2024年1月22日にData Haikerの第4回が開催されました。参加された皆様お疲れ様でした。
【Data Haiker】第4回 Dataiku無料版ハンズオンでデータスキルをアップしよう!
https://dataiku.connpass.com/event/305657/
さて、今回のData Haikerでも実際のデータを用いた分析体験の時間が有ったのですが、
弊社データサイエンティストがどのようなアプローチで取り組んだのかを解説させて頂ければと思っています。
少し内容が長くなりそうですが、お付き合い頂けますと幸いです。
今回の課題について
今回は、KaggleのShould This Loan be Approved or Denied?というデータセットを使用しました。
米国中小企業庁の融資に関するデータセットで、それぞれの融資が正しく返済されたのか、滞納したのかも含め、以下のような特徴量があります。
| LoanNr_ChkDgt | Identifier Primary key | 識別子 主キー |
| Name | Borrower name | 借り手の名前 |
| City | Borrower city | 借り手の都市名 |
| State | Borrower state | 借り手の都道府県 |
| Zip | Borrower zip code | 借り手の郵便番号 |
| Bank | Bank name | 銀行の名前 |
| BankState | Bank state | 銀行の都道府県 |
| NAICS | North American industry classification system code | 北米産業分類システムコード |
| ApprovalDate | Date SBA commitment issued | SBAコミットメント発行日 |
| ApprovalFY | Fiscal year of commitment | コミットメント年度 |
| Term | Loan term in months | 借入期間(月) |
| NoEmp | Number of business employees | 従業員数 |
| NewExist | 1 = Existing business, 2 = New business | 1 = 既存事業、2 = 新規事業 |
| CreateJob | Number of jobs created | 創出した雇用者数 |
| RetainedJob | Number of jobs retained | 維持する雇用者数 |
| FranchiseCode | Franchise code, (00000 or 00001) = No franchise | フランチャイズ・コード、(00000 または 00001) = フランチャイズなし |
| UrbanRural | 1 = Urban, 2 = rural, 0 = undefined | 1 = 都市部、2 = 地方、0 = 未定義 |
