【Dataiku実装事例】不動産価格予測をしてみる ①前処理編
(2024年6月に執筆)
はじめに
目的
ノーコードでデータ前処理や機械学習を行うことができるプラットフォーム「Dataiku」を使ってマンションの価格を予測してみました。このブログではDataikuでどうやって、何ができるかを紹介していきます。
使用データ
国土交通省が運営する不動産取引価格のデータを提供するWebサイト「不動産価格ライブラリ」から東京都の2016年から2018年の中古マンション等に分類されるデータを使ってマンションの価格を推定をしていきます。最終的には2019年の不動産取引価格を学習済みモデルで予測してみたいと思います。
また追加のデータとして東京都の駅の座標データも使用します。
参考文献
Tableauで始めるデータサイエンス
著:岩橋 智宏、今西 航平、増田 啓志
出版社:秀和システム
出版年:2019
この本の中ではTableau prep(データ整形ツール)を用いてデータ整形を施したあと、Tableauの機能であるTabpyを用いて機械学習を実装するというパートがあります。
今回はこのパートを参考にしながら、アレンジを加えてDataiku上で分析をしていきたいと思います。
Dataikuを使ってマンション価格予測をする
1.とりあえずデータを見てみる。
不動産取引価格データをクリックするとテーブルデータが表示されます。
今回使用するデータは以下のデータなのでそれ以外の列は除外していきます。
不動産取引価格データ
