はじめに
SIGNATEの 【練習問題】Jリーグの観客動員数予測 をDataikuで実施しました。
本記事では、Dataikuを用いてノーコードで回帰分析を行う手順について解説します。
概要
J1とJ2の12/13から13/14シーズン前半戦までのデータを使用して、13/14シーズン後半戦の全試合観客動員数を予測するモデルを作成します。
使用データ
使用するデータは、以下の6種類です。(ダウンロードはこちら)
- 学習用試合データ(train.csv)
- 学習用試合追加データ(train_add.csv)
- 評価用試合データ(test.csv)
- スタジアムデータ(stadium.csv)
- 試合詳細データ(condition.csv)
- 試合詳細追加データ(condition_add)
評価指標
本コンペティションでは RMSE(Root Mean Squared Error) を指標としてモデルの制度を評価します
RMSEとは?
予測値と実際の値のズレを測る指標です。誤差を二乗して平均を取り、平方根を求めることで、大きな誤差を強調しつつ全体の誤差を表します。値が小さいほど精度が高いです。

投稿方法
提出するファイルは、以下の形式の csv(ヘッダなし) で作成します。
1列目にid、2列目に観客動員数を記載し、SIGNATE上で投稿します。
| id | 観客動員数 |
| 1 | 1928 |
| 2 | 2784 |
| … | … |
使用レシピ一覧
Visual recipes(データ処理)
- Stack:複数のデータセットをユニオン
- Join:複数のデータセットを結合
- Prepare:様々な前処理を実施
- Extract with regular expression:指定した区切り文字で抜き出し
- tokenize text:適当な値で区切り、それぞれ列を生成
- Rename columns:列名の修正
- Formula:計算式を記載することで様々な処理が可能
- Find and replace:指定した値を別の値に置換
- Filter rows/cells with formula:指定した値でフィルター
- Unfold:one-hot encoding(ダミー変数化)
- Fill empty cells with fixed value:欠損値を特定の値で補間
- Delete/Keep columns by name:不要列の削除
Lab(機械学習)
- AutoML Prediction:機械学習モデルを自動構築
Other recipes(その他)
- Score:学習済みモデルを用いて予測データのスコアリング
ハンズオン

ユニオン
trainとtrain_add、conditionとcondition_addをユニオンします。

train(及びconditon)を選択して、Visual recipesのStackをクリックします。- Inputsに
train_add(及びcondition_add)を加えて、レシピを作成します。(Output名:train_stacked(及びcondition_stacked)
結合
train_stackedとtestに対して、condition_stackedやstadiumを結合していきます。

