はじめに
SIGNATEの 【練習問題】銀行の顧客ターゲティング をDataikuで実施しました。
本記事では、Dataikuを用いて、ノーコードで二値分類を行う手順について解説します。
前回まで
前回は、データのインポートから、欠損値の確認、相関行列の分析、可視化を通じたデータの理解までを行いました。Dataikuを活用することで、これらの工程をノーコードで効率的に進めることができました。今回は、機械学習モデルの構築に焦点を当て、データの前処理、特徴量エンジニアリング、モデルの学習・評価を行います。
前処理
trainデータとtestデータの統合(ユニオン)
それぞれのデータを別々に前処理すると手間がかかるため、Visual Recipesの「Stack」を使用し、trainとtestを1つのデータセットに統合します。
trainを選択し、Visual Recipesの「Stack」をクリックします。- 「Inputs」に
trainとtestを選択して、「CREATE RECIPE」をクリックします。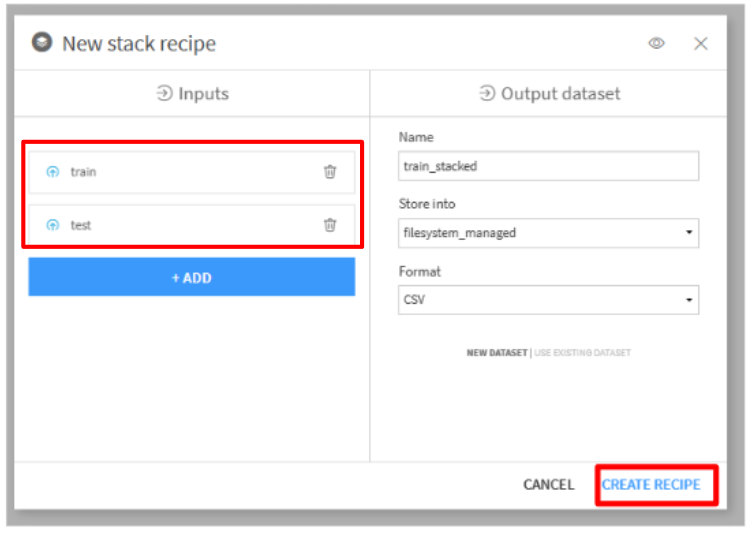
- 「Origin columns」タブから、設定を
ONに変更します。(最終的にtrainとtestに分割するため)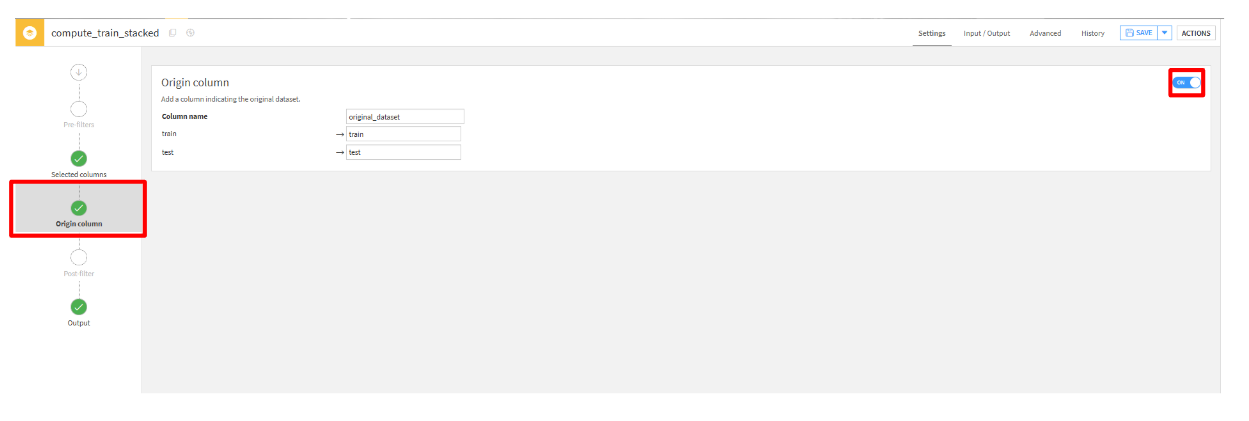
- 「Output」タブから、出力される列を確認して、「RUN」をクリックして実行します。
- 実行結果
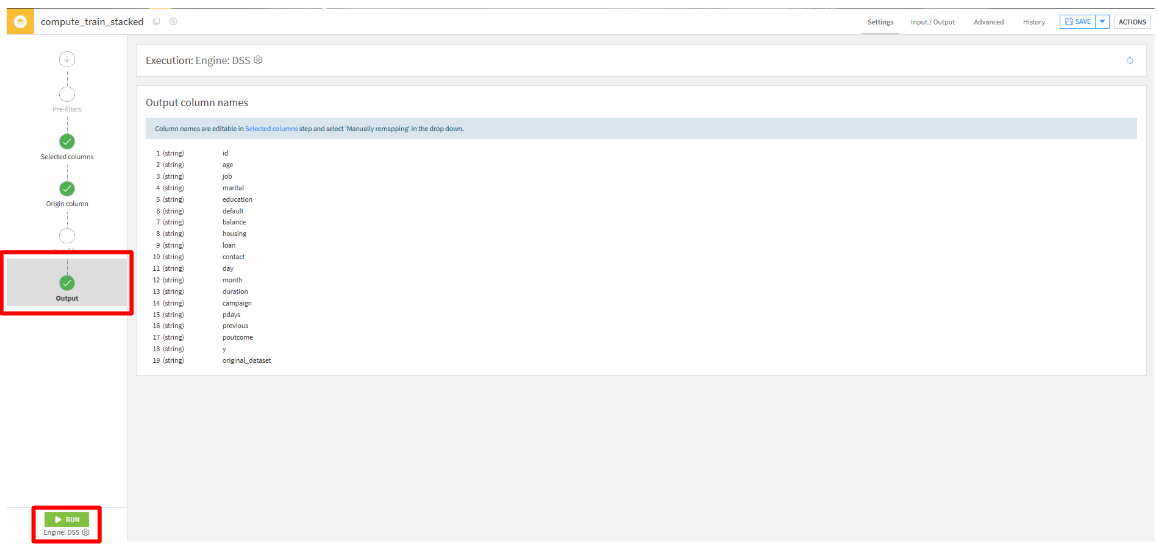
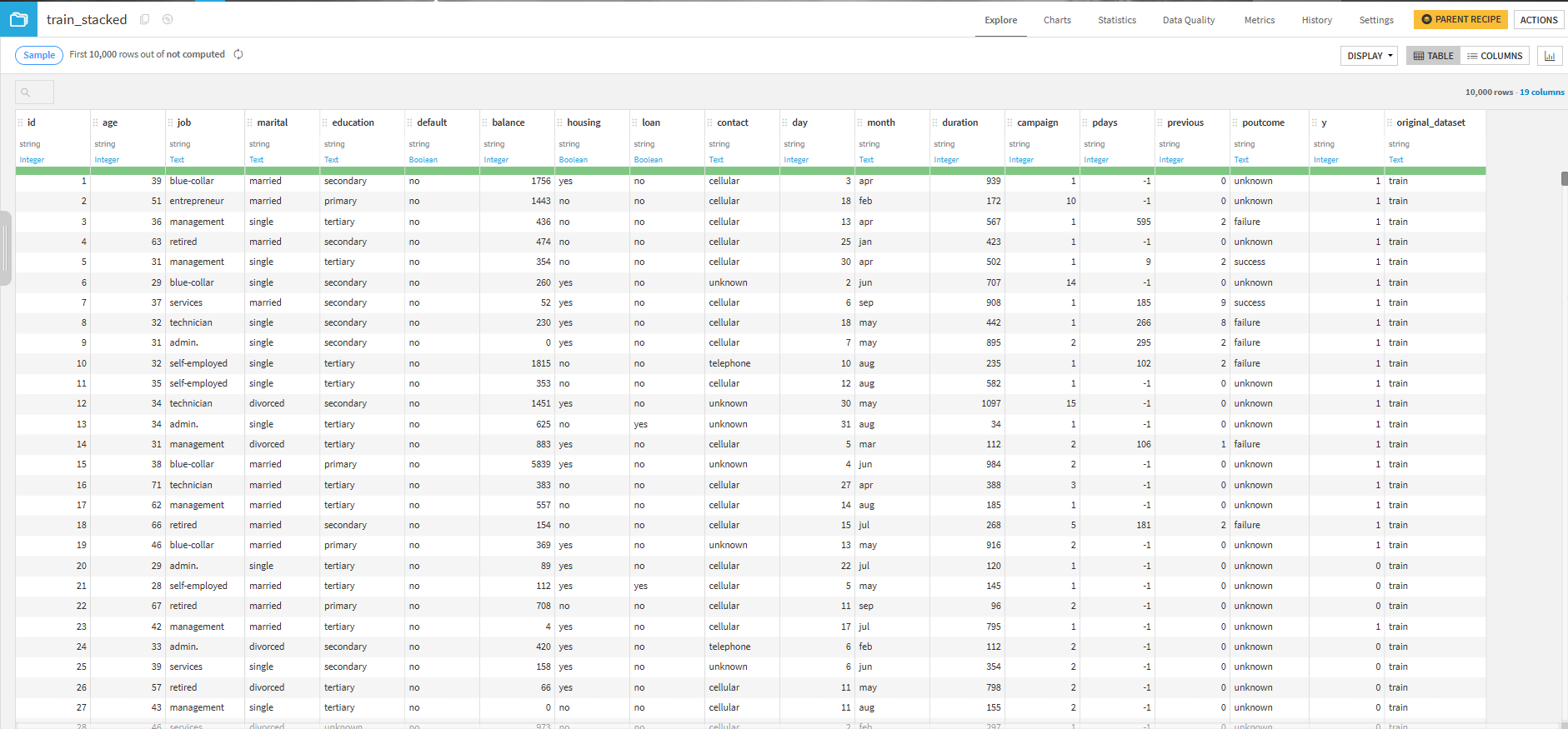