| データ名 | 説明 |
| 市区町村名 | 属する区、もしくは市 |
| 地区名 | 区、市に続く町名 |
| 最寄駅:名称 | 物件の最寄り駅名 |
| 取引価格(総額) | マンションの価格、今回ではこのデータが目的変数 |
| 間取り | マンションの間取り |
| 面積(㎡) | マンションの面積 |
| 建築年 | 建築された年 |
| 建ぺい率(%) | 敷地面積に対する建築物の建築面積の割合 |
| 容積率(%) | 建物の総床面積の敷地面積に対する割合 |
| 取引時期 | 取引が行われた時期 |
| 改装 | 改装が行われたかどうか |
| 最寄駅:距離(分) | 最寄駅からの距離が徒歩何分か |
| 名前 | 駅の名称 |
| 住所 | 駅の住所 |
| 経度 | 駅の経度 |
| 緯度 | 駅の緯度 |
| 東京駅からの距離 | 東京駅を基準とした駅の距離 |
2.前処理を行う。
フローから不動産取引価格データ(フローの中では「2016-2018price_data」と名付けたデータ)を選択し、右側の「+」ボタンをクリックし「ビジュアルレシピ」の「準備(prepare)」を選択しデータの整形を行っていきます。
ビジュアルレシピ
ビジュアルレシピを使うことでデータセットの結合や重複削除、またはデータに対しての前処理や特徴量生成を行うことができます。アクションの中にはビジュアルレシピだけではなくPythonやSQL、Rなどを使った処理ができる「コードレシピ」、LLM を使ってRAGなどを作成する際に使用する「LLMレシピ」などが存在します。