train_stacked(及びtest) を選択して、Visual recipesのJoinをクリックします。- Inputsに
condition_stackedを加えて、レシピを作成します。(Output名:train_joined) - Joinタブで、
train_stackedの右側にある「+」を選択して、stadiumを選択します。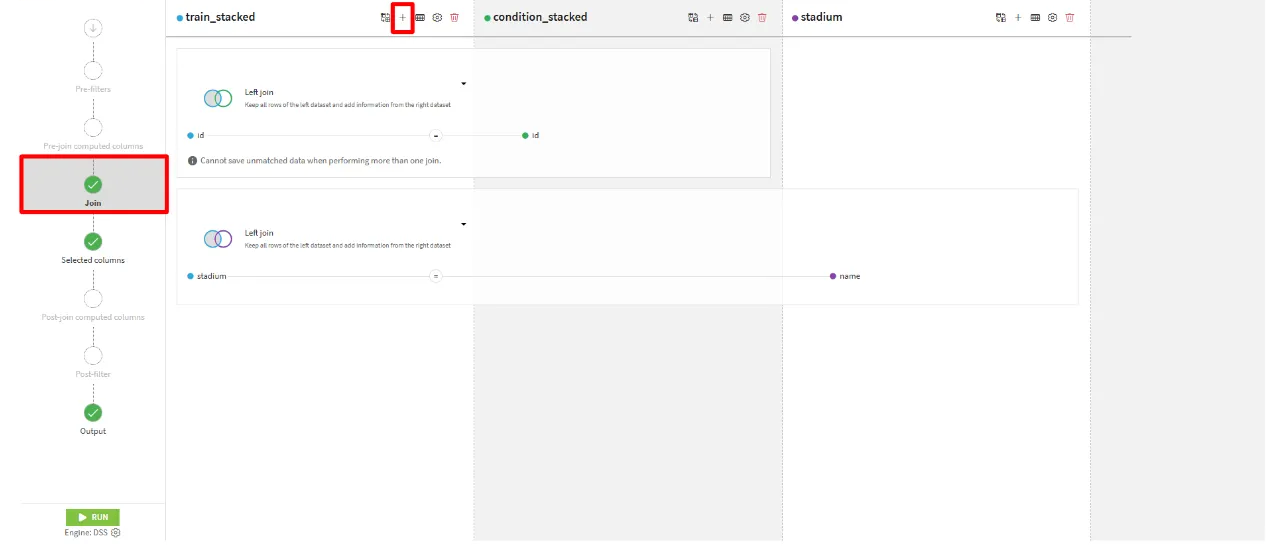
- Selected columnsタブで、各データセットに対して不要な列のチェックを外して、実行します。(今回は、分析しやすい特徴量のみ残すため、選手やレフェリーの情報を削除します。)
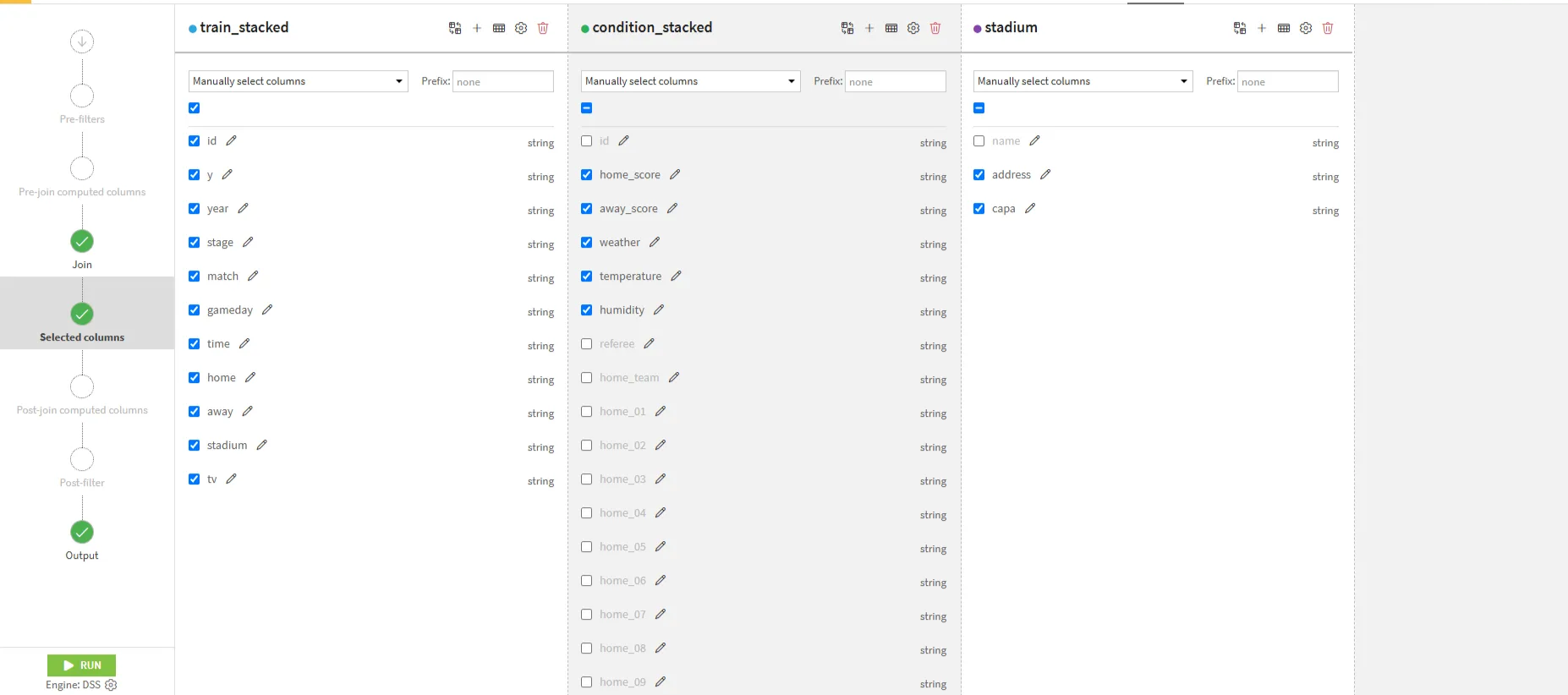
testでも同様の処理を行います。(Output名:test_joined)