特徴量の選択
統合したデータに対して特徴量として使用する列を選択します。
今回は、分析したid, duration, pdays, previous, job, education, marital, default, housing, loanと目的変数であるy、統合データを判別するためのoriginal_datasetを選択します。
train_stackedをクリックして、Visual recipesの「Prepare」をクリックします。- 「CREATE RECIPE」をクリックします。
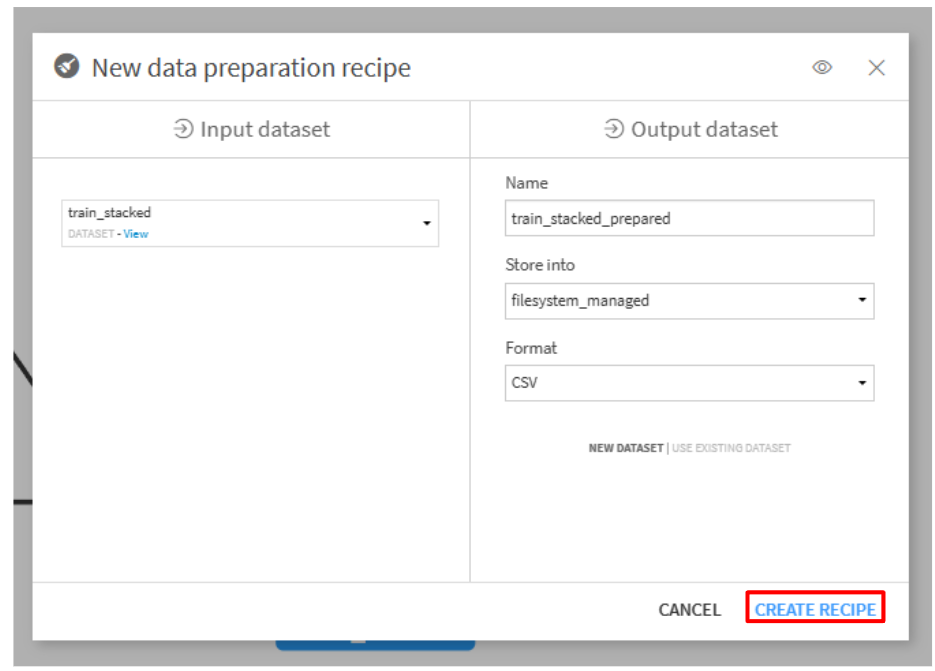
- 「ADD A NEW STEP」をクリックして、
Delete/keep columns by nameを選択します。 - 特徴量として使用する列を選択します。
Column multiple:id, duration, pdays, previous, job, education, marital, default, housing, loan, y, original_dataset Keep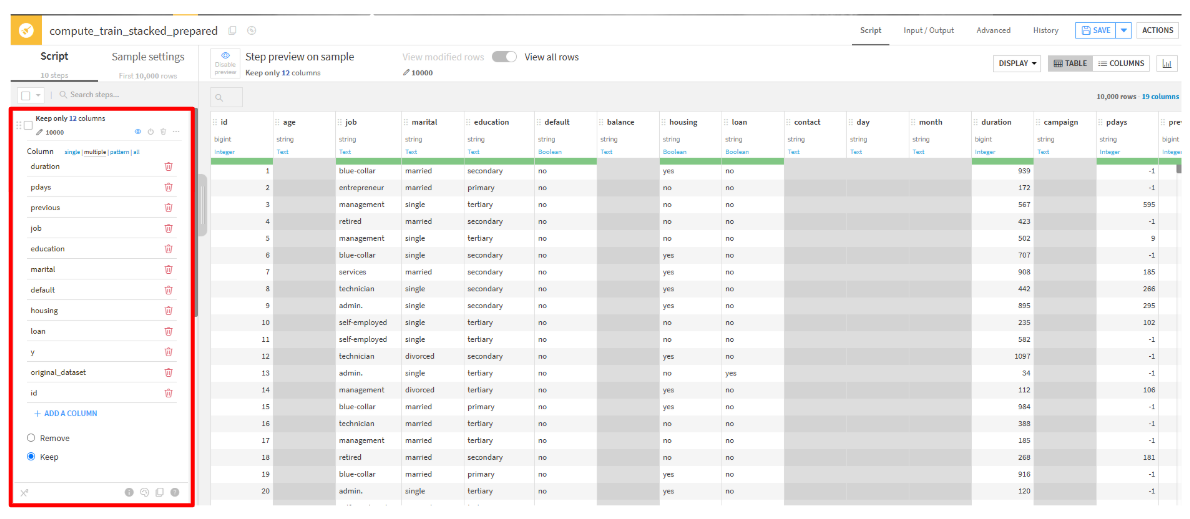


one-hot encoding(ダミー変数化)
pdaysを「-1」と「それ以外」に分割。previousを「0」と「それ以外」に分割。あとのカテゴリデータはohe-hot encoding(ダミー変数化)を実施。
まずは、pdaysとpreviousをone-hot encoding(ダミー変数化)します。
- 「ADD A NEW STEP」をクリックして、
Formulaを選択します。 - 「Formula for」をpdaysに変更して、
pdaysを「-1」と「それ以外」に分割する処理を記載します。その後、「APPLY」をクリックします。if(pdays >= 0, 1, 0)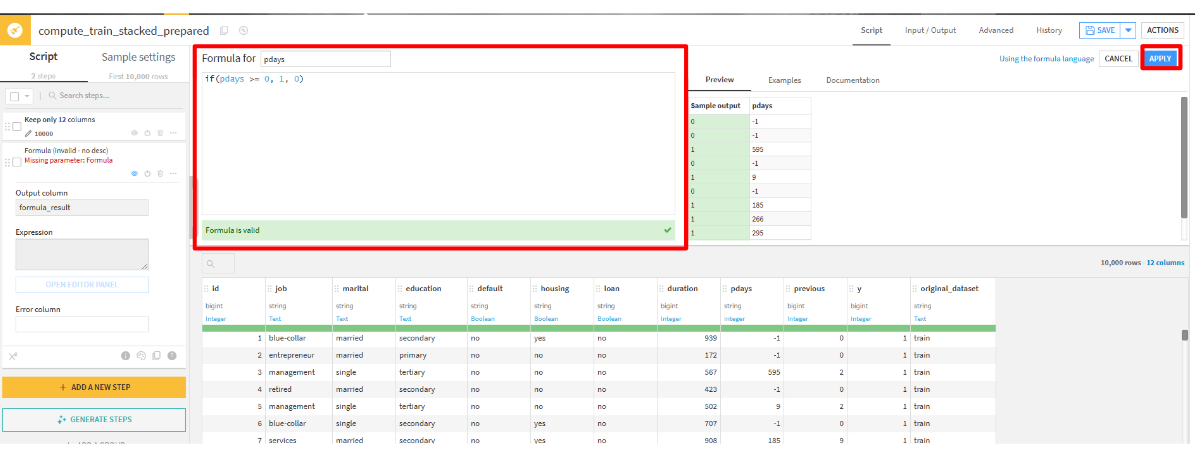
- 「Formula for」をpreviousに変更して、previousを「0」と「それ以外」に分割する処理を記載します。その後、「APPLY」をクリックします。
if(previous == 0, 0, 1)

