はじめに
SIGNATEの 【練習問題】銀行の顧客ターゲティング をDataikuで実施しました。
本記事ではDataikuを用いて、ノーコードで二値分類を行う手順について解説します。
概要
この課題では、銀行の顧客属性データや過去のキャンペーンでの接触情報をもとに、顧客が口座を開設するかどうかを予測します。
使用データ
使用するデータは、以下の2種類です。(データのダウンロードはこちら)
- 学習用データ(train.csv)
- 評価用データ(test.csv)
評価指標
本コンペティションでは AUC(Area Under the Curve) を指標としてモデルの制度を評価します
AUCとは?
分類モデルの予測性能を評価する指標で、値が1に近いほど精度が高いことを示します。

投稿方法
提出するファイルは、以下の形式の csv(ヘッダなし) で作成します。
| id | 申し込み有無 |
| 1 | 0 |
| 2 | 1 |
| … | … |
1列目にid、2列目に申し込み有無を記載し、SIGNATE上で投稿します。
使用レシピ一覧
本タスクでは、Dataikuの以下のレシピを使用しました。
Visual recipes(データ処理)
- Stack:複数のデータセットを統合(ユニオン)
- Prepare:様々な前処理を実施
- Delete/Keep columns by name:不要な列の削除または必要な列の抽出
- Formula:数式を記述してデータを加工
- Fill empty cells with fixed value:欠損値を特定の値で補間
- Unfold:カテゴリ変数をone-hot encoding(ダミー変数化)
one-hot encoding(ダミー変数化)とは?
カテゴリデータを機械学習モデルが扱える数値データに変換する方法です。
サンプル:色のカテゴリデータ
| 色 |
|---|
| red |
| blue |
| yellow |
one-hot encoding(ダミー変数化)後
| red | blue | yellow |
|---|---|---|
| 1 | 0 | 0 |
| 0 | 1 | 0 |
| 0 | 0 | 1 |
one-hot encodingを行う理由
- ほとんどのモデルは カテゴリデータをそのまま入力できない ため
- 数値の大小による影響を防ぐため
- 例えば、
red=1, blue=2, yellow=3のように数値を割り当てると、モデルが「blue(2)は red(1)より大きい」など 誤った関係を学習 してしまう。
- 例えば、
- モデルの精度向上のため
- Split:データセットを分割
Lab(機械学習)
- AutoML Prediction:機械学習モデルを自動構築
Other recipes(その他)
- Score:学習済みモデルを用いて予測データのスコアリング
ここまでで事前知識は完了です。では、さっそくDataikuを使って二値分類を実施する手順を説明していきます。
ハンズオン
データ理解
プロジェクトの作成
Dataikuホーム画面の右側にある「NEW PROJECT」をクリックしてプロジェクトを作成します。
データのインポート
- 「IMPORT YOUR FIRST DATASET」をクリックします。
- 「New dataset」の画面から「Upload your files」を選択します。
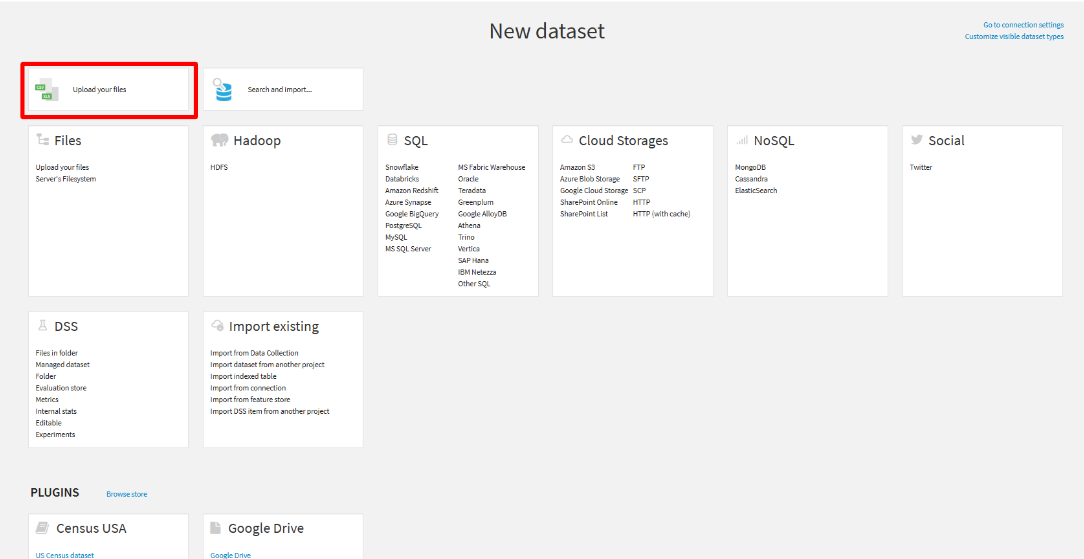
- 「SELECT FILES」をクリックし、
train.csvとtest.csvを選択します。(ctrlキーを押しながら複数のファイルを選択可能です。) csvファイルが選択出来ていることを確認し、「CREATE MULTIPLE DATASET」をクリックします。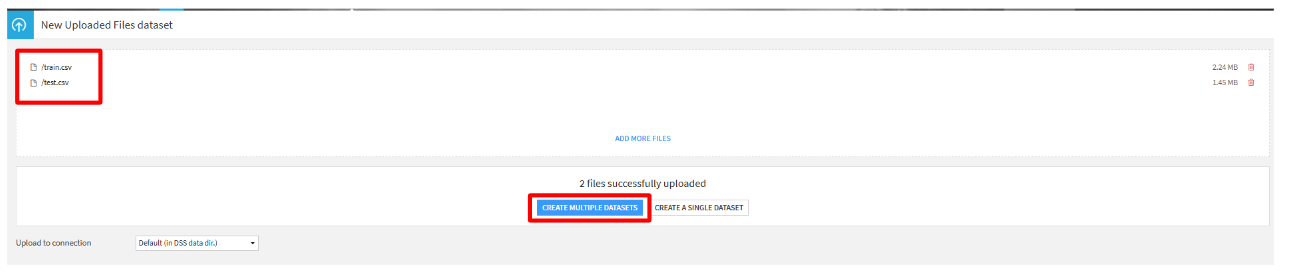
- 「New dataset name」を確認し、 それぞれ「CREATE AND NEXT」または「CREATE」をクリックします。