前処理
match列の第1節などの値を分析しやすい形式に変換します。

train_joinedを選択して、Visual recipesのprepareを選択してレシピを作成します。(Output名:train_joined_prepared)- 以下の処理をそれぞれ実装したら、実行します。(testも同様)
開催節の取り出し
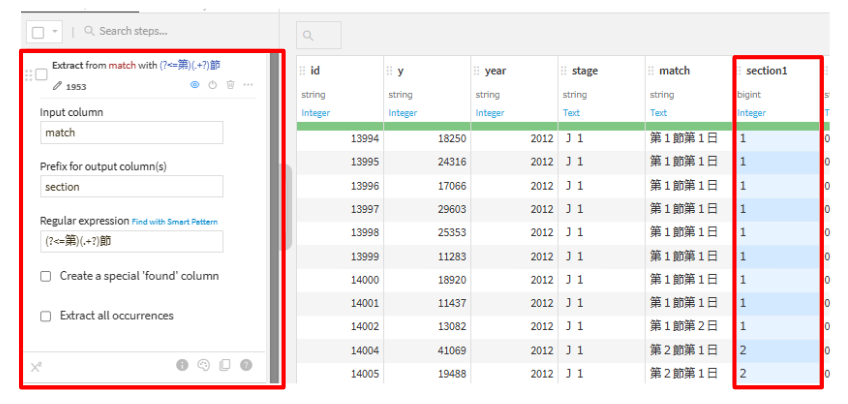
- 「ADD A NEW STEP」から
Extract with regular expressionを選択して、以下の実装を行います。Input column:match
Prefix for output columns(s):section
Regular expression:(?<=第)(.+?)節
- データ型をStringに変更します。

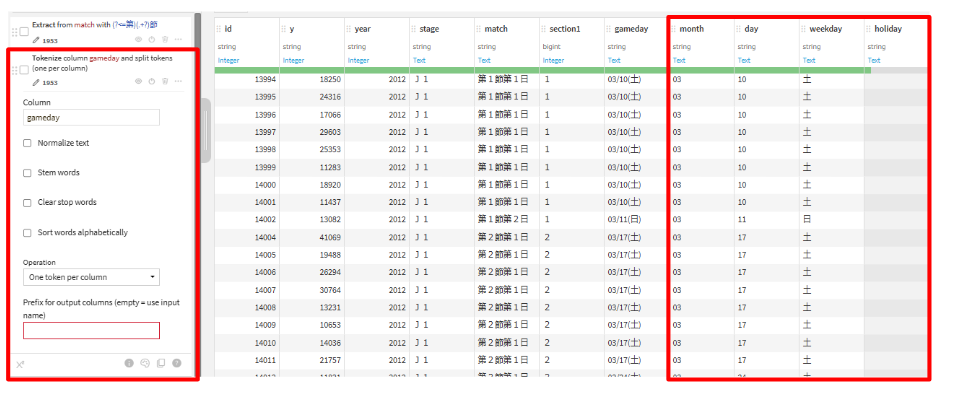
月や曜日の取り出し
tokenize textを選択して、以下の実装を行います。Rename columnsで、列名の修正を行います
Column:gameday
Operation:One token per column
| gameday_0 | month |
| gameday_1 | day |
| gameday_2 | weekday |
| gameday_3 | holiday |
時間の取り出し

