はじめに
Data Haikerのみなさまこんにちは!
先日のData Haikerイベントはお疲れ様でした!渋谷での開催でしたが関西圏から参加された方もいらっしゃって、Dataikuに対する熱量を感じることが出来ました。
さて、Data Haikerのイベントでは、Kaggleの退職予測のデータセットを用いて、従業員の退職予測を体験しました。
今回は、その復習と精度向上を試してみたので、ご紹介出来ればと思います。
退職予測をやってみる
データについて
データはKaggleの退職予測(https://www.kaggle.com/datasets/pavansubhasht/ibm-hr-analytics-attrition-dataset)のデータセットを用います。リンクからダウンロードが可能です。

データは以下のような構成となっています。
- Age: 数値。従業員の年齢。
- Attrition: 従業員が会社を去るかどうか(0=いいえ、1=はい)。
- Business Travel: 出張の頻度(1=出張なし、2=頻繁に出張、3=まれに出張)。
- Daily Rate: 数値。給与レベル。
- Department: 部門(1=人事、2=研究開発、3=営業)。
- Distance From Home: 数値。家から職場までの距離。
- Education: 数値。教育レベル。
- Education Field: 教育分野(1=人事、2=生命科学、3=マーケティング、4=医学、5=その他、6=技術)。
- Employee Count: 数値。従業員数。
- Employee Number: 数値。従業員ID。
- Environment Satisfaction: 数値。環境に対する満足度。
- Gender: 性別(1=女性、2=男性)。
- Hourly Rate: 数値。時給。
- Job Involvement: 数値。仕事への関与度。
- Job Level: 数値。職位のレベル。
- Job Role: 職種(1=HC代表、2=人事、3=研究室技術者、4=マネージャー、5=マネージングディレクター、6=研究ディレクター、7=研究科学者、8=営業エグゼクティブ、9=営業代表)。
- Job Satisfaction: 数値。仕事に対する満足度。
- Marital Status: 婚姻状況(1=離婚、2=既婚、3=独身)。
- Monthly Income: 数値。月給。
- Monthly Rate: 数値。月給レート。
- NumCompanies Worked: 数値。勤務した会社の数。
- Over 18: 18歳以上かどうか(1=はい、2=いいえ)。
- OverTime: 残業(1=なし、2=あり)。
- Percent Salary Hike: 数値。給与のパーセント上昇。
- Performance Rating: 数値。パフォーマンスの評価。
- Relationship Satisfaction: 数値。関係の満足度。
- Standard Hours: 数値。標準労働時間。
- Stock Option Level: 数値。ストックオプションのレベル。
- Total Working Years: 数値。総労働年数。
- Training Times Last Year: 数値。昨年の研修時間。
- Work Life Balance: 数値。仕事と私生活のバランス。
- Years At Company: 数値。会社に在籍した年数。
- Years In Current Role: 数値。現在の役割での年数。
- Years Since Last Promotion: 数値。最後の昇進からの年数。
- Years With Current Manager: 数値。現在のマネージャーとの勤務年数。
探索的データ分析
では、データを読み込んで探索的データ分析を行っていきます。
データを読み込み、データの型を正しく定義します。
次に、Statisticsタブから、推奨の統計情報を確認します。
気づいたこと
- Over18はすべてYes
- StandardHoursはすべて80
- EmployeeCountはすべて1
そのほか、
- 欠損値の有無
- 統計情報(外れ値、異常値)
- 変数間の関係性
などを確認します。
データの分割
データを分割します。
通常、訓練セットとテストセット、未知データのセットで分割することが一般的ですが、
今回は未知データが無いため、訓練セットとテストセットで分割します。
分割の際に、今回のような偏りのあるデータの場合ランダムに分割すると転職した人がtrainデータに含まれない、といった事象が起こるため、転職した人がどちらのデータセットにも均等に含まれるようにします。
ベースラインモデルの構築
ある程度データが理解できたタイミングで、訓練データを利用してベースラインとなるモデルを作成します。
ベースラインモデルはシンプルでクイックに検証できるモデルを使用することが一般的です。
今回はクラスごとに偏りが有るため、Train/Test Setの分割の設定をClass rebalanceにします。
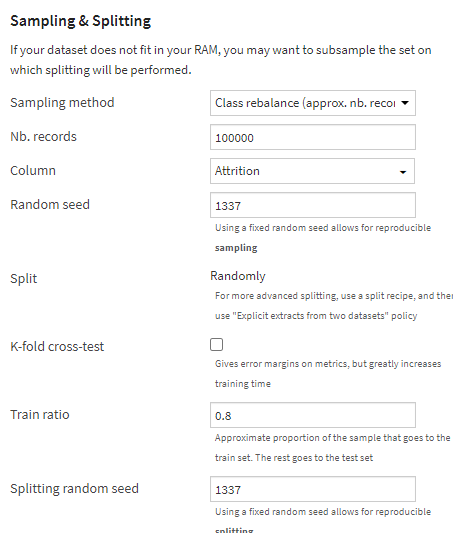
結果がこちら、なかなかの結果に見えます。