特徴量生成
次に特徴量を作りたいと思います。建物が建てられた年を表す建築年という特徴量を持っています。この建築年という特徴量と取引が行われた年と時期が記載されている取引時期の特徴量を使って築年数という特徴量を持たせたいと思います。
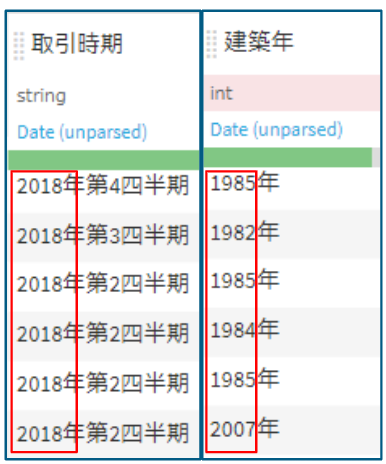
「取引時期 ー 建築年」で築年数を求めることができますがデータには文字も入っているので準備レシピで様々な処理をして築年数を作成したいと思います。
- Step1 – 建築年の「年」を外す
「ステップを追加」から検索窓に「置換」と入力。候補に出てきた「検索と置換」を選択します。
「列」に建築年を選択。出力列は空欄にすることで上書きしてくれるので空欄にします。(もし新しいカラムにしたいときは列名を記入することで新しい列でデータを保持します)
置換の追加をクリックすると変換したい文字を聞かれるので変換元を「年」、変換後を空欄にします。
これにて建築年のデータが数字として扱えます。
- Step2 – 取引時期の年数だけを取り出す
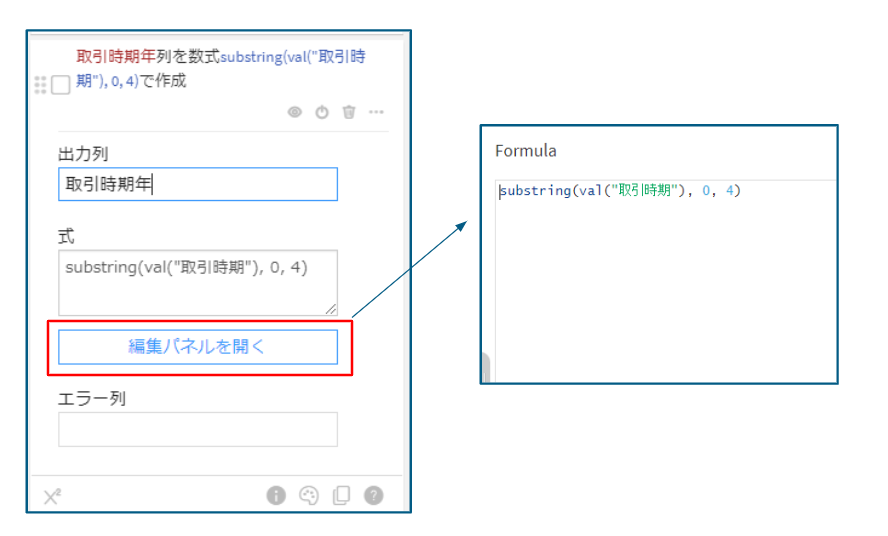
「ステップを追加」から検索窓に「式」と入力。候補に出てきた「式」を選択します。
出力列に「取引時期年」と入力し、「編集パネルを開く」をクリックします。
このステップではDataiku専用の式を書くことで列の操作が行えます。
