Dataiku Solution のLead Scoringのデータを用いてリードスコアリングのうち、リードが顧客になるか否かを判別するための分析を実施しました。
Solution | Lead Scoring
https://knowledge.dataiku.com/latest/solutions/financial-services/solution-lead-scoring.html
今回はリードスコアリングがどんな意思決定に役立つのか、そしてリードスコアリングをするために必要なデータと分析のための前処理について解説します。
1. リードスコアリングとは
リード(見込み客)の購買意欲を属性などのデータに基づいて見積もり、営業の優先順位をつけることをリードスコアリングといいます。リードスコアリングをすることでリードの購買意欲の高さを把握できるため、効率的な営業活動に繋がります。さらに、購買意欲を客観的な指標で評価することから、部署間での連携も容易になります。
2. どんなデータが必要か?
一般的には次のようなデータを使用します。営業とマーケティングの視点から、リードに関する仮説を立て、それに基づいて使用するデータを決定します。| 属性情報 | 会社であれば業種や規模など、個人であれば年齢や収入など |
|---|---|
| 内面的情報 | リードからの質問内容、コミュニケーションの方法や回数など |
| 行動情報 | 自社セミナーへの参加回数、ニュースレターの購読の有無など |
3. Dataiku Solution Lead Scoringのデータで実践
3.1 データ説明
今回スコアリングしたいリードは個人です。個人に対して様々な方法で接触したりキャンペーンをうったりすることで顧客になってもらおうと働きかけているようです。個人が対象なので、属性のデータも年齢や性別、年収などの情報から成ります。
データ1. lead_touchpoints_dataset
過去と現在のリードの内面的情報を集計したデータです。1リードに対して、リードと何らかの方法で接触した回数だけ行数があります。1つの活動で複数のリードとコミュニケーションを取ることもあるので、1つのtouchpoint_idに対して複数のlead_idが対応することもあります。
| カラム名 | データ内容 | カテゴリ |
|---|---|---|
| lead_id | leadのID | |
| touchpoint_date | leadとの接触日 | |
| touchpoint_source | leadとの接触方法 | email /online form /referral /paid advertising |
| campaign_type | キャンペーンの種類 | hybrid /global /online /physical only |
| campaign_frequency | キャンペーンの頻度 | yearly /monthly / temporary |
| touchpoint_id | 活動ID |
データ2. histrical_lead_information_dataset
過去のリードの属性と顧客になったか否かのデータです。今回はis_convertedを、リードの属性とlead_touchpoints_datasetにあるリードの内面的情報に基づき予測します。is_convertedのデータを可視化してみると、false(顧客にならなかった)に大きく偏ったデータであることがわかります。
| カラム名 | データ内容 | カテゴリ |
|---|---|---|
| lead_id | leadのID | |
| creation_date | lead_id作成日 | |
| region | leadの居住地域 | フランスの計22地域 |
| gender | leadの性別 | F /M |
| age_category_at_creation | leadの年齢カテゴリ | 例:20 to 30 yo(計5クラス) |
| income | leadの収入カテゴリ | 例:70 to 100k(計6クラス) |
| conversion_date | 顧客になった日 | |
| is_converted | 顧客になったか否か | true/ false |
データ3. to_score_lead_information_dataset
スコアリングしたいリードのデータです。現在のリードの属性情報が入っています。
| カラム名 | データ内容 | カテゴリ |
|---|---|---|
| lead_id | leadのID | |
| creation_date | lead_id作成日 | |
| region | leadの居住地域 | フランスの計22地域 |
| gender | leadの性別 | F /M |
| age_category_at_creation | leadの年齢カテゴリ | 例:20 to 30 yo(計5クラス) |
| income | leadの収入カテゴリ | 例:70 to 100k(計6クラス) |
3.2 データの前処理