モデルの詳細を確認します。
まずは、混同行列を確認します。
混同行列は、実際のモデルの予測精度を最も正確に理解できる機能です。
今回は退職予測なので、退職しそうな人に対してアクションを行う、という目的で使用する場合、退職者を退職しない、と予測することが問題になります。(画像でいう右上の赤字セル)

分かりやすく説明すると、全ての人間が退職しない、と予測した場合、精度は88%になりますが、これではモデルとして意味をなしませんよね?なので精度以外にも混同行列を見てモデルの精度を測る必要があるということです。

また、Accuracy(精度)以外にもPrecision, Recall, F1-Scoreという指標が有ります。
それぞれ前述の退職しそうな人を正しく予測出来ているか、などの課題に対応した指標なのですが、F1-ScoreがPrecision, Recallの調和平均となっており、どちらも加味した指標になっています。
なので一旦はF1-Scoreだけ見て頂ければ問題無いかと思います。
今回のベンチマークモデルのF1-Scoreは45%なので、モデルとしては改善の余地がありそうですね。
次に、特徴量の重要度を確認します。
残業が重要度が高そうですね。これは実際に重要そうですが、一見重要でない指標などが重要視されている場合はデータの確認が必要になります。
逆に、重要視されるべき指標が重要視されていない場合もデータを見なおす必要があります。

データのモデルへの貢献を見るためには、Partial dependenceやSubpopulation analysisも有効になります。
例えば、JobSatisfactionやRelationshipSatisfactionは一見退職に関係がありそうですが、重要視されていないようなので、これらの重要度を上げるような取り組みが必要になりそうです。


モデルの改善
モデルを改善するためには、色々なアプローチが有ります。そのいくつかをご説明します。
- 特徴を増やす:既存の指標を加工して新たな意味づけを行います
- 特徴を減らす:いくつかの特徴を纏めて1つの特徴にするか、特徴を削除します
- 連続性を持たせる:順序のある指標を数値化し、連続性を持たせます。
- モデルを変更する:より強力なモデルを使用します
- パラメータを変更する:モデルのパラメータを変更します
特徴量エンジニアリング
特徴量エンジニアリングは、特徴量を作成したり、減らしたりすることでモデルを改善していくアプローチ方法です。
今回は重要視されるべきJobSatisfactionやRelationshipSatisfactionが重要視されるようにまとめていこうと思います。
クラスタリングモデルを構築します。
Satisfaction系の列でクラスタリングを行い、そのクラスタを特徴に含めます
また、Monthly Rateなどの給与指標は、Monthly Incomeだけに統一しました
結果、精度としては改善したのですが、Recallがかなり下がっています。混同行列を見ると退職する、と予測する基準がかなり厳しくなっているようです。

ただ、精度的には改善が見られました。
パラメータチューニング
最終的にモデルの精度が上がってきたら、パラメータチューニングを行います。
アルゴリズムを増やしたり、パラメータを増やしたりして、最適なモデル、パラメータセットを探索します。
お試しで色々なモデルを試してみました。
一般的にLightGBMが良い精度が出やすいと言われていますが、今回はそのLightGBMが最も高い精度を出しています。


重要度を見るとこれまで色々あった収入系の指標をMonthly Incomeに統一したことで、重要視されるようになっています。

今回はこのモデルをデプロイしようと思います。
デプロイした後、Evaluateレシピで既知データを用いたモデルの評価を行います。

評価を行い、出てきた評価指標を確認します。
F1が0.5と満足のいくモデルでは有りませんでしたが、退職者の7割くらいは拾えるモデルになっているようです。

今後の改善
これではまだ実運用に耐えるモデルにはなっていないと思います。
今後の改善案としては、
- 特徴の理解を深め、より詳細な特徴量エンジニアリングを行う
- より表現力の高いモデルを作成する
- データ量を増やす
- 取得する特徴を増やす
- データの属性(部署など)ごとにモデルを分割する
などが考えられます。
ちなみに、このデータセットはKaggleのデータセットなので、KaggleのDiscussionで色々な議論が行われています。
Dataikuでは使わなくてもよいエンコーディングなどの議論もありますが、興味がある方はぜひ覗いてみてください。
https://www.kaggle.com/datasets/pavansubhasht/ibm-hr-analytics-attrition-dataset/discussion
最後に、Dataikuには様々なユーザーコミュニティが存在しており、DataHaikerもその一つです。 Dataikuの体験会やもくもく会など、様々なイベントが行われているので、皆さま是非ご参加ください!ここでDataikuのユーザーコミュニティを二つ紹介したいと思います
Data Haiker slackチャンネル
https://join.slack.com/t/data-haiker-community/shared_invite/zt-26ur9fk3k-4Y9omDNqjYuZYHFeV3icUQ
ここではユーザー同士の交流や、イベントの告知、情報共有などが行われています。
Japan User Group
https://community.dataiku.com/t5/Japan-User-Group/gh-p/Japan-user_group
Dataikuは基本は英語ですがここでは日本語で質問することが可能です。Dataikuの使い方でわからないことがあったらここを参照したり、質問することができます。