train.csv

test.csv

欠損値の確認
trainをクリックして、「Statistics」タブから欠損値等を確認します。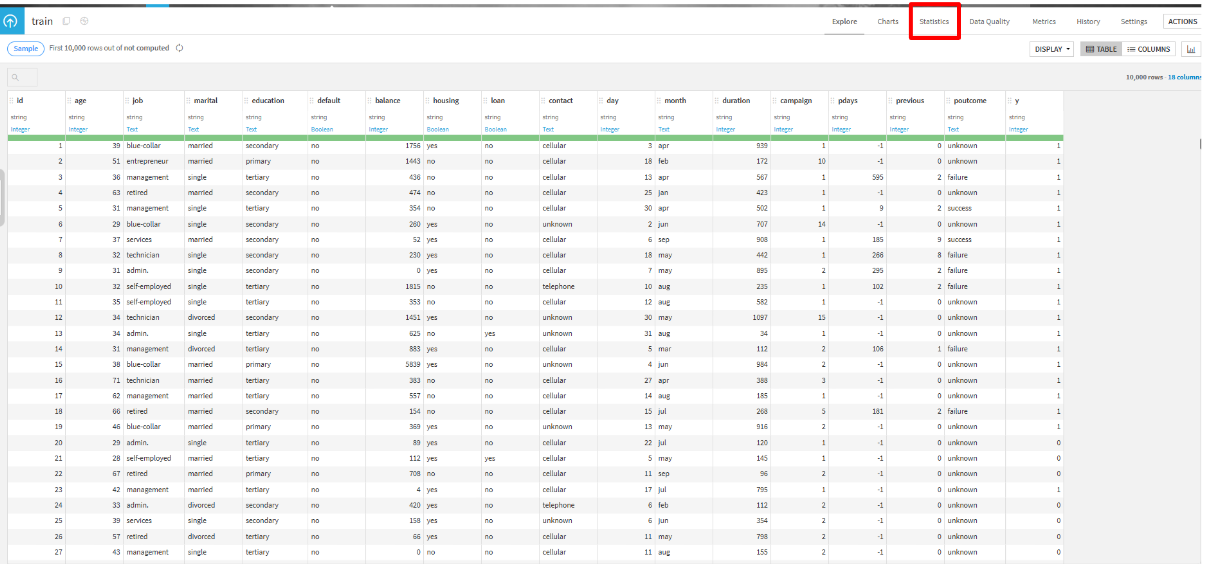
- 「CREATE YOUR FIRST WORKSHEET」をクリックします。
- Automated selectionの「Automatically suggest analyses」をクリックします。(簡単に統計分析ができます。)