| RevLineCr | Revolving line of credit: Y = Yes, N = No | リボのクレジット枠:Y=あり、N=なし |
| LowDoc | LowDoc Loan Program: Y = Yes, N = No | ロードック融資プログラム: Y=はい、N=いいえ |
| ChgOffDate | The date when a loan is declared to be in default | ローン不履行宣言日 |
| DisbursementDate | Disbursement date | 支払日 |
| DisbursementGross | Amount disbursed | 支払額 |
| BalanceGross | Gross amount outstanding | 総残高 |
| MIS_Status | Loan status charged off = CHGOFF, Paid in full =PIF | 貸出状況(CHGOFF=貸し倒れ→非承認、PIF=返済した→承認) |
| ChgOffPrinGr | Charged-off amount | 貸し倒れの金額 |
| GrAppv | Gross amount of loan approved by bank | 銀行が承認した融資総額 |
| SBA_Appv | SBA’s guaranteed amount of approved loan | SBA保証額 |
今回はこのデータセットを用いて、ローンを承認すべきか、非承認にすべきかを分類するモデルを作ってみます。
EDA
- データ理解
各カラムの一つ一つ見ていきます。例えば最初の三つのカラムであるLoanNr_ChkDgt,Name,Cityを見てみます。これらのカラムは今回のお題であるローンに承認/非承認には関係ないとして今回は削除します。他にもState,Zip,Bankも同様の理由で削除します。

次にNAICSについて考えます。カラムに入っているデータで使える内容は現状上2桁の数字のみなので上2桁のみ取り出し、かつ対応する業種に置き換えることができそうです。

次に日付データについてみてみます。

年度データを含めて学習すると未知のデータが入力された場合、未来の年度が入ってしまう可能性があります。この場合、モデルが未知の年度に対応していないため精度が落ちる原因になってしまいます。そのため今回は年度データは削除する方針とします。
- 欠損値処理
全体のデータ量が多いかつ、データ欠損値の行が少ない場合は行or列の削除することもあります。
補完する場合は平均値や最頻値、-1などの固定値で埋めるか、予測値で埋めるなどがあり、データによって方法を考慮する必要があります。
- 異常値の処理
異常値が本当に無関係なノイズなのか、データとして意味があるかは中身を見て確認する必要があります。ノイズなら削除や補正を検討し、意味がありそうなら残せばよいこともあります。
- 使える特徴量の確認
は事前に分かるはずのない情報として使えない可能性があります。