Formula
Output column:hour Expression:split(time, ":")[0]

サービス数をカウント
Formula
Output column:num_tv Expression:length(split(tv, '/'))

%の抜き出し
Find and replace
Column:humdity Output columns(empty for in-place):humidity Replacements:%→ (何も入力しない)

統計分析
train_joined_preparedを選択して、Statisticsタブをクリックします。- 「CREATE YOUR FIRST WORKSHEET」をクリックして、Automatically suggest analysesを選択します。
- Univariate analysis on all variablesとCorrelation matrix on the top 10 nu…を選択して、欠損値や相関行列を確認します。
Univariate analysis on all variables

Correlation matrix on the top 10 nu…

相関行列とは?
相関行列とは、複数のデータ(変数)同士の関係の強さを示す表のことです。 各要素は相関係数という数値で表され、-1から1の範囲をとります。 値が大きいほど変数同士の関係が強いことを意味します。| 1に近い値 | 強い正の関係(片方が増えるともう片方も増える) |
| 0に近い値 | 無関係 |
| -1に近い | 強い負の関係(片方が増えるともう片方が減る) |

分析結果
- 欠損値が、holidayのみ(祝日フラグ)
- y(観客動員数)のMinが0(無観客試合だったようなのでデータから削除します。)
- capaの相関が高い
- 気温や湿度などの相関が低い
Prepareのレシピに戻って、yが0のレコードを削除します。(Filter rows/cells with formula )

データの可視化
次は、データの可視化をして詳細分析をします。 以下の項目以外にも気になるデータを可視化してみましょう!| 可視化項目 | 予想 |
|---|---|
| stageとy | J1とJ2での観客動員数の差異がありそう |
| capaとy | 収容人数が多いと観客動員数が多そう |
| sectionとy | シーズン後半のほうが盛り上がりそう |
train_joined_preparedを選択して、Chartタブをクリックします。- 左のDataから、可視化したい項目をYとXにドラッグ&ドロップします。

おまけ
Tableau Publicでダッシュボード化してみました(URLはこちら)
特徴量の選定
可視化した情報をもとに、学習に使用する特徴量を選択します。
- Visual recipesのPrepareをクリックします。
Unfoldステップを選択して、以下の実装をします。
Column:stagePrefix(empty for no prefix):stage_

Fill empty cells with fixed value を選択して、0埋めします。Column(multople):stage_J1、stage_J2Value to fill with:0

Delete/Keep columns by name を選択して、必要な列だけ保持して実行します。(Output名:train_joined_prepared2)Column(multople):id、y、year、stage_J1、section、month、hour、num_tv、capaKeep

test でも同様の処理をします。(Output名:test_joined_prepared2)
testにはyがないのでレシピをコピーした場合、削除してください
one-hot encoding(ダミー変数化)とは?
カテゴリデータを機械学習モデルが扱える数値データに変換する方法です。カテゴリデータを機械学習モデルが扱える数値データに変換する方法です。
| team |
|---|
| 浦和レッズ |
| FC東京 |
| 川崎フロンターレ |
各カテゴリ毎に列を作成して、該当する行にフラグ(1)を入力します。
| 浦和レッズ | FC東京 | 川崎フロンターレ |
|---|---|---|
| 1 | 0 | 0 |
| 0 | 1 | 0 |
| 0 | 0 | 1 |
one-hot encodingを行う理由
- ほとんどのモデルはカテゴリデータをそのまま入力できないため
- 数値の大小による影響を防ぐため
- 例えば、
浦和レッズ=1, FC東京=2, 川崎フロンターレ=3のように数値を割り当てると、モデルが「FC東京(2)は川崎フロンターレ(1)より大きい」など誤った関係を学習してしまう。
学習
上記の分析を基に、モデリングをしてみましょう
train_joned_prepared2を選択して、「LAB」のVisual MLから、AutoML Predictionをクリックします。- 目的変数をyに設定し、
Quick Prototypesを選択したら作成します。 - DESIGNタブをクリックして以下の設定を行った後に、学習させます。
BASIC
Mtrics:Root Mean Square Error