今回はここに「substring(val(“取引時期”), 0, 4)」と書きます。
関数の説明
substring()…列から文字の抽出を行う関数 引数は、substring(抽出したい列、始まりの文字の位置、終わりの文字の位置)となっています。
val()…指定された列の値を出力します。
式が書けたら右上の適用を押します。これで取引時点の年度だけのデータが取れました。
- Step3 – 築年数を計算する
もう一度式ステップを作成し、編集パネルから「取引時期年 – 建築年」を行います。
「val(“取引時期年”) – val(“建築年”)」と書きます。
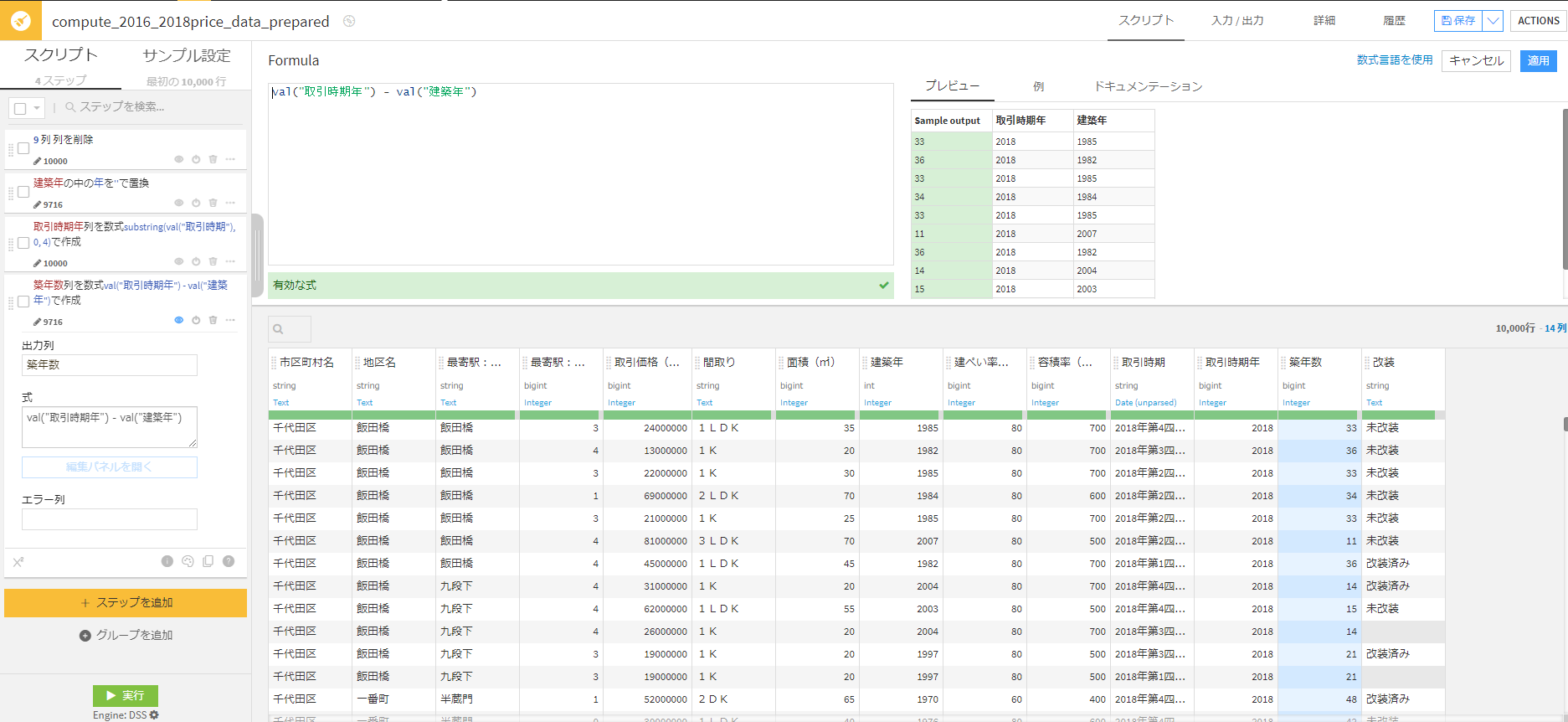
これにて「築年数」という新しい特徴量を作成することができました。
データ結合
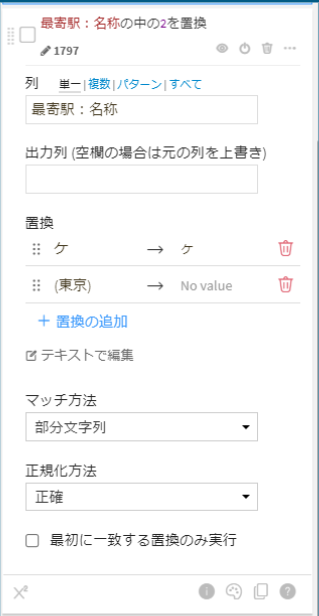
次のフローでデータの結合を行うのですが、市ヶ谷や幡ヶ谷の「ヶ」の文字が違っていることがあるので先ほど紹介した「検索と置換」で最寄駅:名称の「ケ」を「ヶ」に変換。また名称の後に「(東京)」と入っていることがあるのでこちらも消してしまいます。
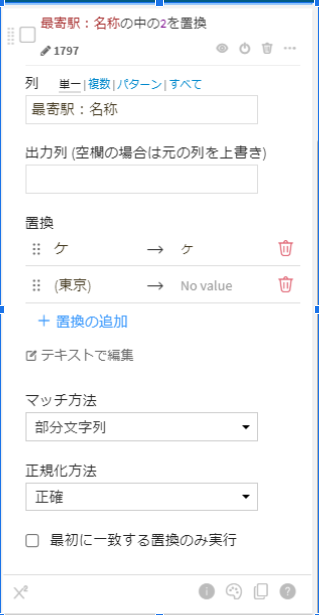
最後に左下の「実行」ボタンを押すことで元データに一連の処理を施したデータがフローに追加されます。
