はじめに
SIGNATEの【練習問題】アワビの年齢予測をDataikuで実施しました。本記事ではノーコードで、回帰分析を行う手順を紹介します。
概要
アワビの年齢を複数の測定値を用いて予測します。
アワビの年齢は、殻の表面にできる輪紋の数から測定できるとされています。また、成長とともに殻が長くなるため、今回の予測には殻のサイズや重量などの変数が使用されていると考えられます。
年齢を正確に予測することで、アワビの成長をモニタリングし、適切な収穫時期の判断に役立てることができます。これは、養殖の最適化や資源管理にも貢献することが出来ると考えられます。
使用データ
使用するデータは、以下の2種類です。(ダウンロードは、こちら)
- 学習用データ(train.csv)
- 評価用データ(test.csv)
データ説明
データに含まれている各列の説明
| 列名 | 説明 |
| id | インデックスとして使用 |
| Sex | 性別 |
| Length | 長さ |
| Diameter | 直径 |
| Height | 高さ |
| Whole weight | 全体の重量 |
| Shucked weight | 身の重量 |
| Viscera weight | 殻の重量 |
| Shell weight | 殻の重量 |
| Rings | 年齢 |
評価指標
本コンペティションでは RMSE(Root Mean Squared Error) を指標としてモデルの制度を評価します
RMSEとは?
予測値と実際の値のズレを測る指標です。誤差を二乗して平均を取り、平方根を求めることで、大きな誤差を強調しつつ全体の誤差を表します。値が小さいほど精度が高いです。

投稿方法
提出するファイルは、以下の形式の csv(ヘッダなし) で作成します。
1列目にid、2列目にRingsを記載し、SIGNATE上で投稿します。
| id | Rings |
| 1 | 9 |
| 2 | 17 |
| … | … |
使用レシピ一覧
ビジュアルレシピ
準備:様々な処理を追加できます。
Unfold:ダミー変数化Fill empty cells with fixed value:欠損値を特定の値で補間します。
スタック:データをユニオンします。
分割:指定した列の値毎にデータを分割します。
ラボ
-
AutoML 予測:機械学習モデルを自動構築します。
その他のレシピ
-
予測:学習済みモデルを用いて予測データのスコアリングをします。
ハンズオン

データ確認

trainをクリックして、右上の統計タブをクリックします。- 「+ ADD A NEW CARD」をクリックします。
- Automatically suggest analysesから、Univariate analysis on all variablesとCorrelation matrix on all numerical…を選択して、「CREATE SELECTED CARDS」をクリックします。
Univariate analysis on all variablesとは?
各変数ごとに、連続型やカテゴリ型に応じた分布や特徴を分析できます。

Correlation matrixとは?
複数の変数間の相関関係を表した行列です。各要素は相関係数を示し、1に近いほど強い正の相関、−1に近いほど強い負の相関を意味します。

分析結果
-
欠損値なし
-
SexにMaleとFemale以外に、Iがある。(*調べてみたところ幼児(Infant)を示す) -
Ringsと最も相関が高いのはShell weightである。
おまけ
今回もTableauでダッシュボード化してみました。(Tableau Publicはこちら)

ユニオン
データの前処理を1回にするためにユニオンします。

trainを選択して、ビジュアルレシピのスタックをクリックします。(出力名:dat)- 元の列を「ON」に設定して実行します。(ONにすると入力データセットを示す列が追加されます。)
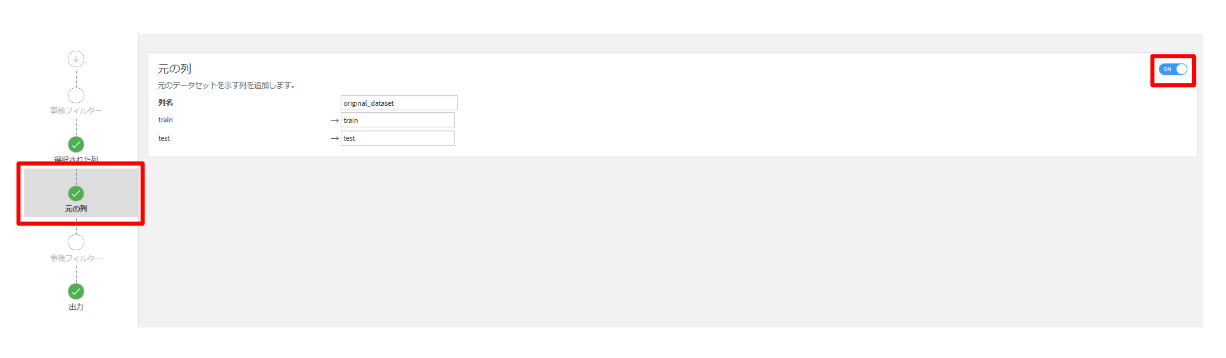

