【Dataiku実装事例】不動産価格予測をしてみる ②機械学習編
(2024年6月に執筆)
(2024年6月に執筆)
ここからは整形されたデータセットを使って機械学習モデルを作成していきます。
モデルを学習するための訓練データと汎化性能を測るテストデータにランダムに分けたいと思います。
Dataikuではビジュアルレシピの「分割」レシピを使います。
「アクション」から「ビジュアルレシピ」の「分割」を選択します。
選択しウィンドウが現れたら、今回は学習するデータを「train_data」、検証用データを「test_data」と名前を付けてデータセットを作成します。
レシピに入ったら、「Random dispatch data」を選択します。これは分割割合を決め、比率に従ってランダムにデータを格納させていきます。
今回は訓練データとテストデータの割合を7:3にしたいと思います。
さて、モデルの学習に使う訓練データを用意できました。ここから機械学習モデルを作成していきます。
train_dataのアクション、ビジュアルレシピの上にある「ラボ」を選択してください。
ラボ機能
Dataikuのラボ機能を使うことで機械学習モデルの研究を行うことができます。機械学習アルゴルズムの選定やハイパーパラメータチューニングの手法の選定など機械学習に関する様々なオプション設定を行えます。 また学習済みアルゴリズムからの情報抽出として特徴量重要度や部分依存、サブグループ分析などモデルの解釈も容易に行うことが可能です。