例えば、
ChgOffDateは承認プロセス後に決まるものなので、特徴量としては使えない可能性があります。同様に
も承認プロセス後にわかるので特徴量として使えない可能性があります。
実際にデータを見ながら以下のようなルールをもとにデータ整形を検討してみました。
Rule 1:欠損値が有る
Rule 2:異常値が有る
Rule 3:答えが分かる
Rule 4:時系列
| 列名 | Rule 1 | Rule 2 | Rule 3 | Rule 4 | 備考 |
|---|---|---|---|---|---|
| LoanNr_ChkDgt | 個別の特徴なので学習には使えない | ||||
| Name | 個別の特徴なので学習には使えない | ||||
| City | 名称が多すぎる? 回数が多いものだけに絞る | ||||
| State | 名称が多すぎる? 回数が多いものだけに絞る | ||||
| Zip | 名称が多すぎる? 回数が多いものだけに絞る | ||||
| Bank | 〇 | 名称が多すぎる? 回数が多いものだけに絞る | |||
| BankState | 〇 | 〇 | 名称が多すぎる? 回数が多いものだけに絞る | ||
| NAICS | 名称が多すぎる? 頭2桁が中分類を表すのでそれだけを使う | ||||
| ApprovalDate | 〇 | 日付列 | |||
| ApprovalFY | 〇 | 日付列 | |||
| Term | |||||
| NoEmp | |||||
| NewExist | |||||
| CreateJob | |||||
| RetainedJob | |||||
| FranchiseCode | |||||
| UrbanRural | |||||
| RevLineCr | 〇 | 〇 | 異常値、欠損値あり | ||
| LowDoc | 〇 | 〇 | 異常値、欠損値あり | ||
| ChgOffDate | 〇 | 〇 | 日付列 | ||
| DisbursementDate | 〇 | 〇 | 承認プロセス後にわかるもの | ||
| DisbursementGross | 〇 | 承認プロセス後にわかるもの | |||
| BalanceGross | 〇 | 承認プロセス後にわかるもの | |||
| MIS_Status | 目的変数 | ||||
| ChgOffPrinGr | 〇 | 承認プロセス後にわかるもの | |||
| GrAppv | |||||
| SBA_Appv |
モデル構築
- モデル構築
前処理したデータをもとに機械学習モデルを作成します。始めにデフォルトで設定してあるRandom forestとLogstic regression を使います。
実際に学習させると以下のようになります。
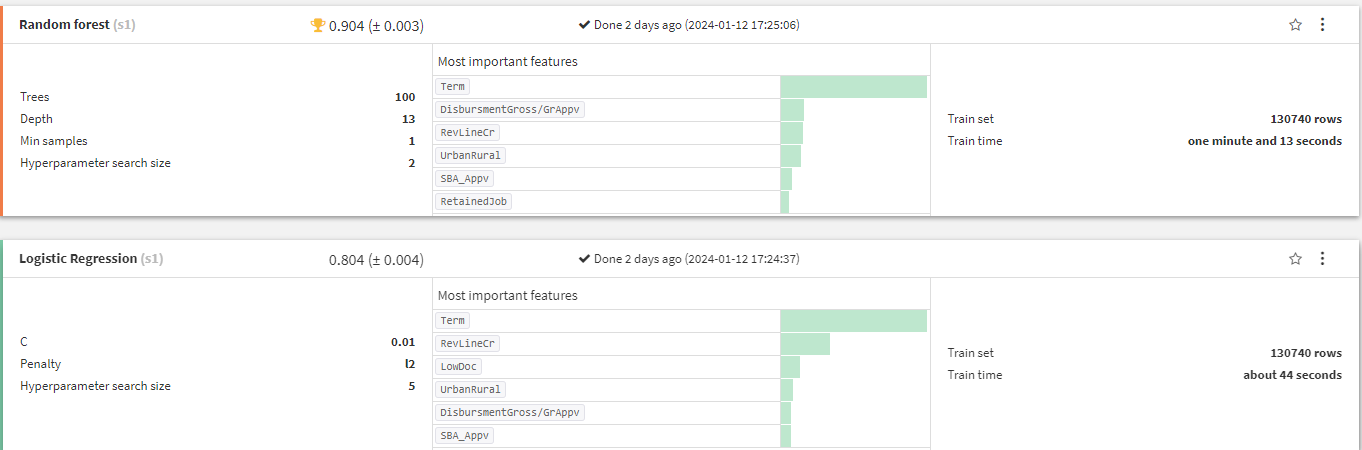
この二つのモデルではRandom forestが精度がいいようです。

- 特徴量重要度の確認