次に、カテゴリデータをone-hot encoding(ダミー変数化)します。
- 「ADD A NEW STEP」をクリックして、
Unfoldを選択します。 - 各カテゴリデータに対して設定していきます(サンプルとして、
jobを選択)Columm:job、 Prefix(empty for no prefix):job_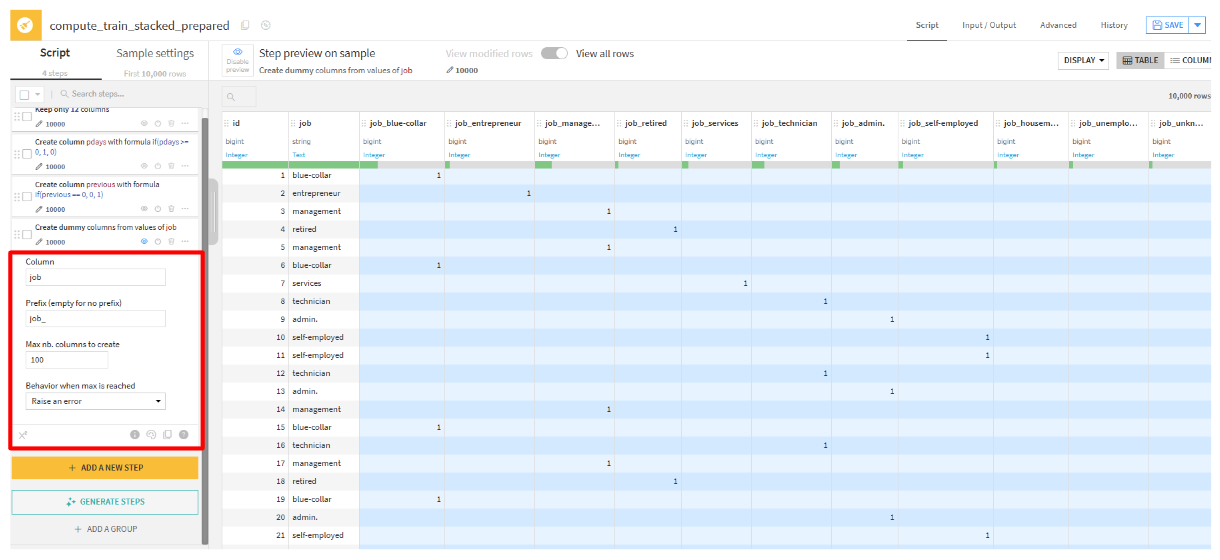
- 他の列も同様に行います。
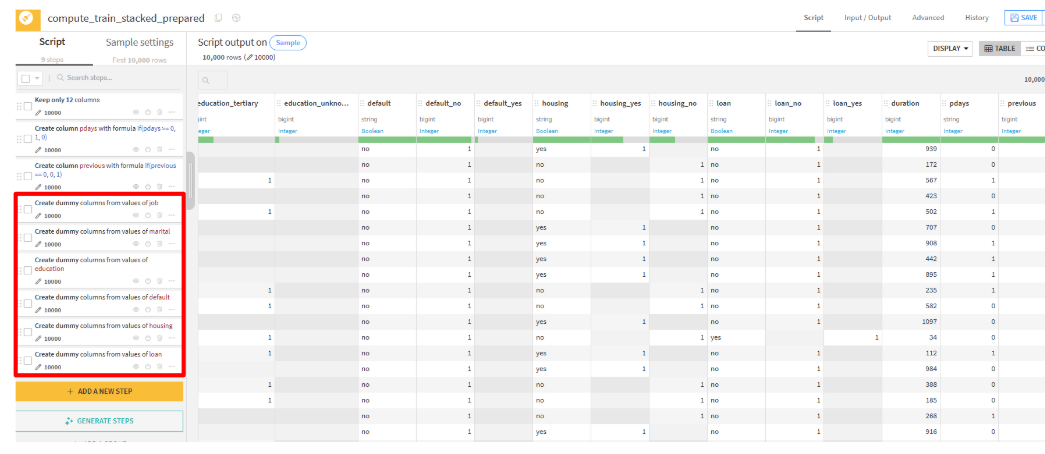


次は、Unfoldで出力された列の欠損値を0埋めしていきます。
- 「ADD A NEW STEP」をクリックして、
Fill empty cells with fixed valueを選択します。 - one-hot encoding(ダミー変数化)した列に対して値(0)を設定します。
column multiple:job_blue-collar, job_entreprenuer, job_manegement, job_job_retired, job_services, job_technician, job_admin., job_self-employed, job_housemaid, job_unemployed, job_unknown, job_student, marital_married, marital_single, marital_divorced, education_secondary, education_primary, education_tertiary, education_unknown, default_no, default_yes, housing_no, housing_yes, loan_no, loan_yes value to fill with:0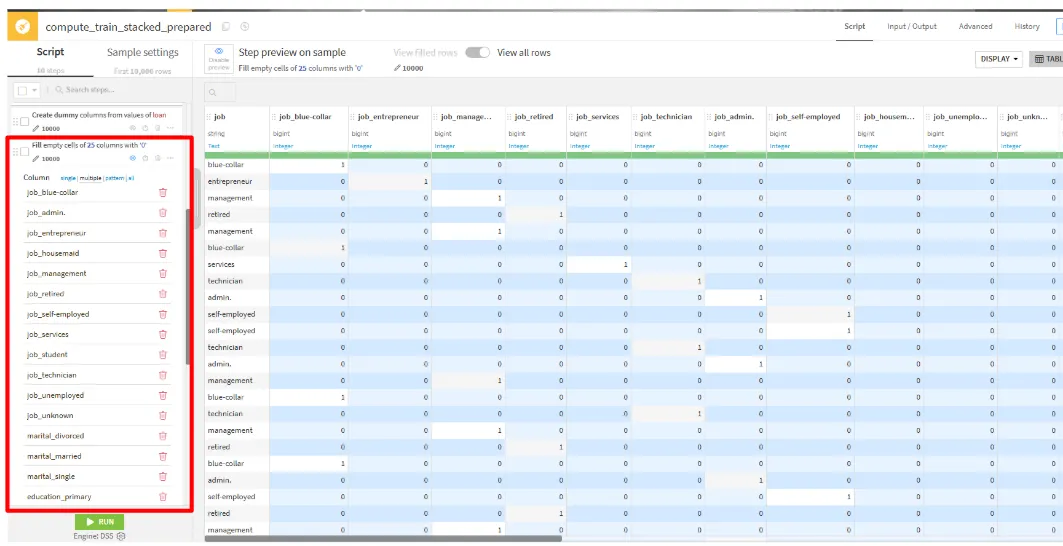