Modeling
Random Forest

Random Forestとは?
複数の決定木を組み合わせて予測するアルゴリズムです。
仕組み
- データをランダムに複数のグループに分割します。
- 各グループ毎に異なる決定木を作成します。
- すべての決定木の予測結果を集約し、最も多い結果を最終予測とする。
結果確認
上記の結果をクリックして、モデルの分析をします。
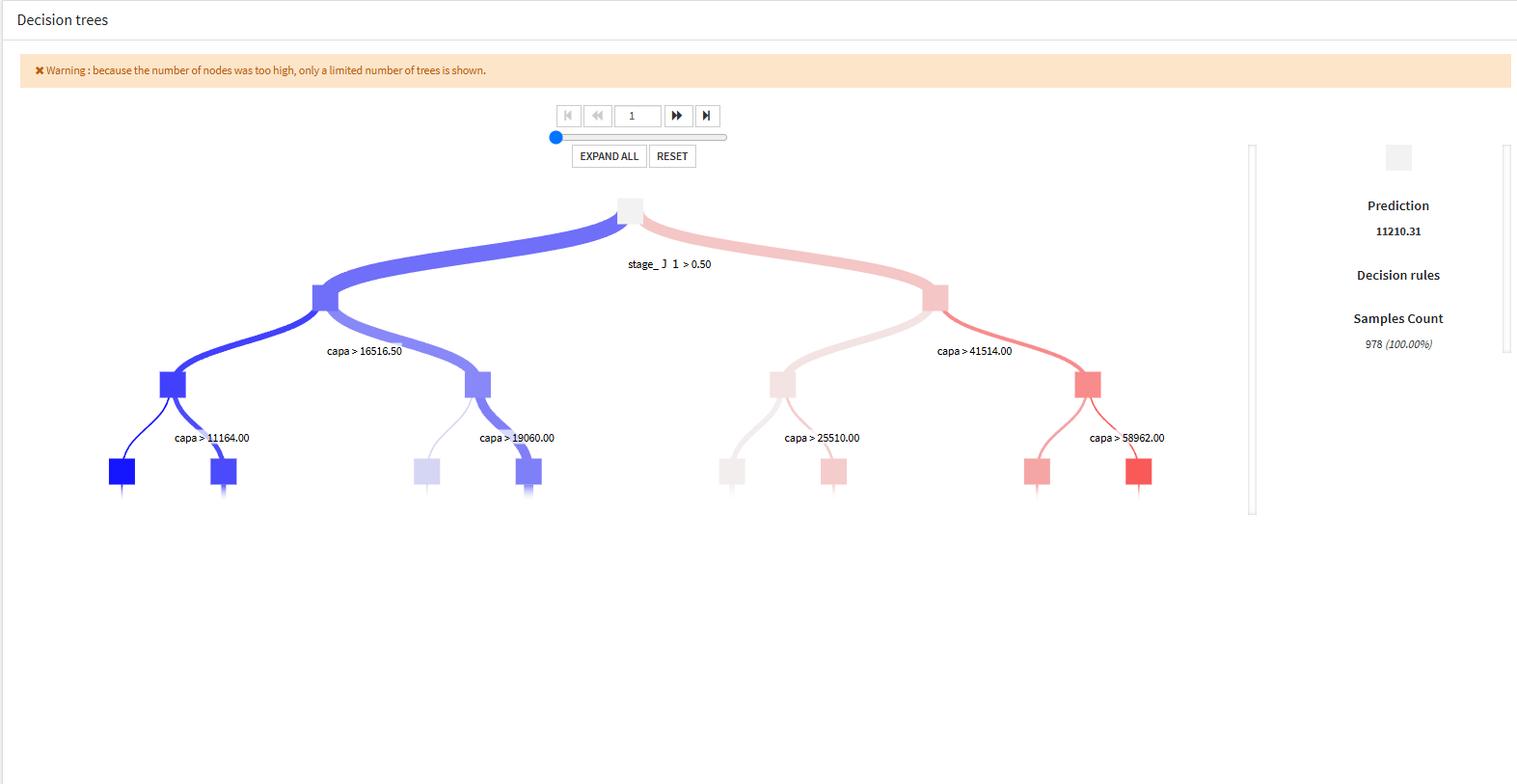