Random forestに影響を与えている特徴量の重要度をみていきます。以下の棒グラフが特徴量の重要度を表しています。とくにtermが大きな影響を与えている反面、Franchise CodeやLowDocは低いようです。

- 混同行列の確認
モデルの精度の指標となる混同行列を確認してみます。混同行列はモデルの予測精度を理解できる機能になります。実際に学習させたRandom forestの混同行列は以下のようになります。
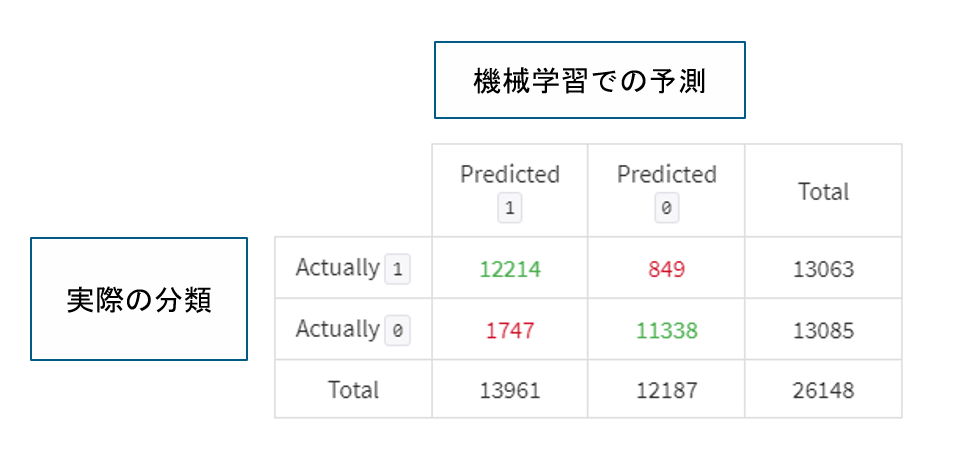
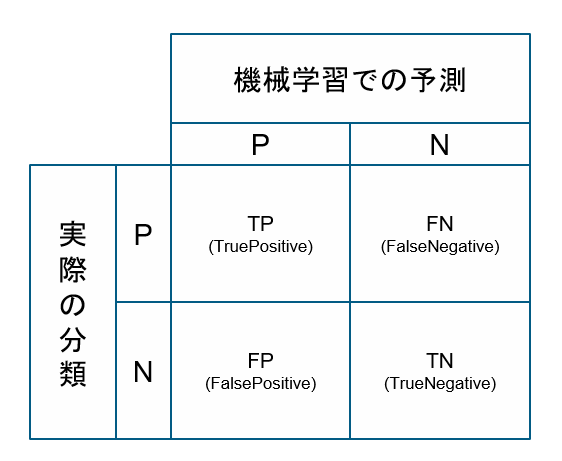
混同行列における指標について説明します。
まずTP(True Positive)は実際にPositiveと分類されているものを正しくPositiveと予測できている値になります。
TN(True Negative)は実際にNegativeと分類されているもので正しくNegativeと予測できている値になります。
FP(False Positive)は実際にNegativeと分類されているものをPositiveと予測している値になります。
FN(False Negative)は実際にPositiveと分類されているものをNegativeと予測している値になります。
今回のテーマはローンの承認/非承認がテーマなので、非承認を承認すると予測しないようにしなければいけない、かつ本来承認すべき人を非承認と予測する数を減らしたいという目的を仮に立てます。(指標の立て方はプロジェクトの目的によって変わってきます)
ここで各指標について説明します。
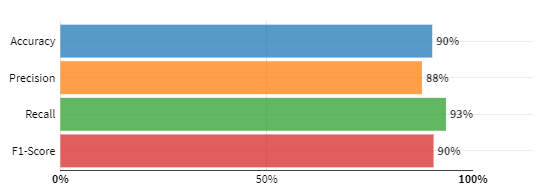
Accuracy(正解率): 全データのうち正しく予測できたものの割合
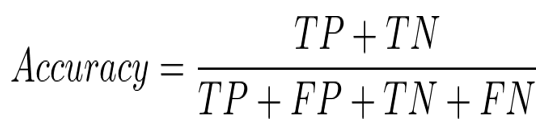
Precision(適合率):Positiveと予測されたうち実際にPositiveだった割合
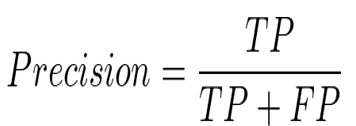
Recall(再現率):実際Positiveだったもののうち予測がPositiveだった割合
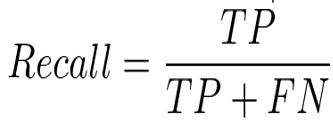
F1スコア:Precision(適合率)とRecall(再現率)の調和平均
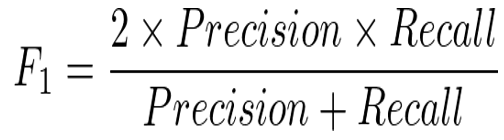
この4つの指標をもとにお題に沿った指標を評価軸としてやってモデルを作成していきます。
今回のテーマはローンの承認/非承認の予測です。非承認を承認と予測してしまう(FNの数が増えてRecallが下がる)のは良くないかつ、承認を非承認と予測してしまう(FPの数が増えてPresicionが下がる)のもよくないのでバランスを取る必要があります。
今回はF1スコアを評価指標として採用します。F1スコアはPrecisionとRecallをバランスよく
とれるためです。