実行結果

trainデータとtestデータを分割
モデルを作成する前に、統合したデータをもとの2つのデータセットに分割します。
train_stacked_preparedをクリックして、Visual recipesの「Split」をクリックします。- 「Outputs」に
train_splitとtest_splitを作成して、「CREATE RECIPE」を選択します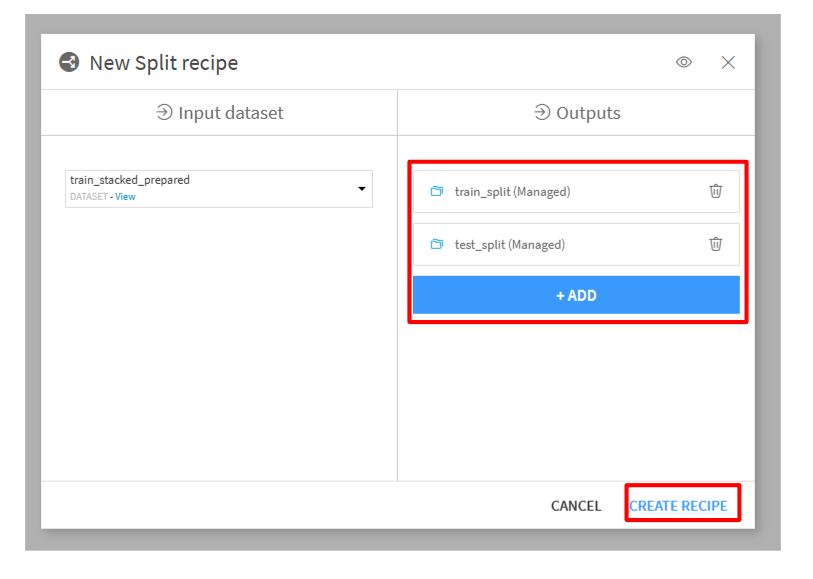
- 「Splitting」タブから、「Map values of a single column」を選択
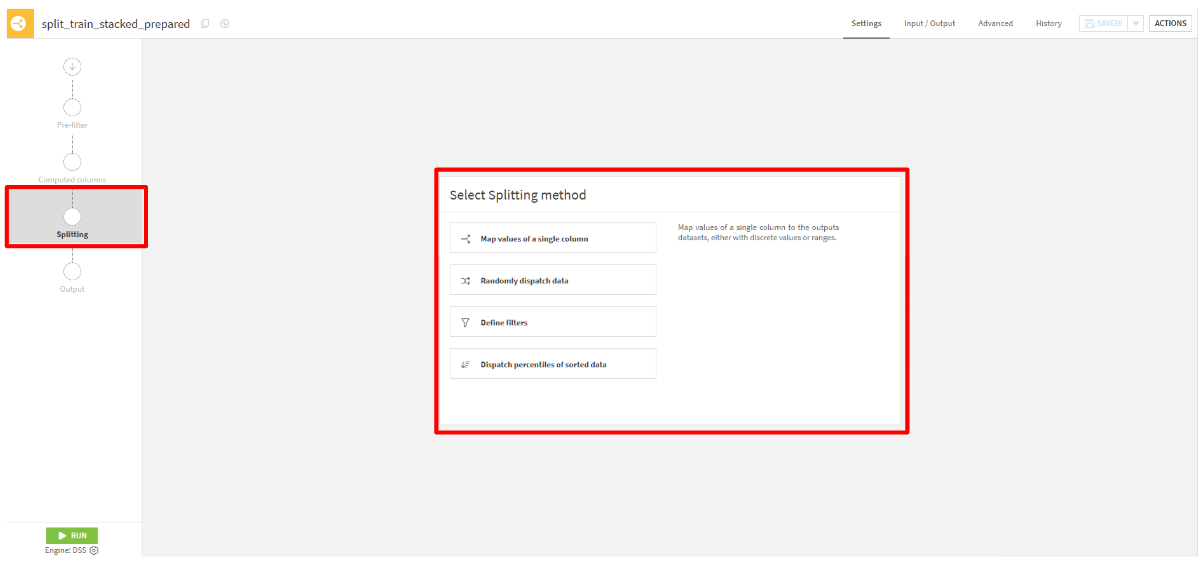
- Split on columnsに
original_datasetを選択して、Valueにtrainと記述します。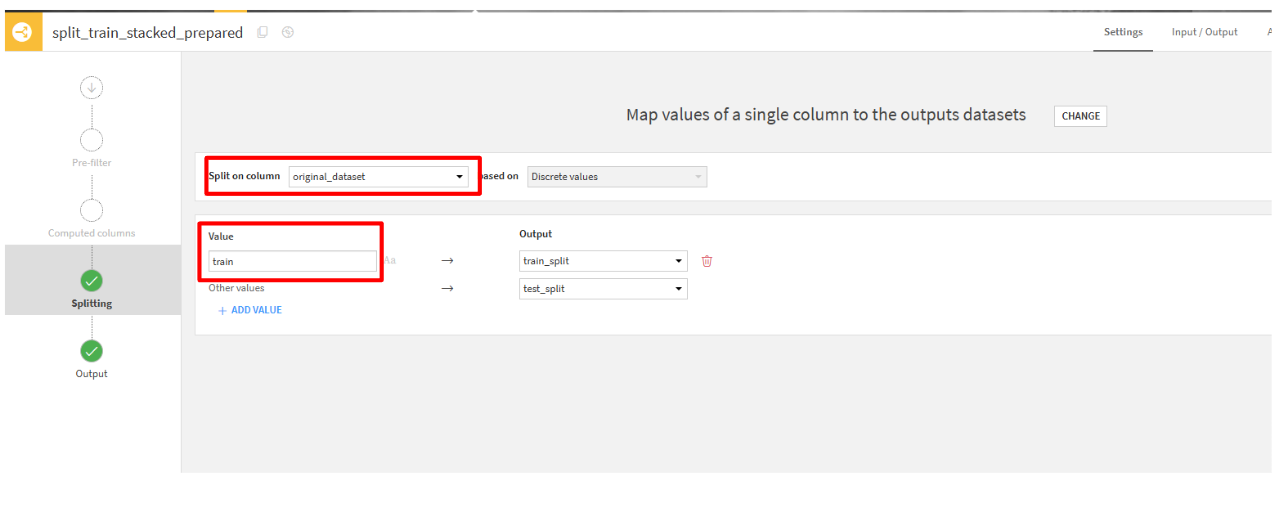
- 「Output」タブをクリックして、出力される列を確認します。問題がなければ「RUN」をクリックして実行します。
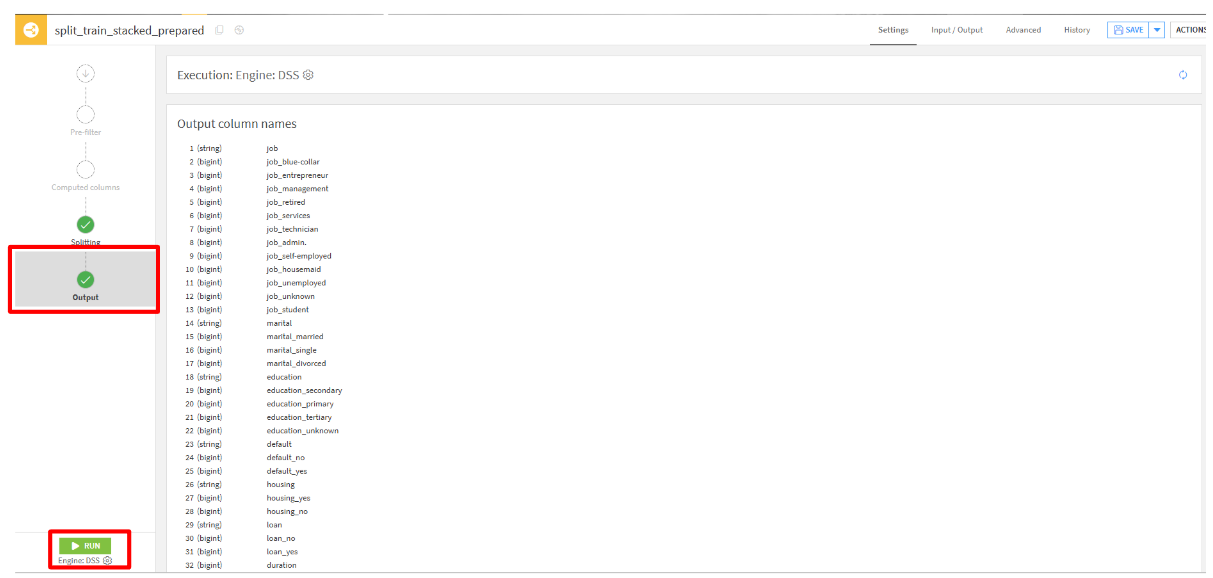




