1. はじめに
Dataikuでは、あるプロジェクトで作成したレシピやデータセットなどを、別のプロジェクトで再利用可能なプラグインとしてパッケージ化することができます。これにより、ユーザーは過去に作成した機能やデータセットを再度作成する必要なく、プラグインをインストールことでその機能が利用可能になるため、AI開発の生産性を高めることが可能となります。
以下はプラグインに含めることができる要素の例です。

- データセット
- レシピ
- “Prepare”レシピで使用可能なプロセッサ
- 機械学習アルゴリズム
など
プラグインはGitHub上で他のユーザーに対して公開したり、.zipファイルとして共有したりすることが可能です。公開・共有されたプラグインをインストールすることでプラグインのコンポーネントをまとめて利用可能になります。
プラグインの例
- Geocoder
https://www.dataiku.com/product/plugins/geocoder/
ジオコーディング*とリバースジオコーディング**が可能です。
*ジオコーディング:住所を地図上で使用できる座標セットに変換するプロセス
**リバースジオコーディング:座標を読み取り可能な住所に変換するプロセス
また、インストールしたプラグインは編集可能であり、それぞれのユーザーのニーズに合わせてカスタマイズすることができます。
今回は、通常のDataikuのJoinレシピでは設定できない、2つのデータセットの全結合を行う処理を例に、プラグインの作成方法を紹介します。
2. プラグイン作成のはじめかた
プラグインはフロー中に存在するPythonレシピから変換することで作成できます。
作成済みのPythonレシピの編集画面を開き、画面右上のメニューから”Convert to plugin”を選択します。
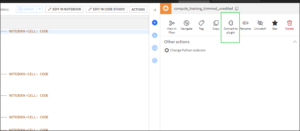
3つの選択・入力項目が表示されます。
- Target plugin
新規のプラグインを作成するか、既存のプラグインにレシピを追加するかを選択します。
- Plugin id
様々なコンポーネントを含むプラグイン全体のidを設定します。
- New plugin recipe id
プラグイン内に作成するレシピのidを設定します。
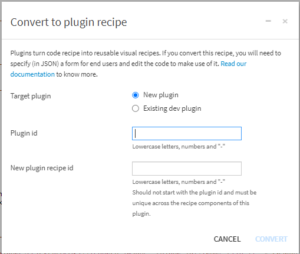
今回は新規にプラグインを作成するため、Target pluginは”New plugin”を選択します。
ここまでの工程が完了するとレシピの編集画面に移行します。
3. JSONファイルとPythonファイルの編集
プラグインを新規作成した際とコンポーネントを追加した際に、プラグインのフォルダー内にフォルダーが追加され、内部にJSONファイルとPythonファイルが自動的に作成されます。
JSONファイルではPlugin利用時の操作画面やPythonで利用する引数を設定し、Pythonファイルでは目的の処理内容とJSONからの引数の設定を行います。
JSON
JSONファイルではmeta、inputRoles / outputRoles、params、recourcsKeysの基本情報の設定が可能です。
-
meta
表示目的で使用。表示名や説明、アイコンの設定が可能。 -
inputRoles / outputRoles
入力ファイルや出力ファイルの設定。“name”:Pythonで利用する際の定義名
“label”:UI表示ラベル
“description”:UI説明文
“arity”:取得データ数。(UNARY:一つ、NARY:複数)
“required”:入力が必須かどうか(ブール値)
“acceptsDataset”:データセットを入力ファイルとして受け取るか。(ブール値)
“acceptsManagedFolder” :マネージドフォルダを入力ファイルとして受け取るか。(ブール値)
-
params
Python内で利用する変数の設定。“name”:Pythonで利用する際の定義名
“label”:UIの表示ラベル
“type”:データ型
“description”:UI説明文
“mandatory”:入力が必須かどうか。(ブール値)
“columnRole”:入力ファイルのカラム名取得
“defaultValue”:デフォルト値
“selectChoices”:指定選択
“visibilityCondition”:表示非表示の条件パラメータ(リンク)
-
resourceKeys
リソースを識別するためのキー
Python
PythonファイルではPythonレシピで作成した処理内容に加えて、JSONから受け取る入力やパラメータのインスタンス設定が必要になります。
データの読込み
"""
inputRoles / outputRolesがデータセットの場合
"""
# input
input_A_names = get_input_names_for_role('jsonのname')[0] # jsonから変数名読込み
input_A_datasets = dataiku.Dataset(input_A_names)
df = input_A_datasets.get_dataframe() # データフレームに変換
# output
output_A_names = get_output_names_for_role('jsonのname')[0] # jsonから変数名読み込み
output_A_datasets = dataiku.Dataset(output_A_names)
"""
inputRoles / outputRolesがフォルダの場合
"""
# input
input_folder_name = get_input_names_for_role('jsonのname')[0]# jsonから変数名読込み