次にstation_dataを2016-2018price_dataと結合する前に、2016-2018price_dataに駅の名前は名称だけですが、stationデータは「~駅」となっているのでstation_dataを準備レシピから先ほどと同様に「駅」を消してしまいましょう。
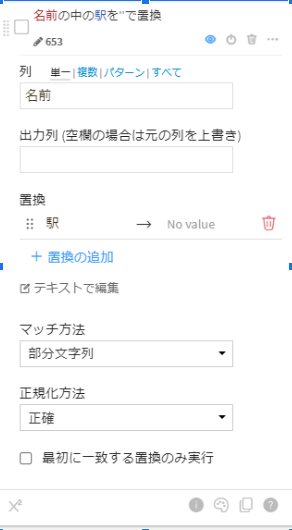
station_dataの整形は以上なので実行をして次の結合フローに移りましょう。
現在フローはこんな感じです。準備レシピを施したデータ同士を結合させていきます。
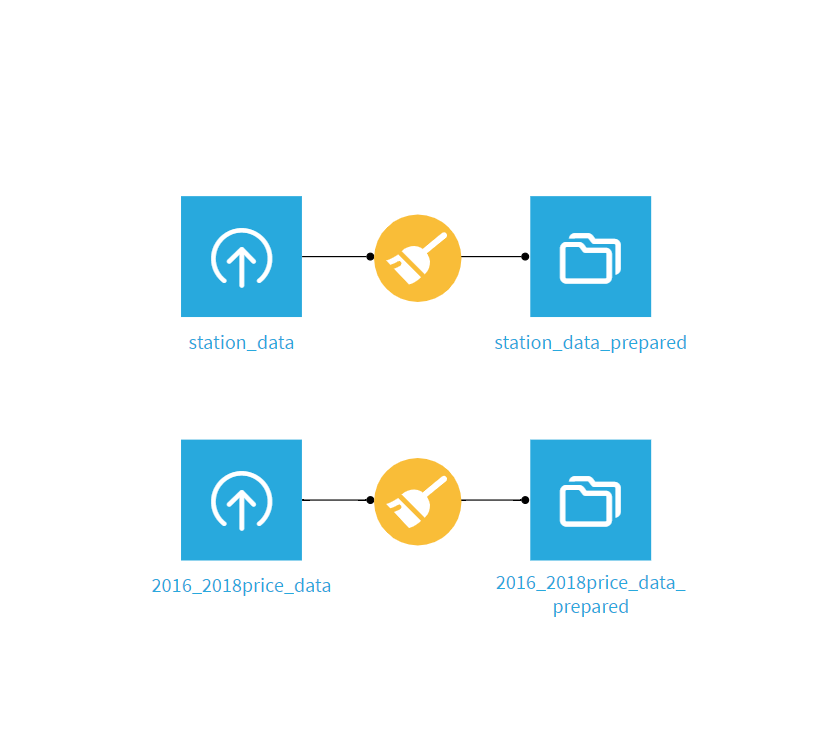
2016-2018price_data_preparedをクリックし、アクションから「結合」レシピを選択。
input datasetsにstation_data_preparedを追加し「Create recipe」を選択。
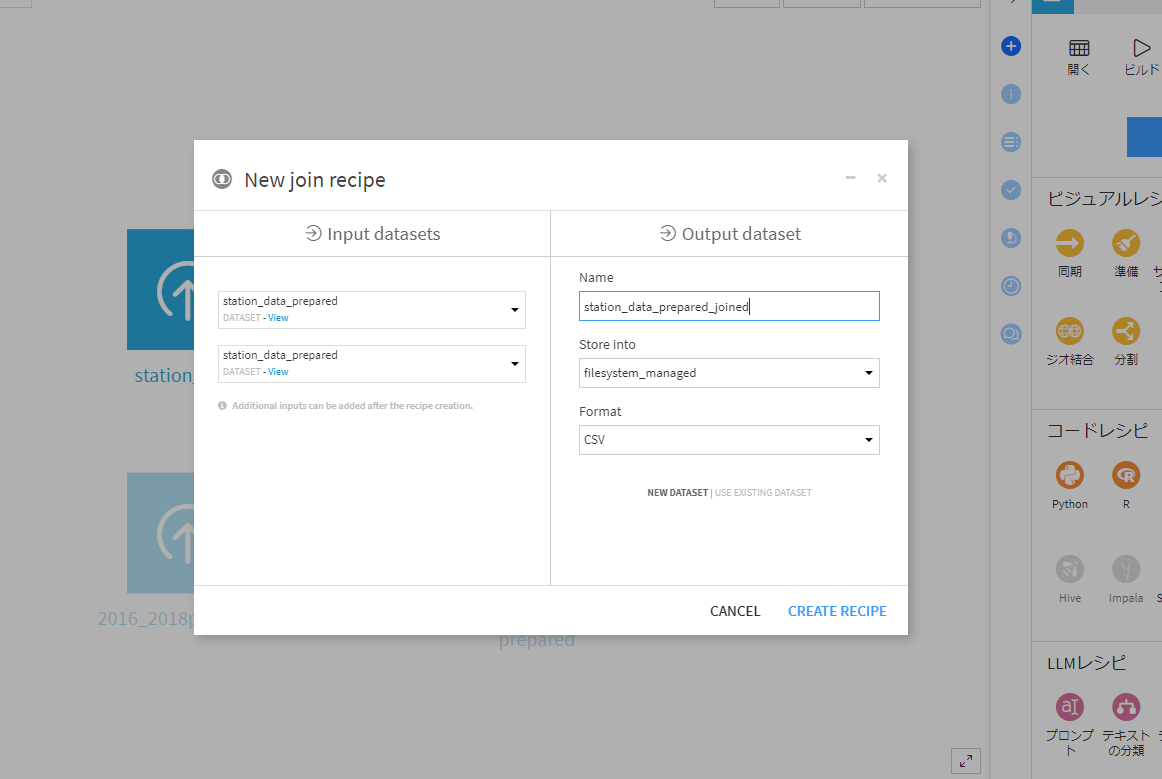
2016_2018price_data_preparedデータの「最寄駅:名称」とstation_data_preparedデータの「名前」を結合キーとして結合します。
今回は結合の方法は「inner join」を選択します。
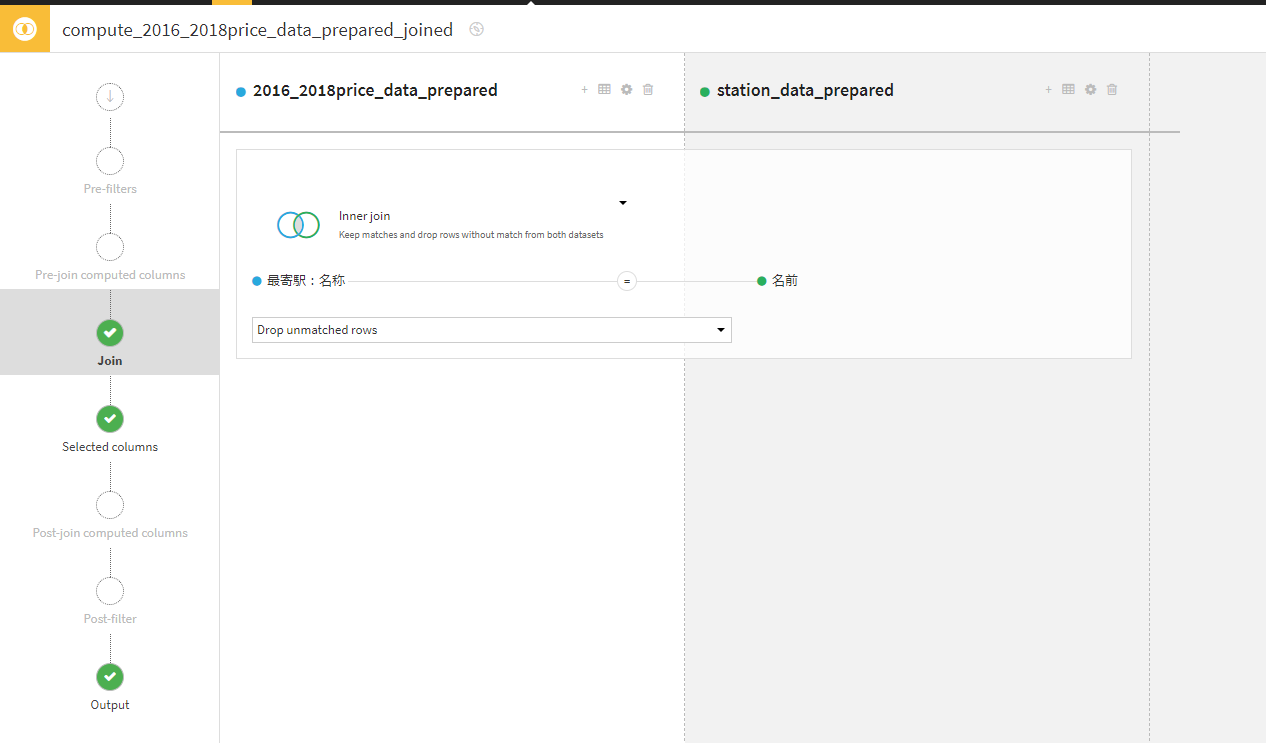
欠損値削除
欠損データを削除することで、分析の精度が向上し、一貫性のあるデータセットを確保できます。これにより、モデルの性能が向上し、信頼性の高い結果が得られます。データ処理も簡素化され、迅速に進めることが可能になります。