出力結果
- train_split

- test_split

機械学習
これから本題の機械学習のハンズオンに移っていきます。
モデルの作成
train_spllitをクリックして、「LAB」をクリックします。- Visual MLから「AutoMLPrediction」を選択します。
- select featureから今回の目的変数である
yを選択して、AutoMLの「Quick prototypes」をクリックします。その後、「CREATE」をクリックします。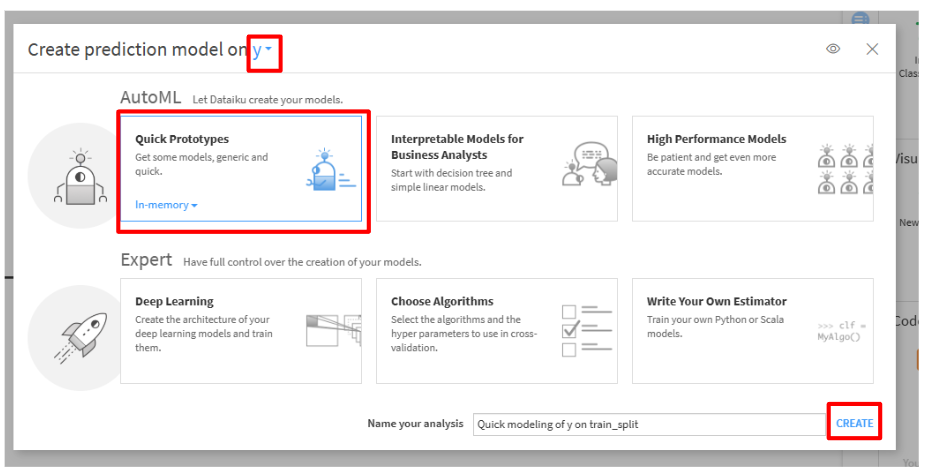

特徴量の選択
今回のモデルに使用する特徴量の選択を行います。
- DESIGNからFEATURESタブのFeatures handlingをクリックします。
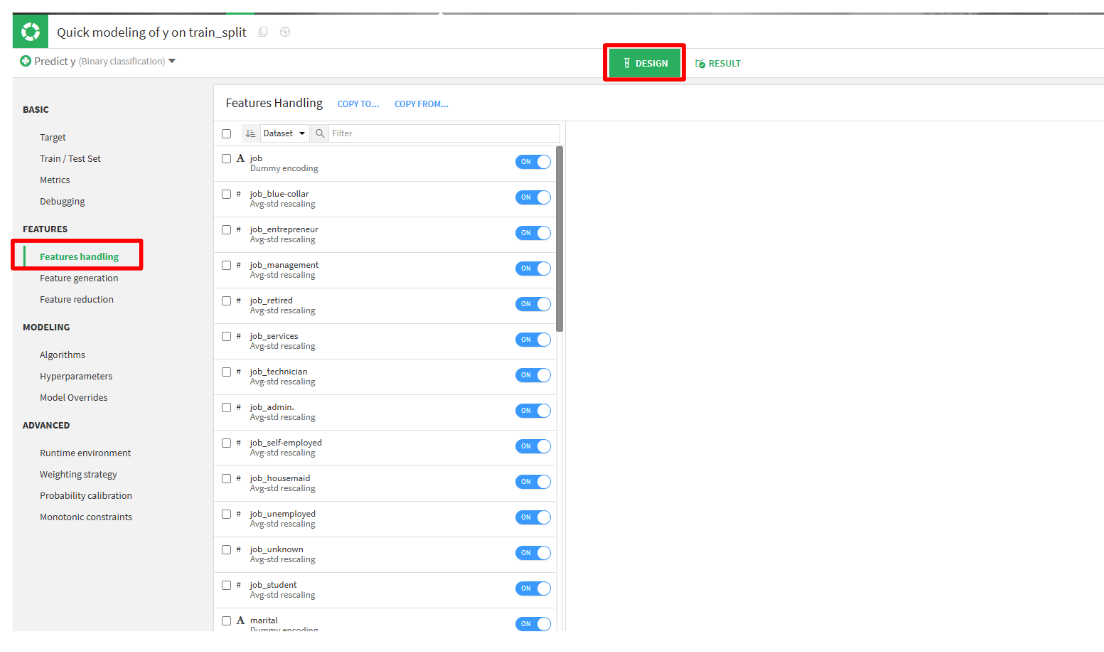
- one-hot encoding(ダミー変数化)で生成された列とyとの相関が高かった
duration、pdays、previousを選択します。(サンプルで、jobを排除します。)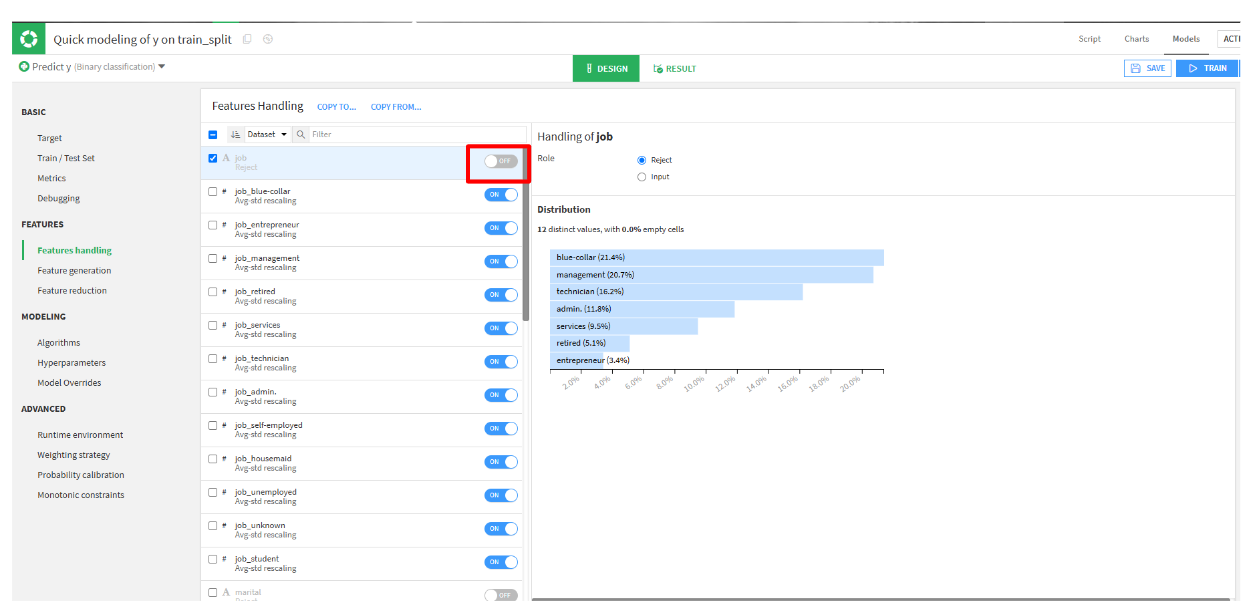