- Decision trees
特徴量毎に条件分岐をしている様子
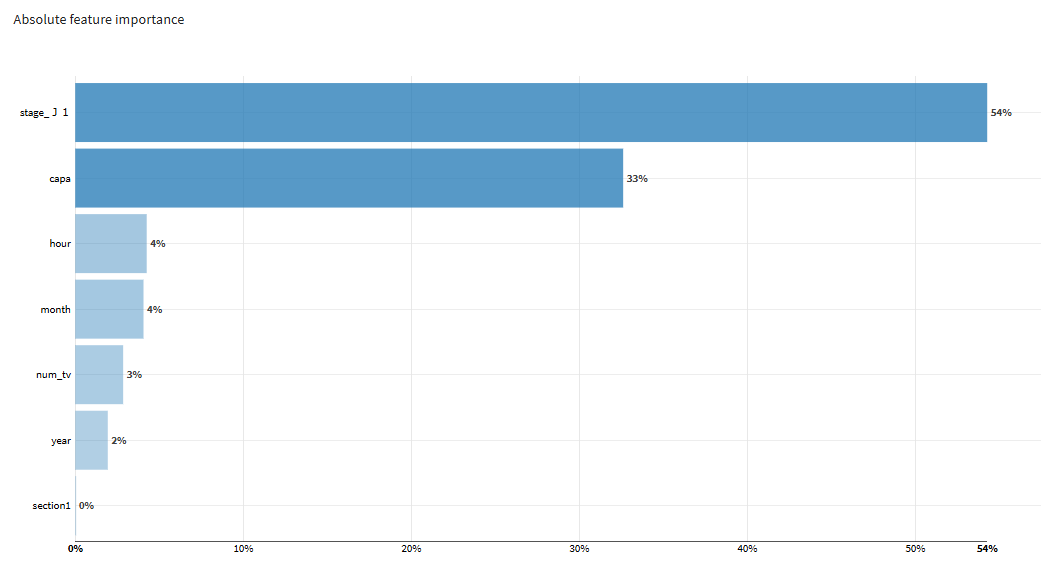
- Feature importance
モデルの結果に寄与している特徴量の割合
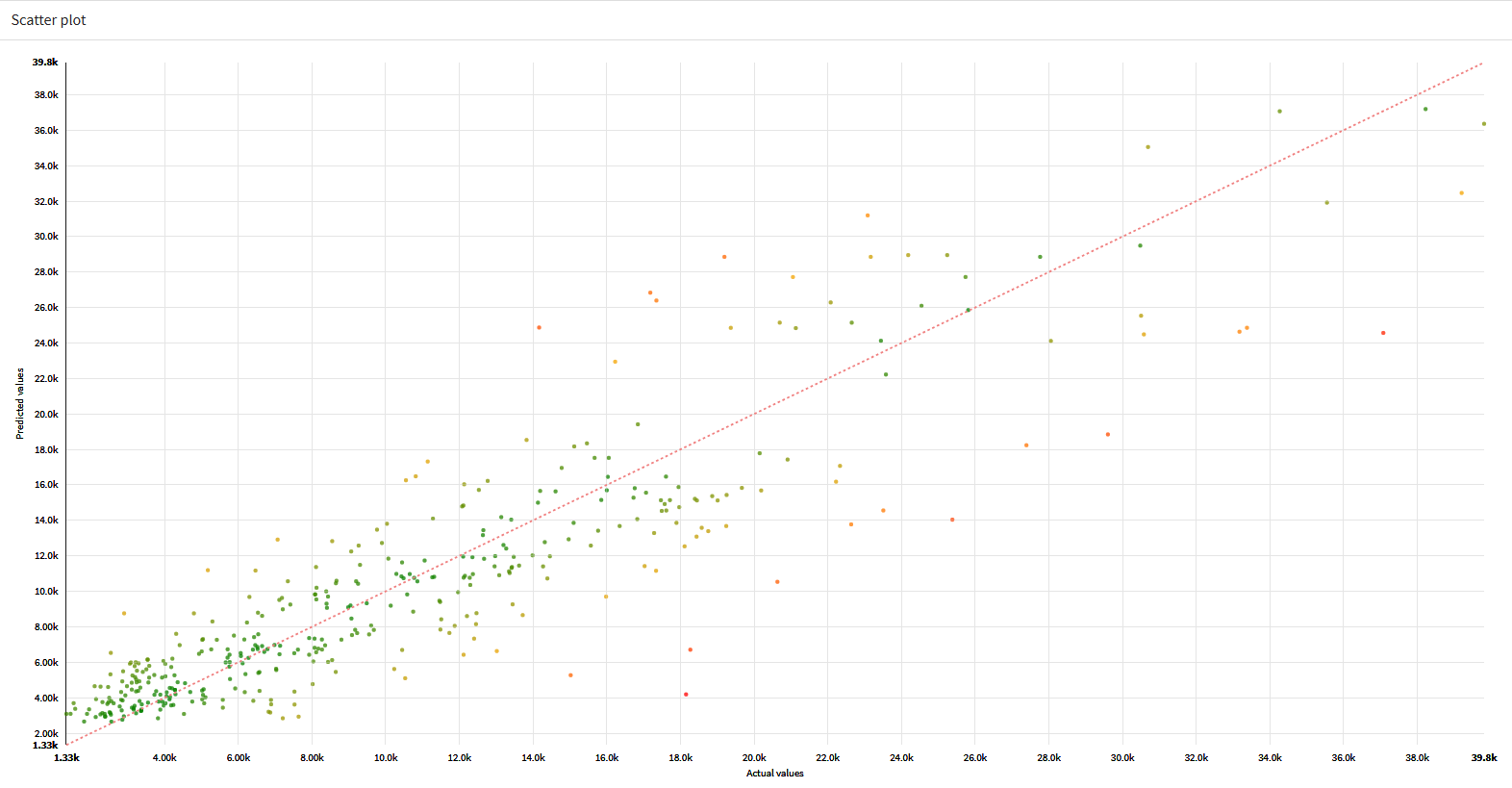
- Scatter plot
実際の値と予測の値の散布図