次に「AutoML予測」を選択します。目的変数を聞かれるので今回はマンションの価格を知りたいので「取引価格(総額)」を目的変数にします。
名前は「マンション価格予測モデル」としました。
試行錯誤をして、下記条件でのモデルを採用することにしました。
アルゴリズム:LingtGBM
ハイパーパラメーターチューニング:探索方法はグリッドサーチで交差検証法(5分割)を用いる。
目的関数:R2スコア
目的変数:取引価格(総額)
説明変数:面積、築年数、東京駅からの距離、市区町村名、最寄駅からの距離(分)、改装
Train / Test setにおいて「Explicit extracts from two different datasets, one for train, one for test」を選択しTest setを分割しておいた「test_data」に設定。
結果:
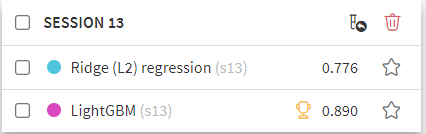
モデリングの比較対象としてL2回帰でも学習させてみました。
L2回帰と比べてもLightGBMのR2スコアが高いことが分かります。
次に、LightGBMモデルをクリックしモデルの振る舞いを見てみたいと思います。
特徴量重要度をまず見てみます。
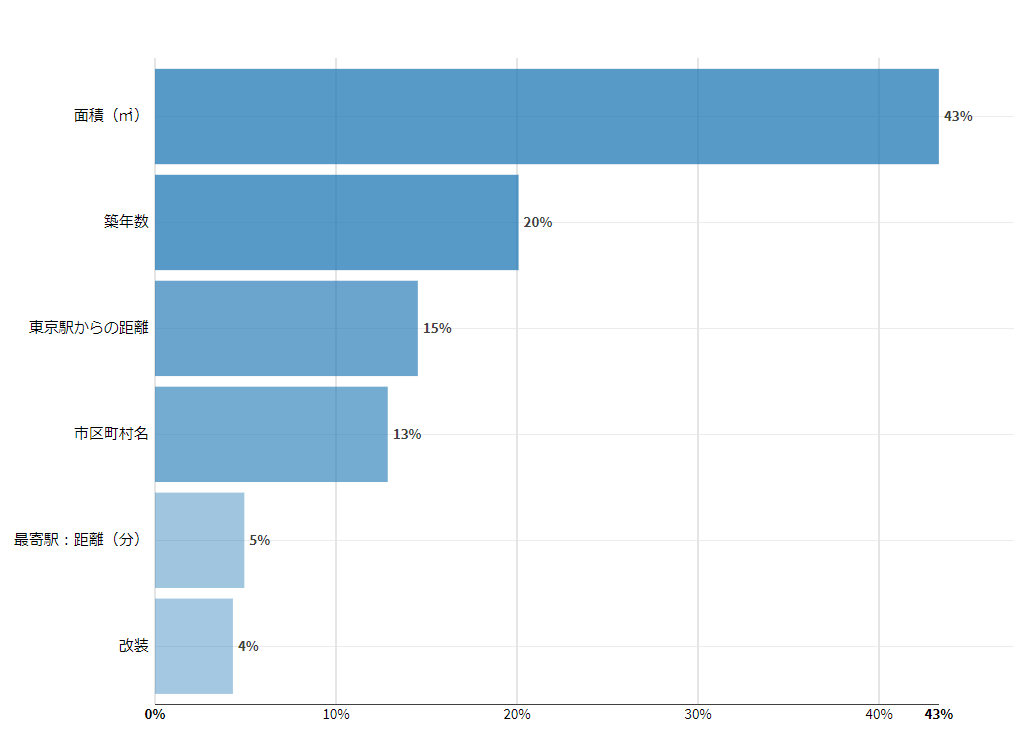
画像からわかるように面積が取引価格に大きく影響を与えていることが分かります。また次に築年数、東京駅からの距離が予測結果に影響を与えているようです。