今回は面積、築年数列が欠損している行は削除します。
カラムの名前のところを右クリックし「値のない行を削除」を選択します。
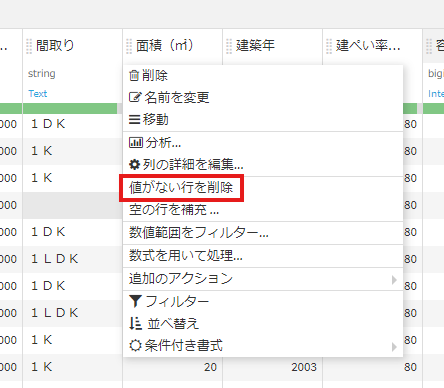
統計ワークシート機能
Dataikuの統計機能を使ってデータの分布や関係性を見ていきます。
「統計」ボタンをクリックし、「Automatically suggest analysis」を選択すると統計情報を提案をしてくれます。まず全変数の単変量解析を見てみます。「Univariate analysis on all variables」を選択してください。
これにて一つのカラムのデータの平均や、中央値などの代表値、分布の散らばり方などが分かります。
データを見てみると、価格と面積のデータの分布が左に偏っていることがわかります。
外れ値除去
どうやら非常に大きな金額のデータや大きな面積のデータがあるようです。こういった外れ値は意味のあるデータであったりするので慎重に扱わなければいけませんが、今回は外れ値は除外をして一般的な取引価格、面積の物件を予測するようなモデルを作成していきたいと思います。
外れ値を除外するには準備レシピにて行います。
外れ値を除外したい列データの名前を右クリックし「分析」を押してください。
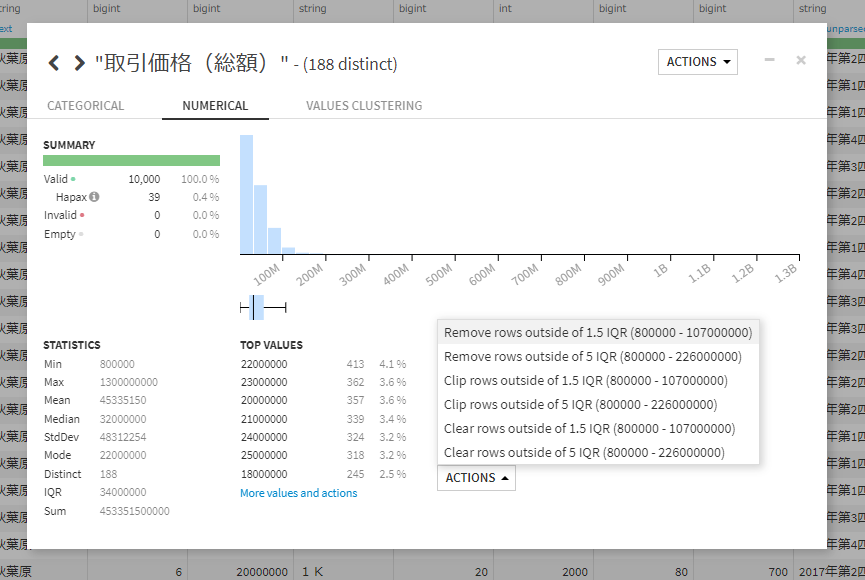
