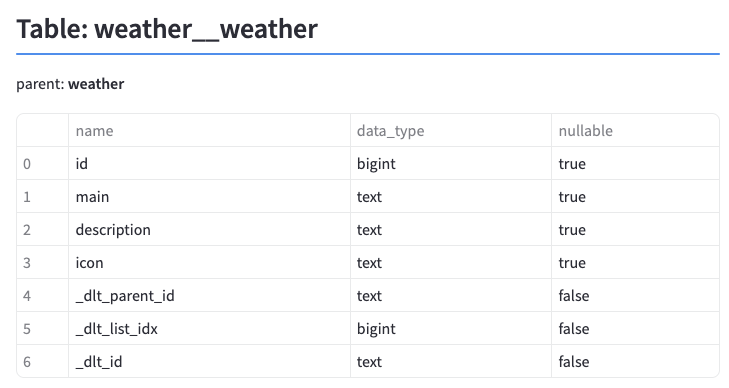
SQLの実行
DuckDB上のデータに対して簡単なSQLを実行してみます。Pythonでは以下のコードで実行可能です。
import duckdb
con = duckdb.connect("weather_test.duckdb")
rel = con.sql(
"""
select name,
main__temp_min as min_temp,
main__temp_max as max_temp
from weather_data.weather
where name <> 'Tokyo'
"""
)
rel.show()
con.close()
問題なく動作しています。
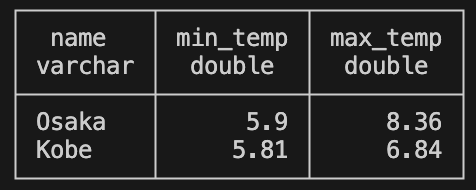
最後に
今回はOpenWeahterMapのAPIを実行し、取得したデータをdltを用いてDuckDBに格納しました。ローカルのDuckDBであれば、destinationを指定するだけで資格情報いらずで簡単に格納できることが分かりました。今後はSnowflakeやBigQueryなどにデータを格納し、それらとTableauを連携して可視化する方法も調査してみようと思います。
参考