- モデルの変更、追加
これまではRandom forest,Logistic regressionという2つのモデルを使っていましたが追加でLightGBMというモデルを追加して学習させてみます。
実際にLightGBMを追加したうえでで学習した結果が以下のようになります。
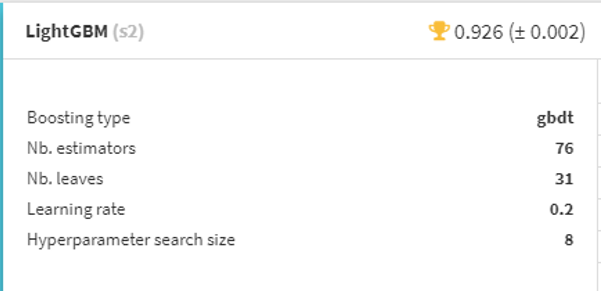
LightGBMのほうが精度がよさそうでした。そのためここから先はLightGBMを用いてモデル作成を進めていきます。
LightGBMの特徴量重要度を見てみます。
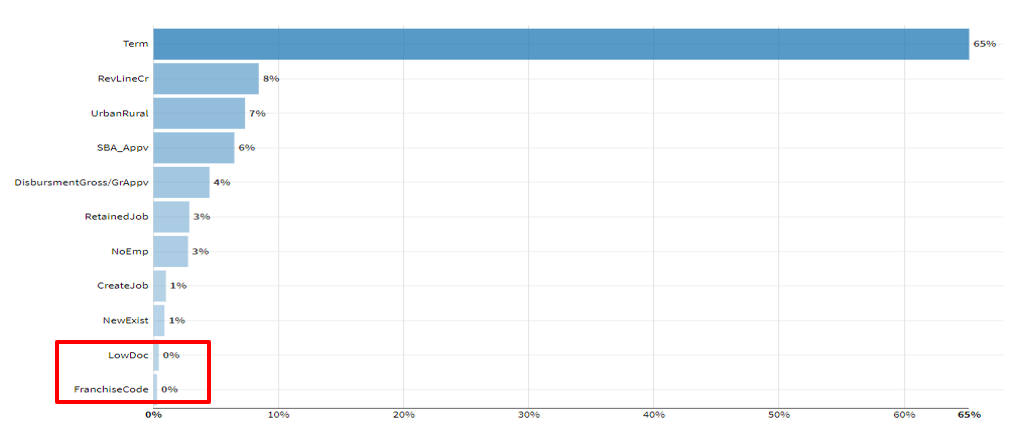
FranchiseCode,LowDocが低いようです。この特徴量を選択肢から外してもう一度学習してみます。
テストデータでF1スコアを評価した結果が以下のようになります
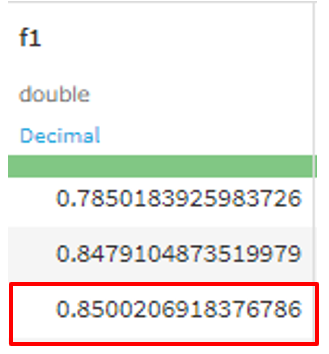
前回よりもよくなりました。特徴量を少なくするとモデルの解釈性を上げることにもつながり、過学習を避けることができる計算コストも下がります。



- ハイパーパラメータチューニング
精度を上げる方法として、ハイパーパラメータチューニングという方法があります。
ハイパーパラメータチューニングとは機械学習モデルの設定値(ハイパーパラメータ)を変えることによって精度を調整する手法です
例えばRamdom forestだと以下のようなハイパーパラメータが存在します。
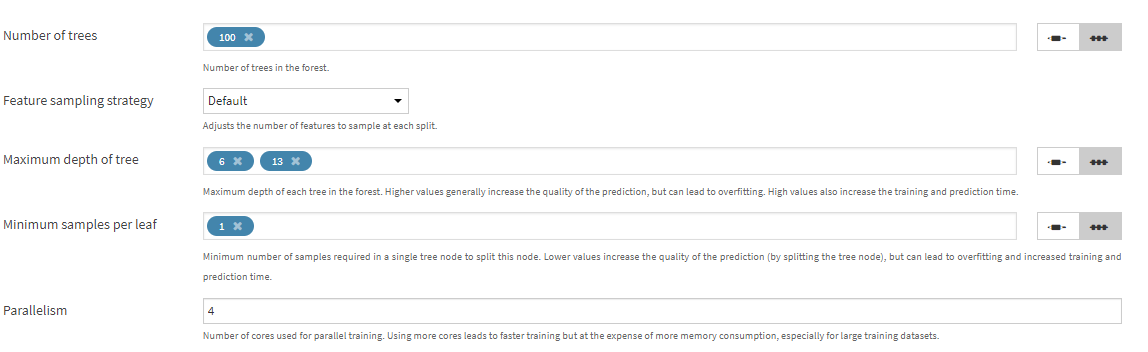
デフォルトで設定されている値に加えて手でハイパーパラメータを新たに設定することができます。
精度を調整するためのハイパーパラメータチューニングの手法の一つとしてグリッドサーチを紹介します。
グリッドサーチとは、選択した複数の設定値の組み合わせの総当たりのパターンをもとに精度が最も良いパラメータを探す手法になります。
例えば以下の画像のようにモデルの設定値をパラメータ1とパラメータ2というふうにします。
二つのパラメータの組み合わせは格子点のようにプロットすることができます。
この格子の中の組み合わせから一番精度の良いパラーメータを探すのがグリッドサーチになります。
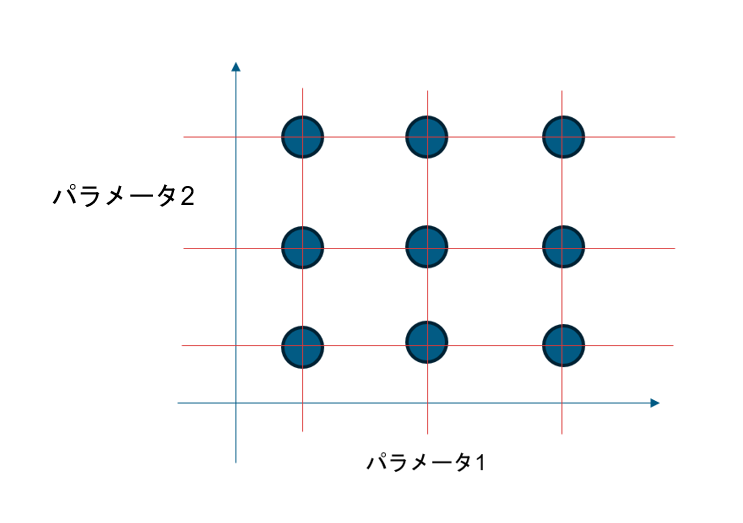
この手法ではパラメータの数だけ組み合わせを総当たりで計算していくのでパラメータの数多くなると計算量が増えるため注意が必要です。
終わりに
今回ローンのデータを用いてデータ理解、データ整形、機械学習モデル作成、精度検証などのフェーズを踏まえて、紹介させていただきました。
機械学習を実際に行うといっても多くのプロセスをもとに成り立っているというこが分かっていただけたかと思います。
実際にコードを0から書いていくと、大変ですが、Dataikuを使えばノーコードでデータ整形から機械学習モデルの作成まで実行できます。
機械学習の勉強をするのにDataikuを用いるのもいいのかもしれません。