ここで「ACTIONS」を押すと「Remove rows outside of 1.5IQR」という選択肢があります。
これは四分位範囲法と呼ばれる外れ値を除外する統計的手法です。詳しい説明は省きますが、これを行うことでデータの範囲を狭め、極端な値の影響を減らします。これにより、より信頼性の高い分析が可能になります。
※Dataikuはデータのレコードが1万件以上ある場合最初の1万件をサンプルデータとしてとってきています。なのでこの外れ値の処理は最初の1万件を使った外れ値の計算になります。もし最初の1万件に価格の少ないデータが多い場合、5万件でデータをみると外れ値といえないデータが除外されてしまうのでランダムサンプリングをすることでデータのバイアスを減らしたり、全件表示したうえで外れ値の処理をするようにしましょう。
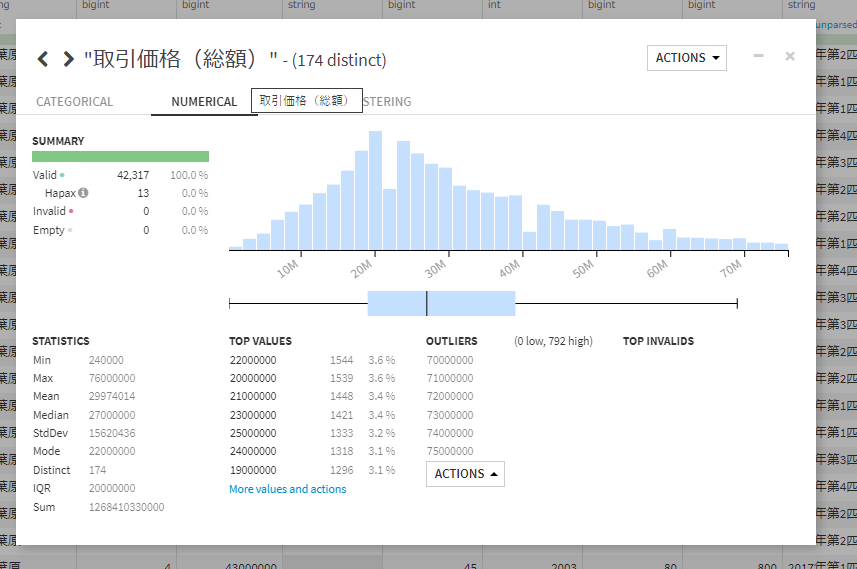
これにて外れ値処理ができました。
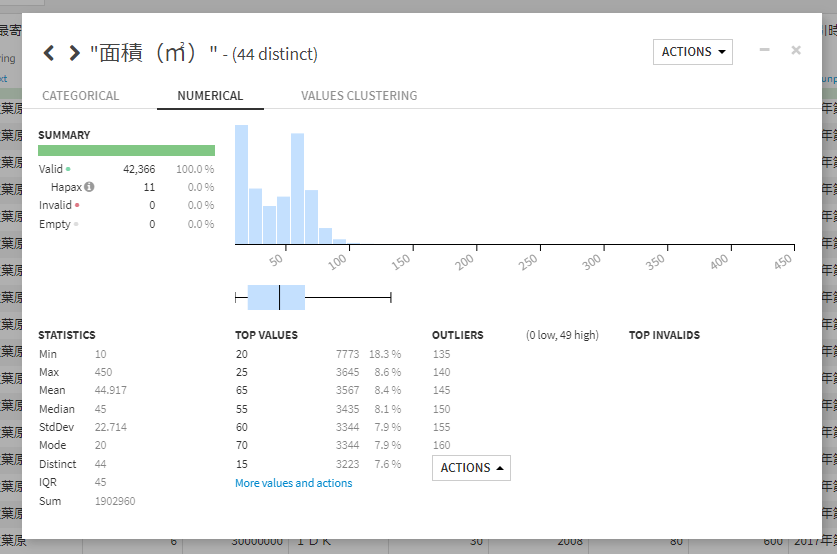
同様に面積においても同じく外れ値除去の処理をします。
処理前
処理後
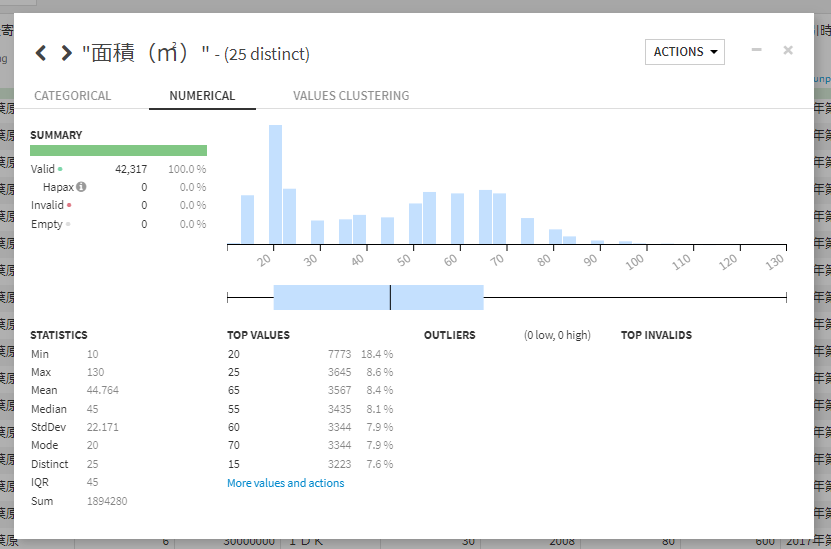
ここで築年数の分析もしてみました。
分析からデータの分布、最頻値、最大値、最小値、平均などの値を見てみます。
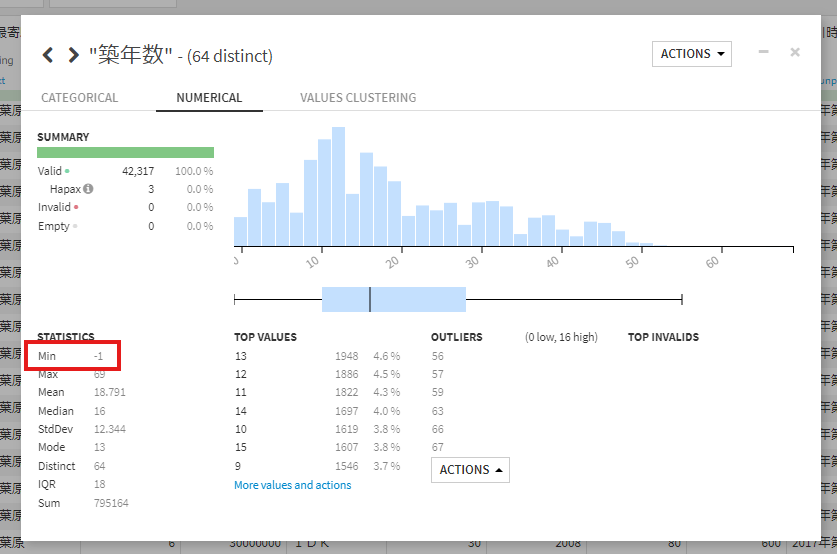
見てみると最小値がマイナスになっていました。本来ならば築年数がマイナスになることはないのでフィルターをかけてみてみます。