- 今回は、Select features and let Dataiku suggest interesting cardsの「Univariate analysis on all variables」を選択して、「CREATE SELECTED CARDS」をクリックします。(欠損値の確認などが出来ます。)
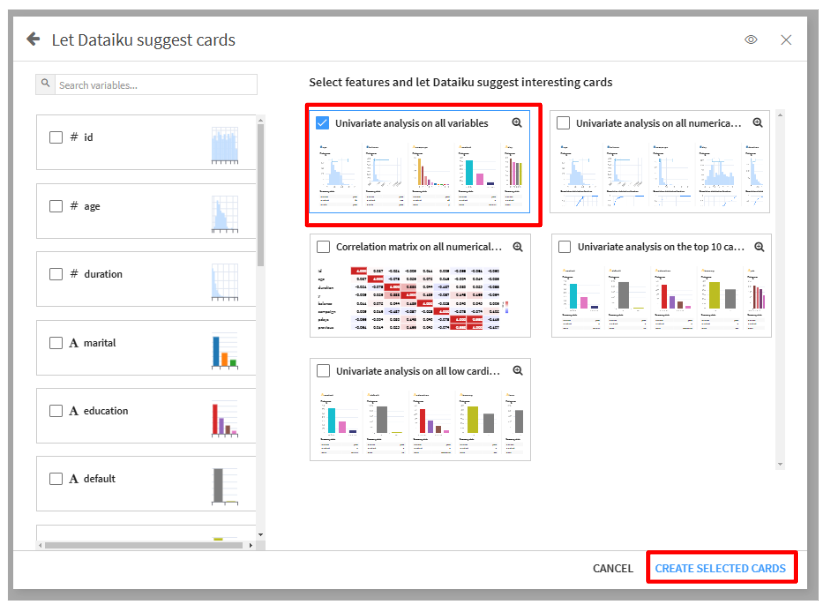
- 可視化された統計データを確認します。
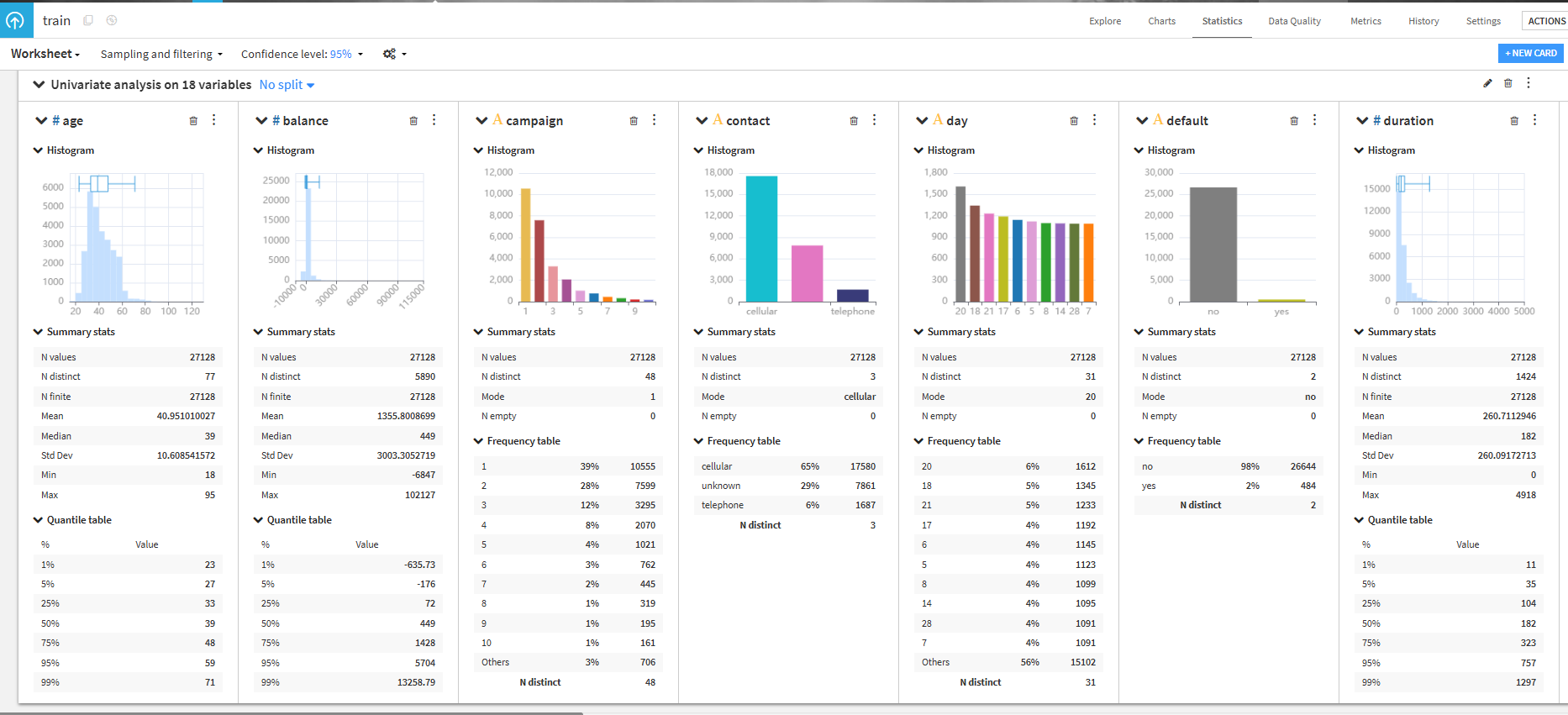