今回はDataikuのいくつかのレシピを使ってデータの前処理をしていきます。前処理をすることで最終的には次のようなデータにします。・lead_id (1列)
・リードの属性 (4列)
・手段別の接触回数 (14列)
・is_converted (1列)
今の時点ではリードの属性と内面的情報のデータセットが別々に存在している状態なので、両方のデータを分析に使いやすい状態にした上で結合する必要がございます。具体的には、lead_touchpoints_datasetの情報を使ってリードとの接触回数や期間などを集計した後に、リードの属性情報が入ったhistrical_lead_information_datasetを結合して、モデルを作成していきます。
Dataikuで作成したデータの前処理フローは以下の通りです。
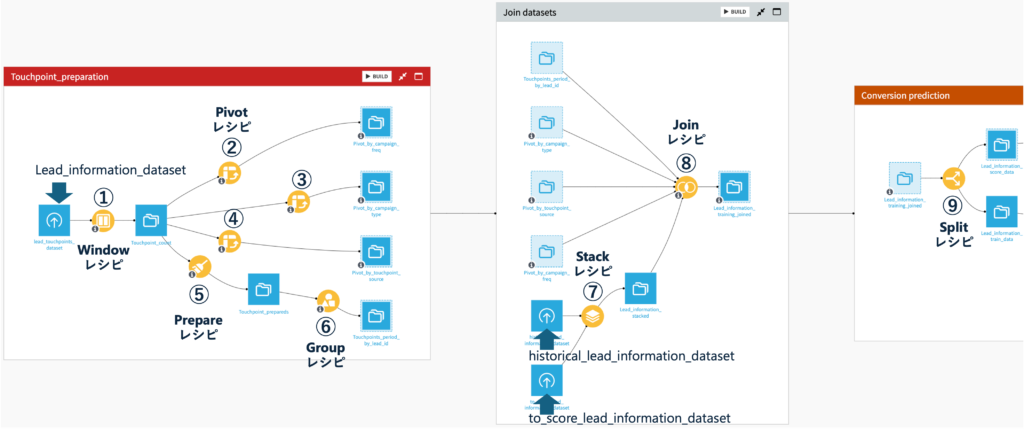
① Windowレシピでlead_idごとの接触回数、初回接触日と最新接触日を集計
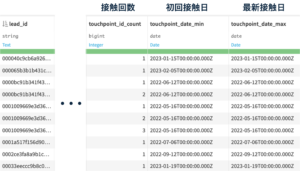
Windowレシピでは、指定した列をキーにして、別の列の要素の個数や統計量(最大・最小など)を集計できます。データの構造はそのままにグループ化を使用して計算したい場合に使用します。今回はリードごとの接触回数、初回接触日と最新接触日を集計するために、以下の設定でレシピを実行します。Window definitions : PARTITIONING COLUMNS = lead_id
Aggregations : touchpoint_id (Count), touchpoint_date (Min, Max)
レシピを実行して出力することで次のようなデータが出来上がります。
出力データ名:Touchpoint_count
②③④ Pivotレシピを使ってlead_idごとのキャンペーン回数を計算
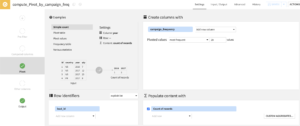
Pivotレシピでは、指定した列をキーにして別の列の各要素のレコード数をもとにした統計量を集計することができます。考え方はExcelのピボットテーブルと似ていて、レコード数をもとにした統計量を集計したい列の各要素(つまり行だったもの)が列になります。② Pivotレシピを使って、Touchpoint_countデータをもとにlead_id毎の各頻度別キャンペーンの回数を集計
campaign_frequencyの各要素(yearly, monthly, temporary)を列に変換して、リードごとの各頻度別キャンペーンの回数を集計します。設定
Create columns with : campaign_frequency
Row identifiers : lead_id
Populate content with : Count of records
出力データ名:Pivot_by_campaign_freq
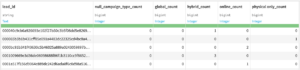
③ Pivotレシピを使って、Touchpoint_countデータをもとにlead_id毎の各種キャンペーンの回数を集計
campaign_typeの各要素(hybrid /global /online /physical only)を列に変換して、リードごとの各種キャンペーンの回数を集計します。設定
Create columns with : campaign_type
Row identifiers : lead_id
Populate content with : Count of records
出力データ名:Pivot_by_campaign_type
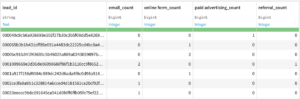
④ Pivotレシピを使って、Touchpoint_countデータをもとにlead_id毎の各種接触方法の回数を集計
touchpoint_sourceの各要素(email /online form /referral /paid advertising)を列に変換して、リードごとの各頻度別キャンペーンの回数を集計します。設定
Create columns with : touchpoint_source
Row identifiers : lead_id
Populate content with : Count of records
出力データ名:Pivot_by_touchpoint_source
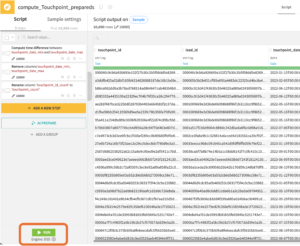
⑤ Prepareレシピを使って各リードの接触期間を計算
Prepareレシピでは演算や日付操作、置換などの前処理ができます。ここでは以下の処理を行います。Touchpoint_countデータを選択した状態でPrepareレシピをフローに追加し、Output dataset名はTouchpoint_preparedsにしておきます。1. “Compute time difference”で各リードとの接触期間を計算