(フィルターはフィルターのかけたい列をクリックすると出てきます。)
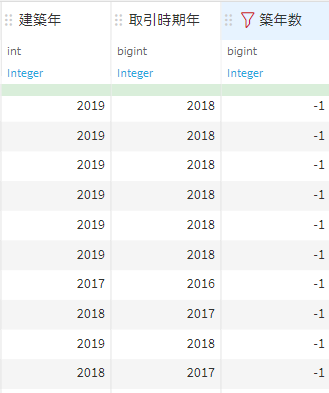
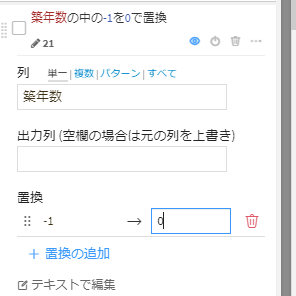
データを見てみると建築されるよりも先に取引が行われていたため築年数がマイナスになっていたようです。このデータの築年数は0年と考えて良さそうなので-1を0に置換しておきます。
ここまでのフローを見てみましょう。
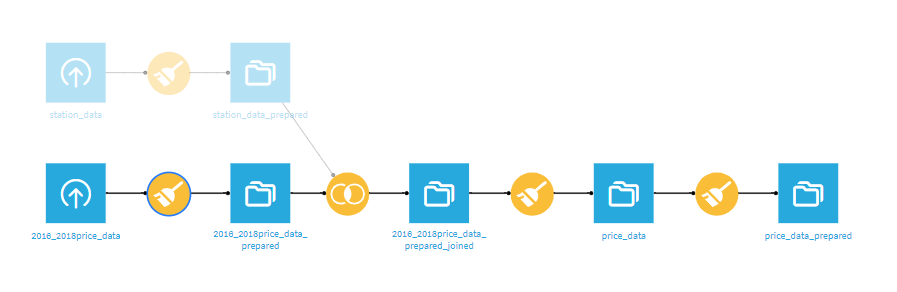
現在このようなフローになっています。
これにてモデルを作るためのデータセットが作成できました。この時点で最終データセットは42,317レコード存在します。
前処理終了
【不動産価格予測】Dataikuを使ってノーコードで東京都のマンション価格を推定をする ②機械学習編
Dataiku導入を考えている方へ
KeywalkerはDataikuのパートナーとしてDataikuの導入支援を行っています。データ分析による業務改善にご興味がある方は是非、Keywalkerにご連絡ください。
またDataikuがどのようなものか知りたいという方向けにDataiku体験会をDataiku社と共同で行っておりますのでそちらに興味がある方もご連絡ください。
Keywalker 問い合わせフォーム:https://www.keywalker.co.jp/inquiry.html