アルゴリズムの設定
アルゴリズムを選択します。
今回は、デフォルトで設定されている項目をそのまま使用します。

Random Forestとは?
複数の決定木を組み合わせて予測するアルゴリズムです。
仕組み
- データをランダムに複数のグループに分割します。
- 各グループ毎に異なる決定木を作成します。
- すべての決定木の予測結果を集約し、最も多い結果を最終予測とする。
Logistic Regressionとは?
データを2つのクラスに分類するアルゴリズムです。
仕組み
- 特徴量の重みを学習し、スコアを計算します。
- スコアを0 ~ 1の確率に変換します。
- スコアが、0.5以上なら「1」それ以外なら「0」と分類します。
結果確認
-
- 上記の設定が完了したら、Trainを押して学習させます。
- スコアが良い方をクリックしてモデルを確認します。(今回は、Logistic Regressionのほうが良かったのでそちらをクリックします。)
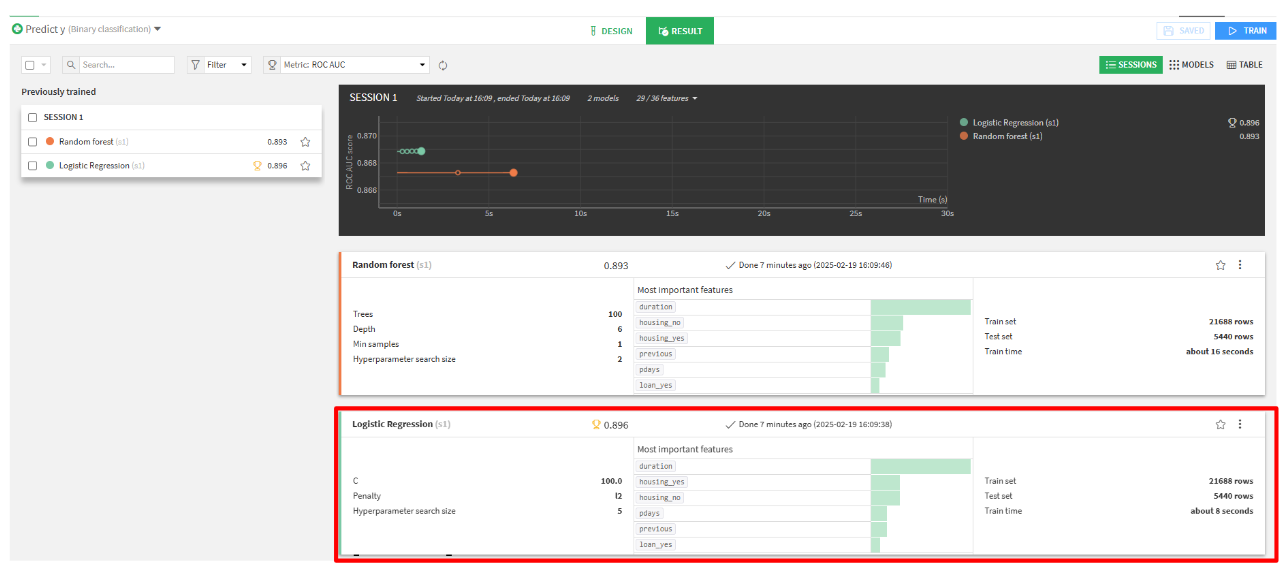
-
-
- True Positive (TP):真陽性 → 実際にPositiveであり、正しくPositiveと予測
- False Positive (FP):偽陽性 → 実際はNegativeなのに、誤ってPositiveと予測
- False Negative (FN):偽陰性 → 実際はPositiveなのに、誤ってNegativeと予測
- True Negative (TN):真陰性 → 実際にNegativeであり、正しくNegativeと予測
-
- デプロイします。
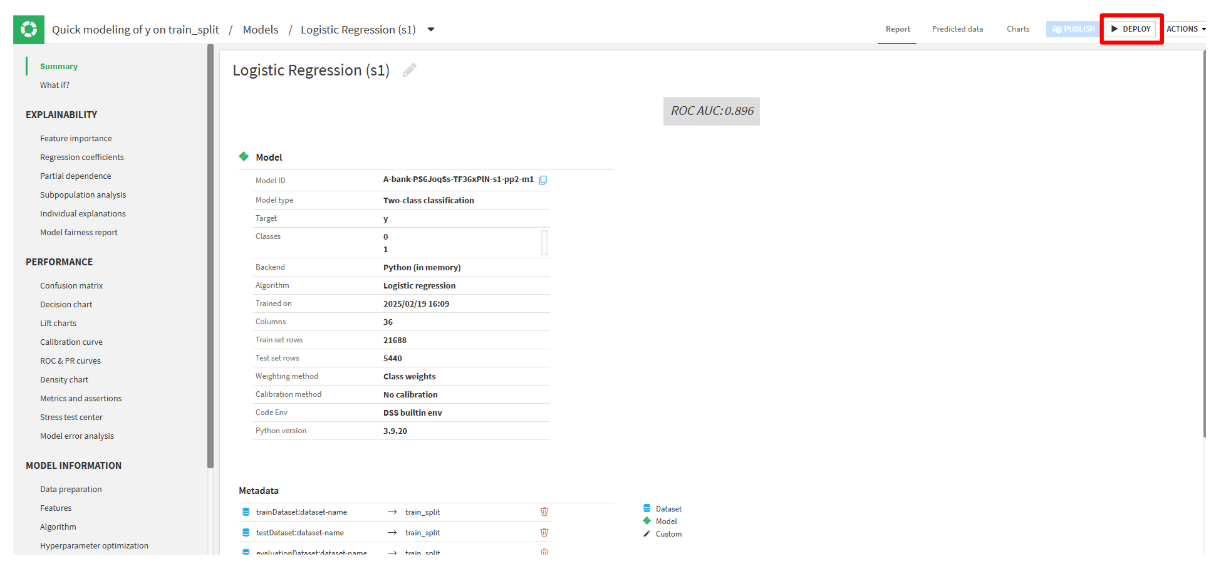
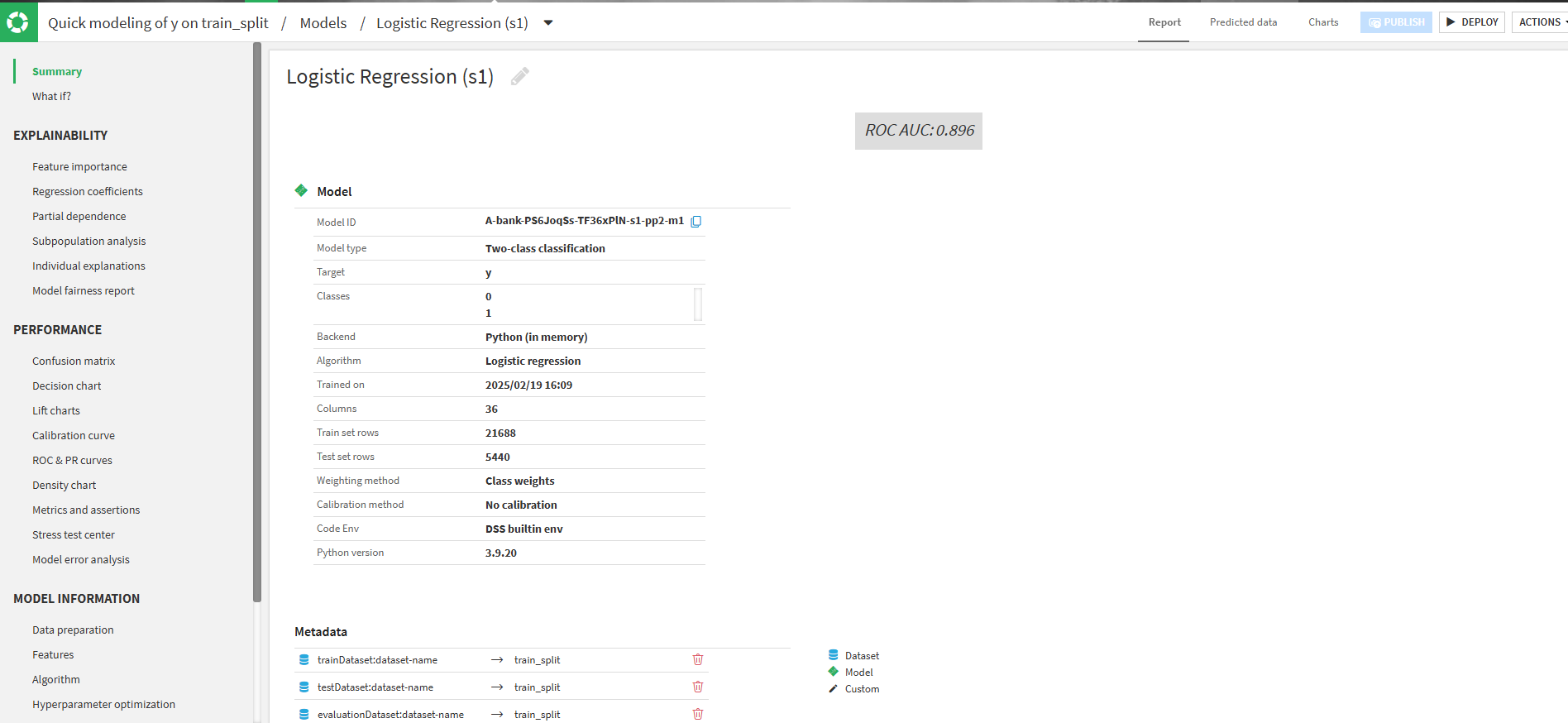
Summary
Confusion matrix
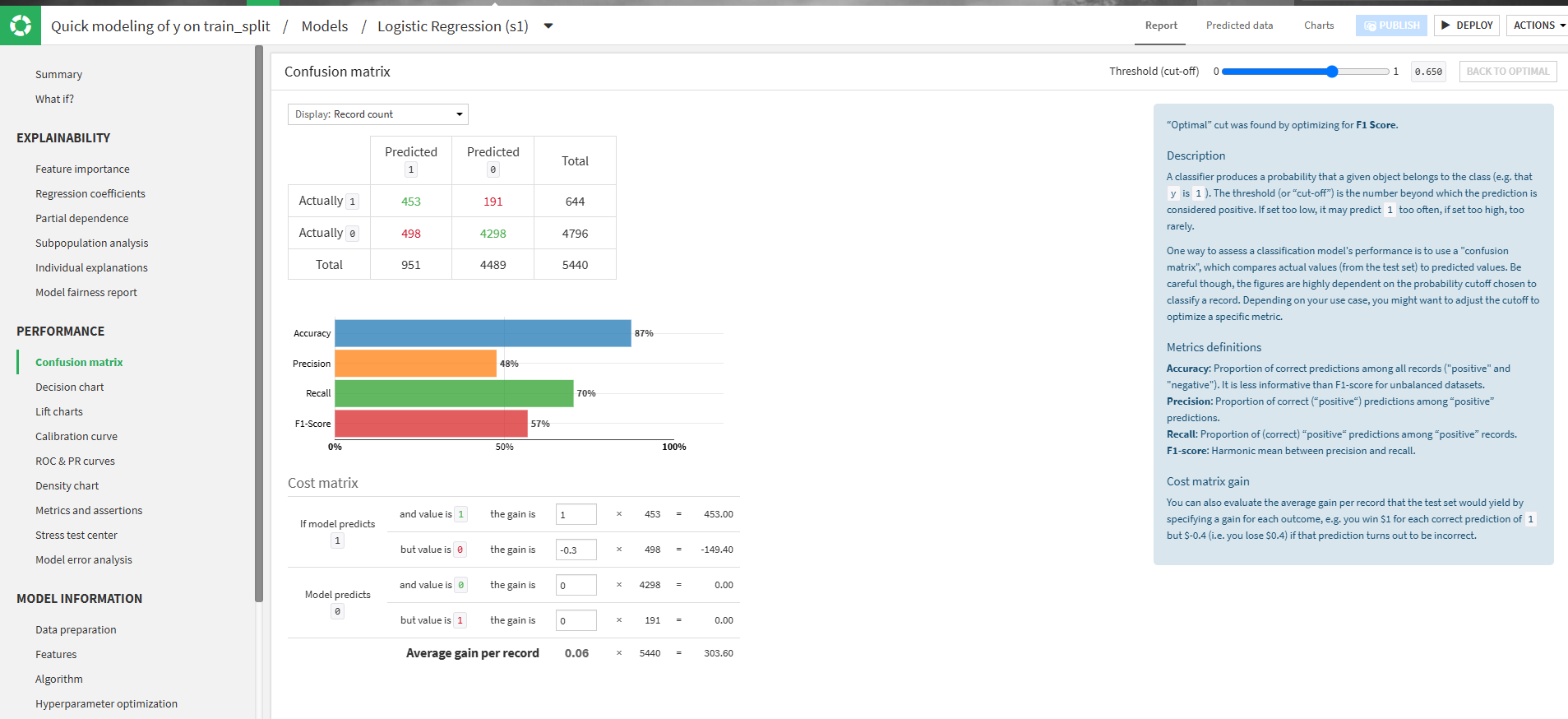
Confusion Matrix(混同行列)とは?
Confusion Matrixは、分類モデルの予測結果と実際の値を比較し、どれくらい正しく分類できたかを示す表です。Predicted(Positive) Predicted(Negative) Actually(Positive) True Positive (TP) False Negative (FN) Actually(Negative) False Positive (FP) True Negative (TN) 各要素の意味
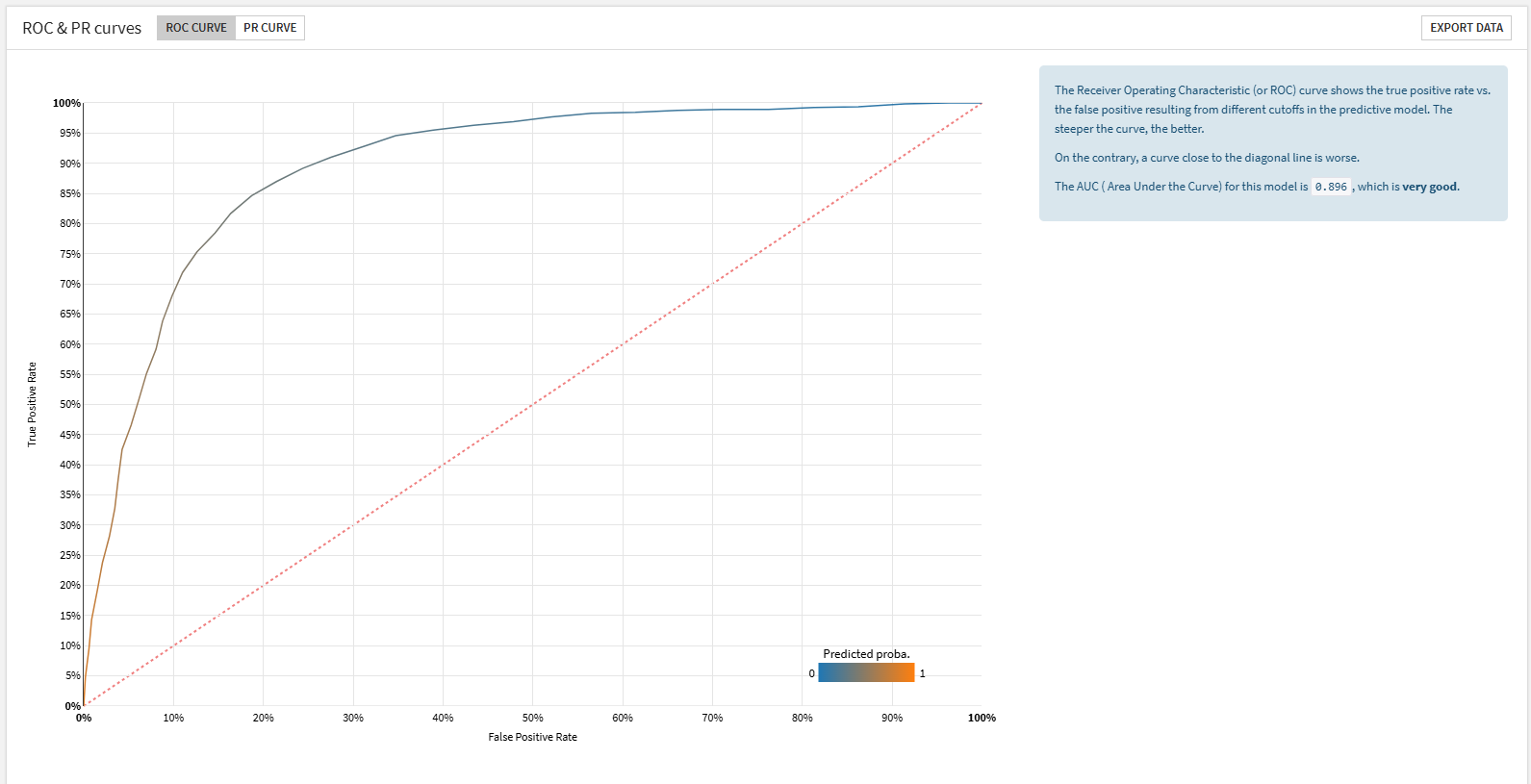
ROC & PR curves