input_folder_obj = dataiku.Folder(input_folder_name)
input_file_names = input_folder_obj.list_paths_in_partition()# フォルダに含まれるファイルのリストを取得
file_obj = input_folder_obj.get_download_stream('ファイル名')# フォルダ中のファイルをオブジェクトとして取得
file_read = file_obj.read()
# output
output_folder_name = get_output_names_for_role('jsonのname')[0]# jsonから変数名読み込み
output_folder_obj = dataiku.Folder(output_folder_name)
データの出力
"""
inputRoles / outputRolesがデータセットの場合
"""
output_A_datasets.write_with_schema(保存するDataFrameの変数名) # 保存・出力
"""
inputRoles / outputRolesがフォルダの場合
"""
output_folder_obj.upload_stream('保存するファイル名' ,保存するオブジェクトの変数名) # 保存・出力
パラメータの設定
variable_1 = get_recipe_config()['jsonのparams.name']上記で定義した変数をコード内で利用することになります。
今回作成する、2つのデータセットの全結合を行うプラグインでは以下のようなコードになります。
JSON
{
"meta": {
"label": "Fully Connected Join",
"description": "This recipe fully connects two datasets with an outer join",
"icon": "fas fa-link"
},
"kind": "PYTHON",
"inputRoles": [
{
"name": "input_A_role",
"label": "Input Dataset A",
"description": "First input dataset",
"arity": "UNARY",
"required": true,
"acceptsDataset": true
},
{
"name": "input_B_role",
"label": "Input Dataset B",
"description": "Second input dataset",
"arity": "UNARY",
"required": true,
"acceptsDataset": true
}
],
"outputRoles": [
{
"name": "main_output",
"label": "Output Dataset",
"description": "Merged output dataset",
"arity": "UNARY",
"required": true,
"acceptsDataset": true
}
],
"params": [
{
"name": "join_key_A",
"label": "Join Key for Dataset A",
"type": "COLUMN",
"description": "Column from Dataset A to join on",
"mandatory": true,
"columnRole": "input_A_role" # Dataset A用のカラム選択
},
{
"name": "join_key_B",
"label": "Join Key for Dataset B",
"type": "COLUMN",
"description": "Column from Dataset B to join on",
"mandatory": true,
"columnRole": "input_B_role" # Dataset B用のカラム選択
}
]
}
Python
import pandas as pd
import dataiku
from dataiku.customrecipe import get_input_names_for_role, get_output_names_for_role, get_recipe_config
# 入力データセットを取得
input_A_names = get_input_names_for_role('input_A_role')
input_B_names = get_input_names_for_role('input_B_role')
input_A_dataset = dataiku.Dataset(input_A_names[0])
input_B_dataset = dataiku.Dataset(input_B_names[0])
# 出力データセットを取得
output_A_names = get_output_names_for_role('main_output')
output_A_dataset = dataiku.Dataset(output_A_names[0])
# 設定されたjoin keyを取得
config = get_recipe_config()
join_key_A = config['join_key_A']
join_key_B = config['join_key_B']
# チャンクサイズを設定(例:1万行ごとに処理)
chunksize = 10000