今、モデルが予測値を出す過程でどの特徴量の影響を高く受けているかかが分かりました。つぎに一つの変数に絞り、その変数の値と予測値の関係性を見てみるためにPartial dependece(部分依存)を見てみます。
PDを見ることで1つの特徴量と予測値の関係が分かります。
ここでは一番予測値に影響を与えていた「面積」を見てみます。
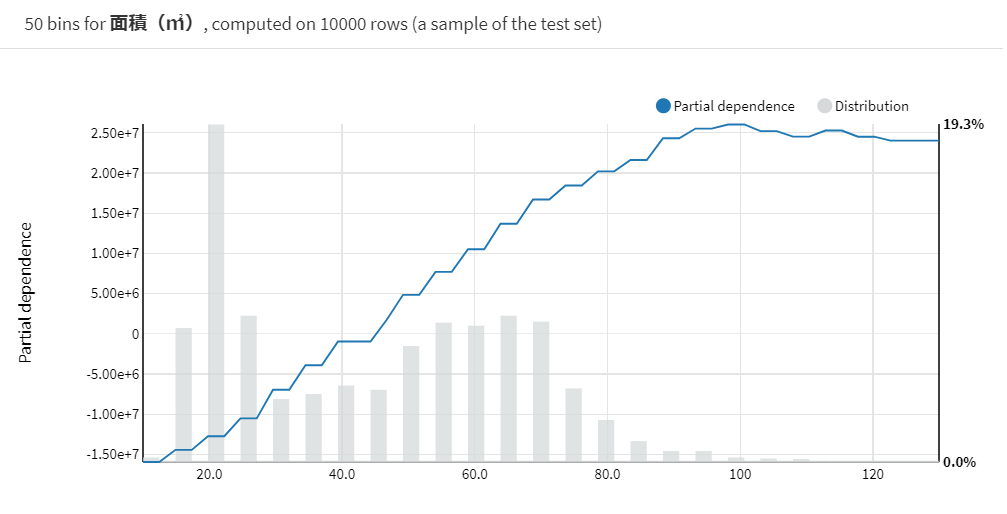
このグラフは横軸を面積、縦軸をその面積における予測値の平均を指しています。
このグラフからわかるように面積が大きくなるにつれて予測値が大きくなっていることが分かります。これは実世界のパターンに沿っているように感じます。
ここではもっと細かく精度を見ていきます。
Subpopulation analysisを見ることである特徴量を細かくして精度を見ることができます。
また面積についてみてみましょう。
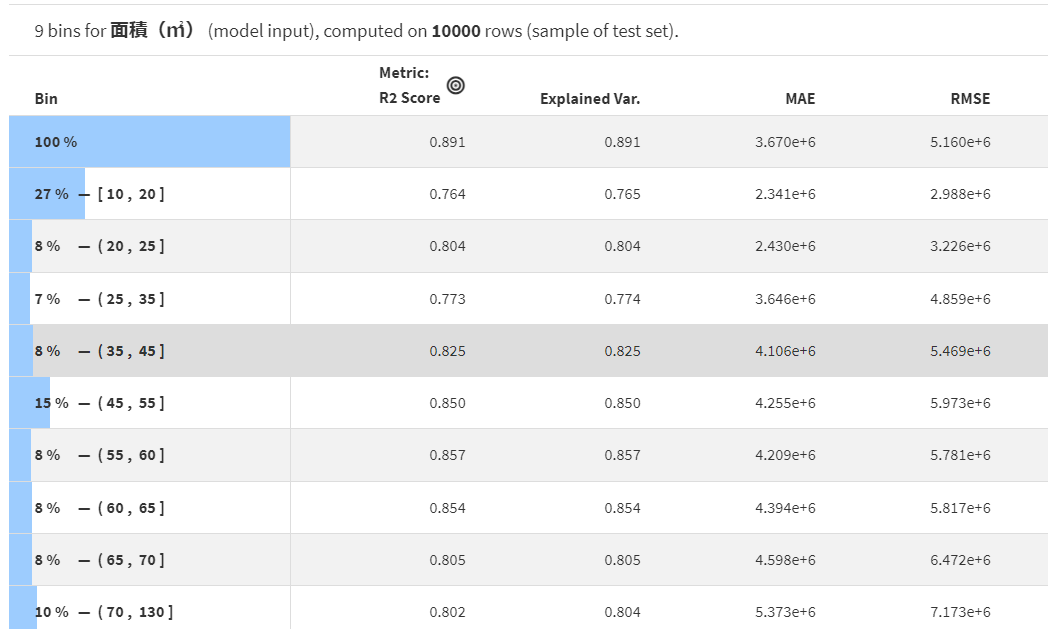
上の画像からわかるように面積の値を分割して精度を見ることが可能です。
このグラフを見るに55~60㎡の物件に対しての予測精度が高く、10~20㎡の物件に対する制度が低いことが分かります。
さてラボにてモデルが完成したためモデルをデプロイした後に2019年度のデータに対して予測を行ってみましょう。
ラボの中の今回作成したLightGBMのモデルをクリックしページが遷移したら右上にあるデプロイボタンを押しましょう。
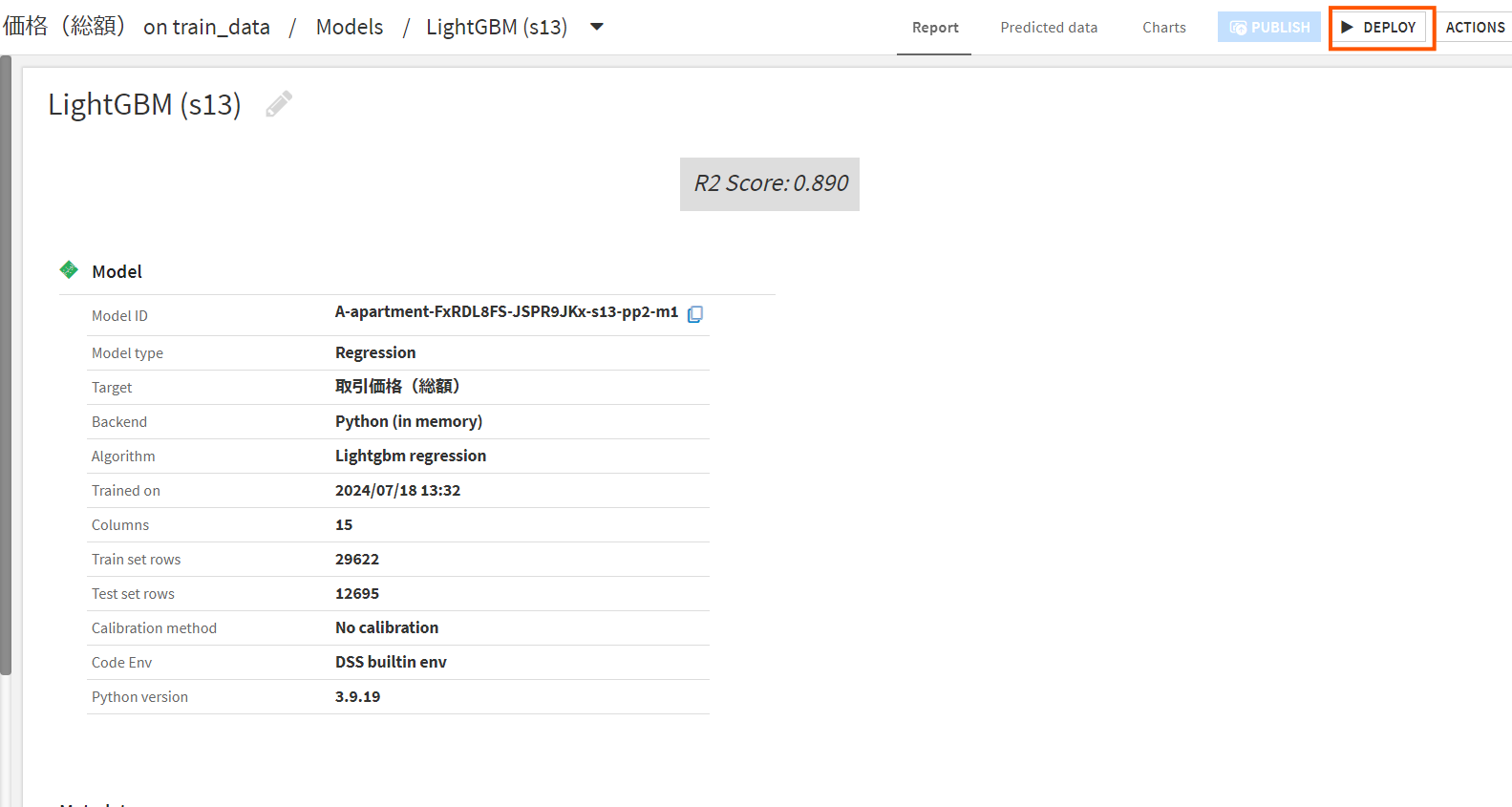