予測
-
- Predict y(binary)を選択して、Apply model on data to predictの「Score」をクリックします。
- Input datasetのInput datasetに
test_splitを選択して、「CREATE PECIPE」をクリックします。 - 「RUN」をクリックします。
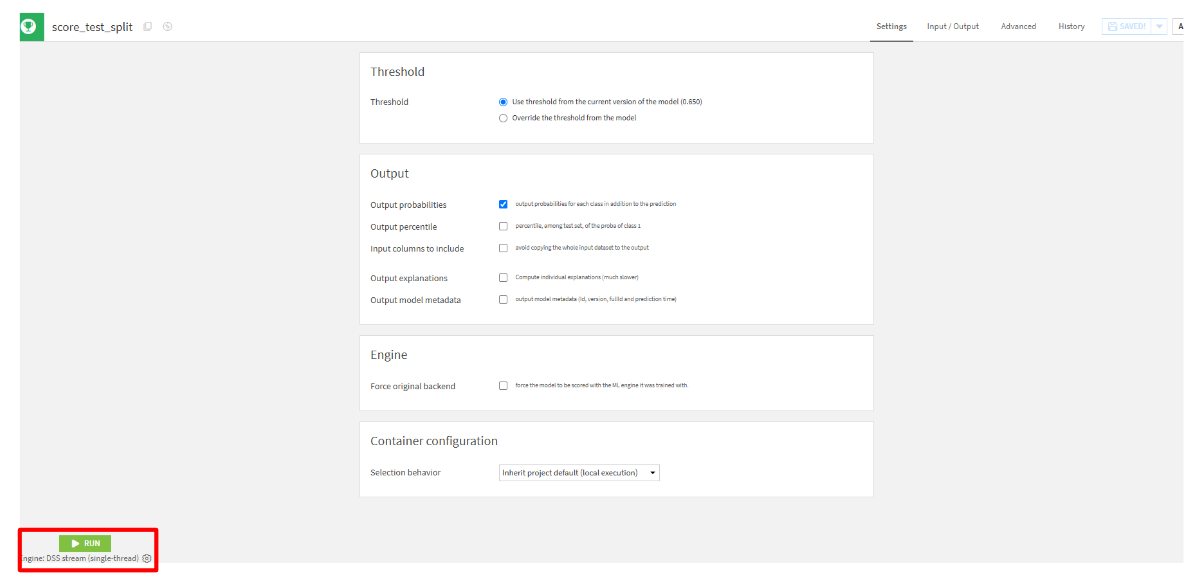