Predict y(regression))
予測

Predict y(regression)を選択して、Apply model on data to predictのScoreをクリックします。- Inputに
test_joined_prepared2を加えて、レシピを作成します。 - Outputで、以下の画像の設定をして実行します。(Output名:
scored)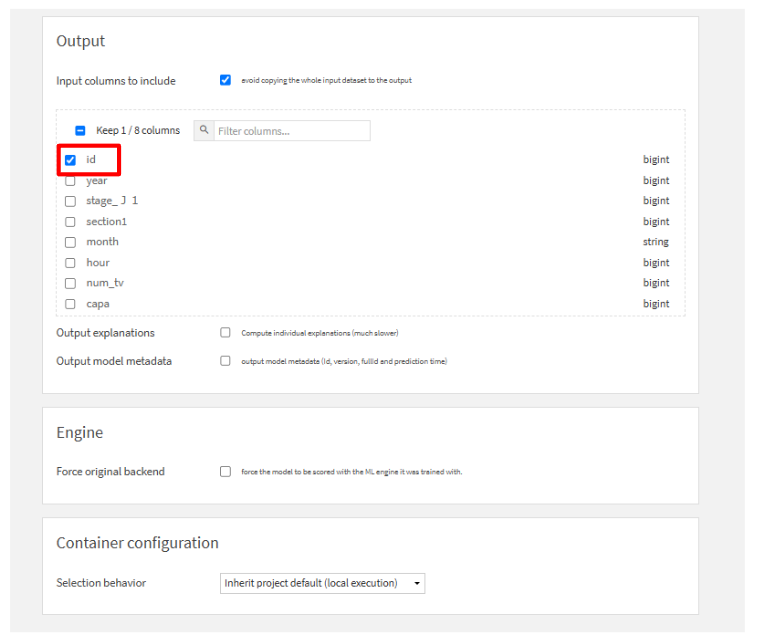