表示されたポップアップのTrain datasetを「train_data」, Test datasetを「test_data」に設定し実行を行います。
実行するとこのようなフローになります。
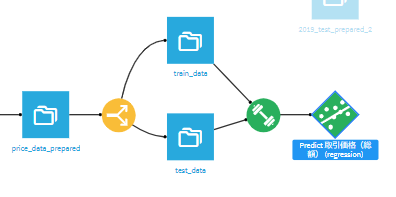
次に、predict 取引価格(総額)(regression)を選択するとアクションに「評価」というレシピが表示されるのでそちらを選択します。
Evaluation datasetにこれまでの前処理を施した2019年取引データをセットします。
(これまでのデータセットに行っていたレシピをコピーし、入力を変えることで手間なく前処理や結合ができます。)
Output Datasetに行ごとに予測値を出してくれるpredictionとモデルがデータセットに対しての評価指標が見れるmetricsを設定し「CREATE RECIPE」をクリック、遷移したページで「実行」をクリックし出力します。
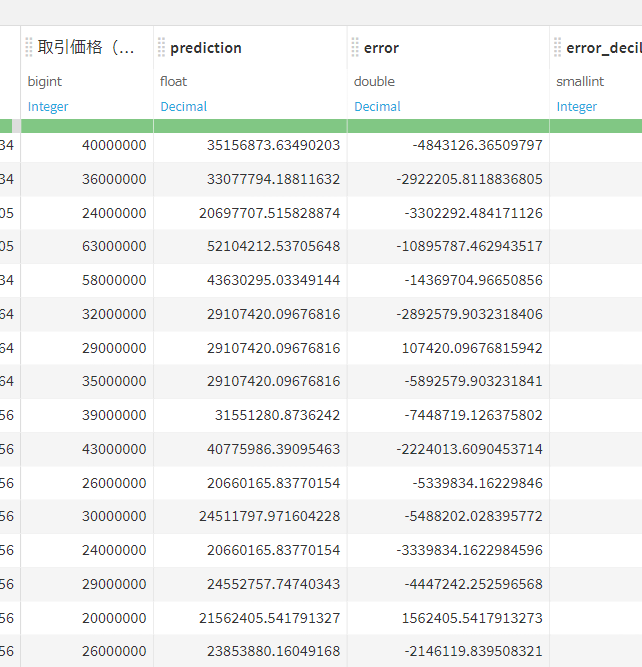
結果:
Prediction 予測値や実測値と誤差、その他情報を出してくれます。
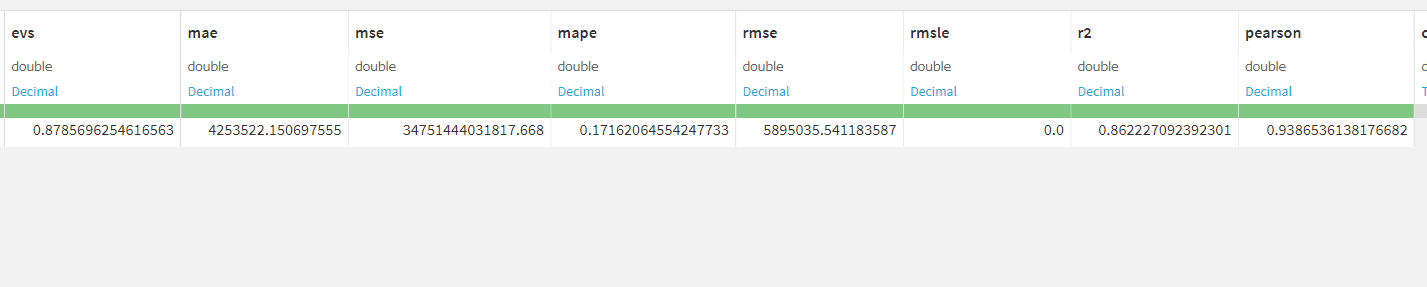
Metrics 2019年建物取引データにおいてのモデルの評価指標が記されています。
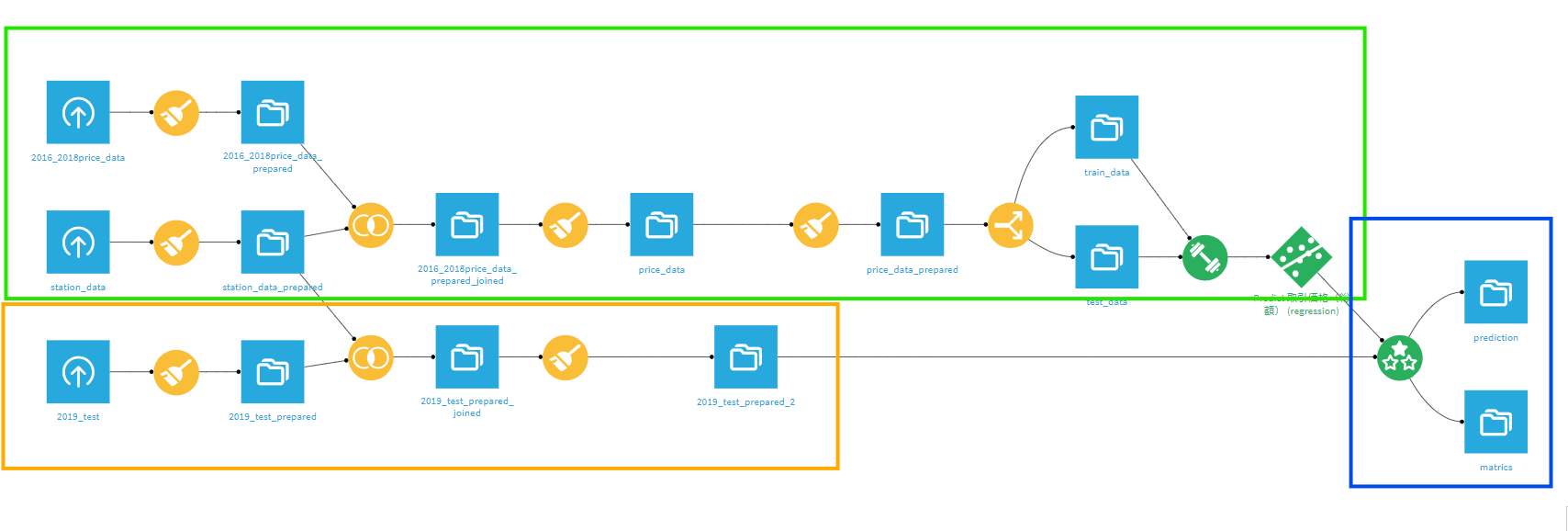
緑色エリア:2016~2018年のマンション取引データと駅データを結合し前処理を行った後モデルの構築を行っている。