出力結果
列の最後にproba_0, proba_1, predictionが確認できるかと思います。

提出
お疲れさまでした。最後のハンズオンとして、予測したデータをダウンロードして提出します。
test_split_scoredを選択して、「Prepare」をクリックします。- 「CREATE RECIPE」をクリックします。
- ADD A NEW STEP」をクリックして、
Delete/keep columns by nameを選択します。 - 提出する際に必要な列を保持します。
Column mulutiple:id, prediction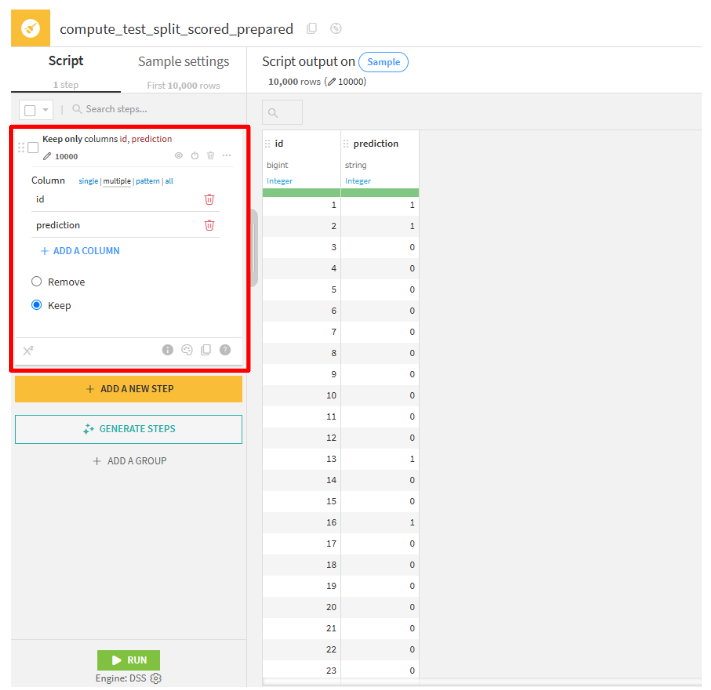
- 「RUN」をクリックします。
- 「Export」を選択して、csv(ヘッダなし形式)でダウンロードします。
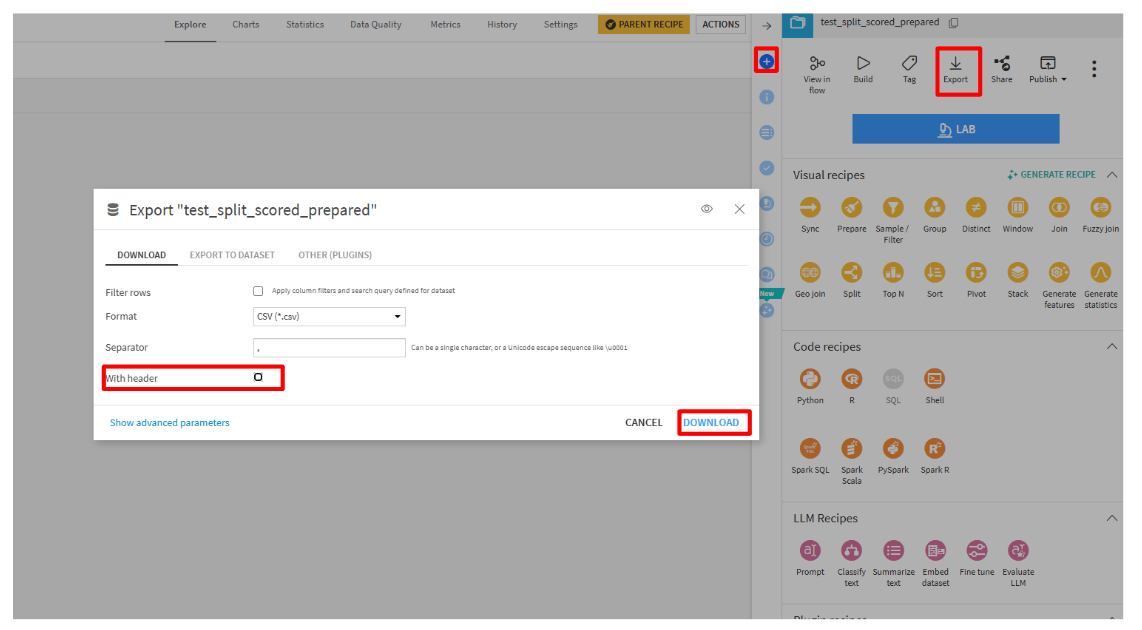
- SIGNATEの「投稿」をクリックして、投稿します。

出力結果


評価
評価は、0.76でした。

改善案
- 特徴量エンジニアリングの強化
- 今回使用しなかったtrainデータの列を活用し、新しい特徴量を追加すること
- 既存の特徴量を組み合わせること
- アルゴリズムの多様化
- 他のモデル(SVM, XGBoost, LightGBM など)を試すこと
- データの前処理の工夫
- 異常値の処理やデータの正規化・標準化を行うこと
- 特徴量のスケールが異なる場合は、適切なスケーリング手法を適用する。
感想
Dataikuを使用すると、前処理の状況を常に可視化しながら進められるため、とても分かりやすく感じました。また、アルゴリズムの選択も直感的に行えるので、手軽に試行錯誤できる点が便利でした。今後は特徴量の工夫や別のアルゴリズムの活用にも挑戦し、さらなる精度向上を目指したいと思います。
機械学習の精度向上には、データの工夫やアルゴリズムの選択が重要ですが、Dataikuなら初心者でも直感的に試行錯誤できます。これから二値分類に挑戦する方や、より高度な分析に興味がある方は、ぜひ一緒に学んでいきましょう!