# 入力データセットをチャンク処理で読み込み
df_A_iterator = input_A_dataset.iter_dataframes(chunksize=chunksize)
df_B_iterator = input_B_dataset.iter_dataframes(chunksize=chunksize)
# 各チャンクごとにデータフレームを結合し、結果を出力データセットに書き込む
for df_A, df_B in zip(df_A_iterator, df_B_iterator):
# 必要に応じて数値列だけを変換(この例では、カテゴリやテキスト列を無視)
for col in df_A.columns:
if pd.api.types.is_numeric_dtype(df_A[col]):
df_A[col] = df_A[col].astype('float32')
for col in df_B.columns:
if pd.api.types.is_numeric_dtype(df_B[col]):
df_B[col] = df_B[col].astype('float32')
# データを全結合(outer join)する
result_chunk = pd.merge(df_A, df_B, left_on=join_key_A, right_on=join_key_B, how='outer')
# 出力データセットに書き込む
output_A_dataset.write_with_schema(result_chunk)
4. code envの設定
作成したプラグインには、専用の環境が必要になります。
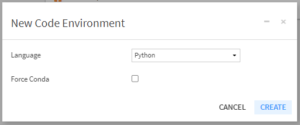
[Summary]ページの右上にある[Code environment]の項目から、[+ CREATE A CODE EMVIROMENT]をクリックして、code envを新規作成できます。

[New Code Environment]が表示されたら、”Language”をPythonに設定し、”Force Conda”のチェックボックスは空の状態にします。
画像と同じ状態になったら、”CREATE”をクリックしてcode envを作成します。
ここで編集画面に移動すると、”code-env”のフォルダ及びその中の各種ファイルが作成されていることが確認できます。
編集画面では、環境にインストールするライブラリを設定します。
[code-env]>[python]>[spec]>requirements.txtを開き、その中に今回作成するプラグインで使用するライブラリ”<必要なライブラリ名>”を入力します。
編集が完了したら右上の”Save All”をクリックして保存します。
サマリーの画面に戻り、デフォルトの設定のまま”BUILD NEW ENVIROMENT”をクリックします。
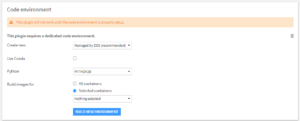
以下のような画面が表示されればcode envの構築は完了です。
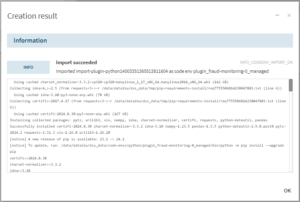
code envの構築まで完了すると、プラグインが使用可能になります。
5. テスト
作成したプラグインを実際に使用してみました。
ここでは例として、
- 都道府県コードと都道府県のデータを持つデータセット ”todoufuken”
- 都道府県と人口50万人以上の都市(政令指定都市)、人口のデータを持つデータセット “serirei_shitei_toshi”
以上の2つのデータセットを結合してみました。
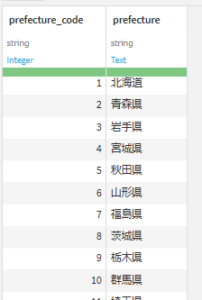
todoufuken
カラム:prefecture_code, prefecture
レコード数:47
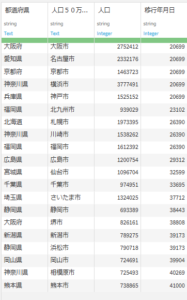
seirei_shitei_toshi
カラム:都道府県, 人口50万人以上の都市, 人口, 移行年月日
レコード数:20
データセット ”todoufuken”を選択した状態でフロービュー右上の ”+RECIPE ▼”をクリックすると、プラグインを含む使用可能なレシピの一覧が表示されます。その中から今回作成したプラグインの ”Data merge”を選択します。
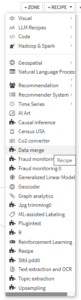
下のようなウィンドウが表示されるので、使用するコンポーネントである”Fully Connected Join”を選択します。
(プラグインに複数のコンポーネントが含まれる場合、ここで複数の選択肢が表示されます。)
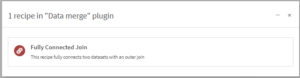
入力画面では結合に使用するキーとなるカラムをそれぞれのデータセットについて指定します。ここでは、データセット ”todoufuken”のカラム ”prefecture”、データセット ”seirei_shitei_toshi”のカラム ”都道府県”を指定します。
入力が完了したら画面左下の ”▶RUN”をクリックして実行します。
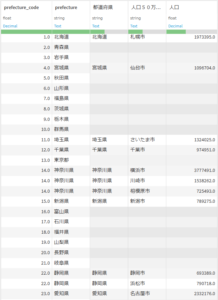
実行が完了するとフローに結合済みのデータセットが新しく出力されます。
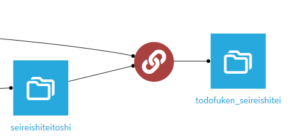
結合した両データセットのカラム・レコードは完全に保持されており、また複数の政令指定都市を持つ府県があったことから、レコード数は52になりました。
まとめ
プラグインを作成することで、自身の作成したモジュールを他の人が簡単に使うことができるようになり、AI活用を加速させることができます。ぜひ、チームのニーズに合わせたプラグインを開発し、Dataikuをさらに活用してみてはいかがでしょうか?