黄色エリア:2019年マンション取引データと駅データを結合し、前処理を行っている。
青色エリア:2016-2018年マンション取引データをもとに作ったモデルで2019年データに対して予測を行っている。
Dataikuを使ってノーコードで前処理、結合、機械学習モデルの構築を行いました。
コードを書かなくていいのでコーディングをする際に直面する環境設定の問題や、特殊な関数の理解を気にしなくていいのが楽だと感じました。
前処理も簡単かつ様々な機能があるため少し複雑な前処理も楽にできました。
またフローのおかげで自分が行った処理を視覚的にとらえることができるので振り返る際にとても便利です。
コードレシピもあるのでエンジニアの方も処理を簡単に行えますし、コードを書けない人も前処理からモデル構築まで行うことができます。
また、今回は触れていませんが、フローの中に説明文を記載する、Wikiを作成する、他メンバーとディスカッションするなど、チームでモデルを開発する際に便利な機能がたくさんあります。
KeywalkerはDataikuのリセラーパートナーとしてDataikuの導入支援を行っています。データ分析による業務改善にご興味がある方は是非、Keywalkerにご連絡ください。
またDataikuがどのようなものか知りたいという方向けにDataiku体験会をDataiku様と共同で行っておりますのでそちらに興味がある方もご連絡ください。
Keywalker 問い合わせフォーム:https://www.keywalker.co.jp/inquiry.html