提出
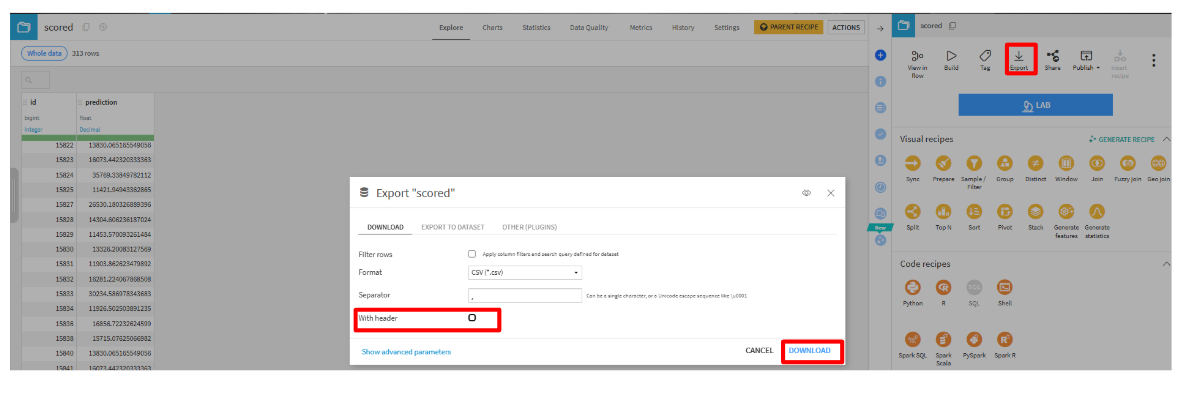
scoredを選択して、Exportをクリックします。- With headerのチェックを外して、ダウンロードします。
- SIGNATE上で提出します。

結果
結果は3832.21でした。つまり、実際の観客動員数と比較して約3,832人のずれが発生していることになります。 予測したモデルを分析すると、観客動員数が少ないときの誤差は小さい一方で、観客数が多いと誤差が大きくなる傾向が見られました。これらの分析結果をもとに改善を行うことで、予測精度の向上が期待できます。 また、以下の改善点も参考にしてみてください。
改善点
- 特徴量を増やす
- 代表選手が多いチームは観客動員数が増える可能性があります。また、試合の曜日や対戦カードの人気度なども影響を与えるかもしれません。
- 外部データを用いる
- 過去5年間の優勝チームの情報や、各チームの人気度(SNSフォロワー数、グッズ売上など)を取り入れてみると精度が上がるかもしれません。
- モデルを変更する
まとめ
今回は、お弁当の需要予測と同じ回帰分析を行いました。 同じ分析手法を用いても、データが異なれば前処理や可視化の方法が変わるため、その都度適切な対応が求められます。データに応じた柔軟なアプローチが重要であり、それには幅広い知識や技術の習得が欠かせません。 改めて、学び続けることの大切さを実感しました。今後もDataikuを活用しながら、機械学習の知識を深めていきたいと思います。 皆さんも、ぜひDataikuを使って回帰分析に挑戦してみませんか?