レシピを作成したら、Prepareレシピ画面左下の”+ ADD A NEW STEP”から”Compute time difference”を前処理ステップに追加します。そして各パラメータは下記のように設定します。設定
Time since column : touchpoint_date_min
until : Another date column
Other column : touchpoint_date_max
Output time unit : Days
Output column : touchpoint_period_days
2. “Remove”で不要になったカラムtouchpoint_date_minとtouchpoint_date_maxを削除
touchpoint_date_minとtouchpoint_date_maxカラムの右上の逆三角を押して”Delete”を選択します。そうすると、画面左側のステップに”Remove column”ステップが追加され、削除するカラムにtouchpoint_date_minとtouchpoint_date_maxが設定されている状態になります。3. “Rename colmumn”でカラム名を変更:touchpoint_id_count → touchpoint_count
”+ ADD A NEW STEP”から”Rename column”を前処理ステップに追加します。そしてRenamingsの矢印左側に”touchpoint_id_count ”カラムを、右側に”touchpoint_count”と入力します。以上1~3のステップを実行するために、最後に画面左下のRUNを押します。
⑥ Group レシピで各リードの接触期間と回数を集計
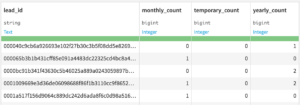
Group レシピでは、Group keyに指定したカラムの属性を元に他のカラムの属性の値を集計することができます(合計,最大など)。Windowレシピと似ていますが、出力されるデータの構造が大きく異なります。Windowレシピは元のデータ構造を保ったまま他のカラムの属性の値を集計するのに対し、Group レシピではGroup keyに指定したカラムの各要素が1行にまとめられた状態で出力されます。リードとの接触期間の計算結果が反映されてデータTouchpoint_prepareds(下の画像、ここではわかりやすいようにフィルター済み)を見てみると、接触期間のカラムtouchpoint_period_daysも接触回数のカラムtouchpoint_countもこのままでは分析に使えません。touchpoint_period_daysは接触日数の最大値と最小値が入っている状態で、touchpoint_countは、同じlead_idのデータの中で日付の若い方からの順番が入っている状態です。両カラムとも分析に必要なデータは最大値だけなので、Groupレシピを使ってlead_id毎に最大値だけを抽出します。

各パラメータは下記のように設定します。
設定
Group keys : lead_id
Per field aggregations : touchpoint_count (Max) , touchpoint_period_days (Max)
出力データ名:Touchpoints_period_by_lead_id
⑦ Stackレシピでhistrical_lead_information_datasetとto_score_lead_information_datasetを縦に結合
過去のリードの属性と顧客になったか否かのデータhistrical_lead_information_datasetとスコアリングしたいリードの属性データto_score_lead_information_datasetを縦に結合しておきます。先に作成した4つのデータとこれらのデータをlead_idで紐づけて、モデルのトレーニングとリードスコアの予測に使うためです。histrical_lead_information_datasetを選択した状態でStackレシピを追加し、”ADD”からto_score_lead_information_datasetを選択します。出力データ名はLead_information_stackedとします。レシピを作成したら、”Origin column”に結合前のデータソースを示す属性を追加します。

⑧ Joinレシピでモデルの作成と評価に使うデータセットを全て結合
Joinレシピでは特定のカラムの値をキーにして、複数のデータセットを結合するレシピです(左結合・右結合・内部結合・左外部結合・完全外部結合など)。今回使用する左結合 left-joinは、“Left”に指定したデータの特定の列の要素をキーにして “Right”に指定したデータセットを結合します。ここまでの前処理でlead_touchpoints_datasetから次の4つのデータが派生しました。
Pivot_by_campaign_freq:各リードが受けた各頻度別キャンペーンの回数
Pivot_by_campaign_type:各リードが受けた各種キャンペーンの回数