yと各列の相関を確認します。
- 右上の「NEW CARD」をクリックして、Automated selectionの「Automatically suggest analyses」をクリックします。
- Select features and let Dataiku suggest interesting cardsの「Correlation matrix on all numerical…」を選択して、「CREATE SELECTED CARDS」をクリックします。(相関行列を確認できます。)
- 可視化された相関行列を確認します。

duration、pdays、previousのそれぞれとyとの相関が少し高いことが確認できました。
カテゴリデータの可視化
欠損値や相関の確認ができたので、次は各カテゴリデータとyとの関係を確認します。
「Chart」タブをクリックして各グラフを作成します。

正解値データの分布

職種別申込み確率

教育水準別申込み確率

marital別申込み確率

default別申込み確率

housing別申込み確率

loan別申込み確率

連続データの可視化
- 再度「Statistics」タブに遷移します。
- previousを連続データに変換するために「︙」をクリックして、「Treat previous as continuos」を選択します。

yとの相関が高かったduration、pdays、previous を確認します。(列の並び順を変更しています。)

pdaysにマイナスの値があることが確認できました。
また、グラフと分布とMaxの行を見てみるとそれぞれ外れ値が存在していることが確認できます。
- これらの分析から以下の情報が分かりました。
- 職種別申込み確率:労働者でない場合に
yの確率が高い。unknownがデータとしてある。 - 教育水準別申込み確率:
unknownがデータとしてある。 - default別申込み確率:
noのほうがyが1である確率が高い - marital別申込み確率:
singleのほうがyが1である確率が高い - housing別申込み確率:
noのほうがyが1である確率が高い - loan別申込み確率:
noのほうがyが1である確率が高い
.png)
まとめ
ここまで、データのインポートから、欠損値の確認、相関行列の分析、そして可視化によるデータの探索までを行いました。Dataikuを活用することで、これらのプロセスをノーコードでスムーズに実施でき、データ分析に集中できる点が大きなメリットです。次回は、機械学習編としてモデル構築について詳しく説明していきます。