Pivot_by_touchpoint_source:各リードに対する各種接触方法の回数
Touchpoints_period_by_lead_id:各リードの接触期間と回数
これらのキャンペーン情報のデータセットとリードの属性のデータセットLead_information_stackedをlead_idをキーにして紐づけます。結合したいデータのうち一つを選択した状態でJoinレシピを選び、Input datasetに他のデータセット(ここでは一つ)を選択します。レシピ作成後にJoinタブでその他のデータセットを追加できます。出力データ名はLead_information_training_joinedとします。
次に、Selected columnsで結合後のデータに残したいカラムを選択します。全部のデータをそのままlead_idで紐づけて結合してしまうとカラムが重複してしまうので、以下のカラムを残します。
| データ名 | データ内容 | 結合後残すカラム |
|---|---|---|
| Lead_information_stacked | トレーニングデータ+顧客価値予測データ | 全部 |
| Touchpoints_period_by_lead_id | 接触期間・回数 | touchpoint_count_max, touchpoint_period_days_max |
| Pivot_by_campaign_type | 各種キャンペーンの回数 | 全部 |
| Pivot_by_touchpoint_source | 各種接触方法の回数 | 全部 |
| Pivot_by_campaign_freq | 各頻度別キャンペーンの回数 | 全部 |
以上①〜⑧の前処理を経て以下のデータ”Lead_information_training_joined”が出来上がりました。
| カラム名 | データ内容 |
|---|---|
| lead_id | leadのID |
| creation_date | lead_id作成日 |
| region | leadの居住地域 |
| gender | leadの性別 |
| age_category_at_creation | leadの年齢カテゴリ |
| income | leadの収入カテゴリ |
| conversion_date | 顧客になった日 |
| is_converted | 顧客になったか否か |
| original_dataset | データソース名(lead_information_training/lead_information_to_scored) |
| touchpoint_count_max | 合計接触回数 |
| touchpoint_period_days_max | 合計接触期間 |
| null_campaign_type_count | null_campaign_typeキャンペーンの回数 |
| global_count | globalキャンペーンの回数 |
| hybrid_count | hybridキャンペーンの回数 |
| online_count | onlineキャンペーンの回数 |
| physical only_count | physical onlyキャンペーンの回数 |
| email_count | emailでの合計接触回数 |
| online form_count | online formでの合計接触回数 |
| paid advertising_count | paid advertisingでの合計接触回数 |
| referral_count | referralでの合計接触回数 |
| monthly_count | monthlyキャンペーンでの接触回数 |
| temporary_count | temporaryキャンペーンでの接触回数 |
| yearly_count | yearlyキャンペーンでの接触回数 |
⑨ Splitレシピでトレーニング用のデータとリードスコアを予測したいデータを分離
Splitレシピでは設定した基準を元にデータを分割できます。original_datasetカラムを基準にoriginal_datasetの値がlead_information_trainingとなっている行はLead_information_train_dataに、original_datasetの値がLead_information_to_scoredとなっている行はLead_information_test_dataに分割します。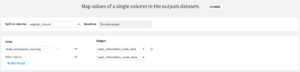
以上でデータの前処理が完了しました。次回「Dataikuでリードスコアリングをやってみた(分析編)」にて、モデルの作成から評価までのフローについて解説します。
このようにDataikuはノーコードでデータを一括統合・一括管理を可能にします。 弊社では長年培ってきたデータソリューションの知見を活かし、Dataikuの環境構築から運用支援までトータルでサポートします。 社内に散在しているデータを統合し活用したい皆様からのお問い合わせをお待ちしております。