ユニオンする理由
- データの一貫性を保つため
- 例えば、カテゴリ変数のエンコーディング(One-Hot EncodingやLabel Encoding)を別々に行うと、テストデータに含まれるカテゴリが訓練データにない場合にエラーが発生する可能性があります。
- スケーリングや正規化の一貫性を保つため
- 例えば、
StandardScaler(平均0、標準偏差1に変換)やMinMaxScaler(0〜1に変換)を適用する場合、テストデータの範囲が訓練データの範囲外にあると、スケールがずれる可能性があります。
- 例えば、
- 外れ値や欠損値の処理の制度を向上させるため
- 外れ値の処理や欠損値の補完をする際、データが多い方が適切な統計値を算出できるため、訓練データとテストデータを統合することが有効です。
前処理
Sex をダミー変数化します。

trainを選択して、ビジュアルレシピの準備をクリックします。(出力名:dat_prepared)- 「+ステップを追加」から下記2つのステップを追加して、実行します。
Unfold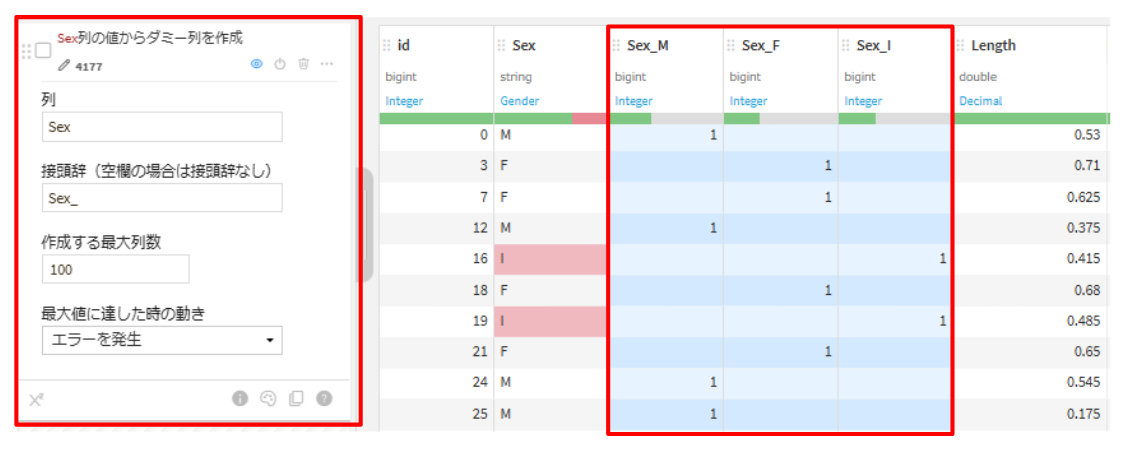
Fill empty cells with fixed value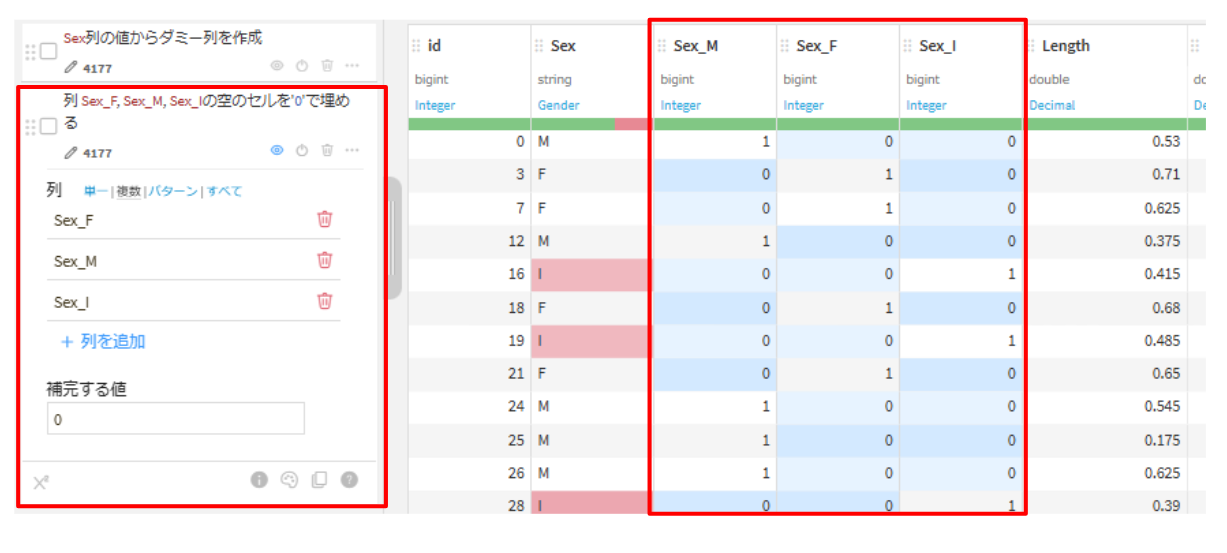


one-hot encoding(ダミー変数化)とは?
カテゴリデータを機械学習モデルが扱える数値データに変換する方法です。
| Sex |
|---|
| Male |
| Female |
| Other |
各カテゴリ毎に列を作成して、該当する行にフラグ(1)を入力します。
| Male | Female | Other |
|---|---|---|
| 1 | 0 | 0 |
| 0 | 1 | 0 |
| 0 | 0 | 1 |
one-hot encodingを行う理由
- ほとんどのモデルはカテゴリデータをそのまま入力できないため
- 数値の大小による影響を防ぐため
- 例えば、
Male=1, Female=2, other=3のように数値を割り当てると、モデルが「Female(2)はMale(1)より大きい」など誤った関係を学習してしまう。
- 例えば、
分割
前処理が完了したので、ユニオンしたデータを分割します。

dat_preparedを選択して、ビジュアルレシピの分割をクリックします。(出力名:train_split, test_split)original_datasetの値を基にデータセットを分割して、実行します。
| Value | Output |
|---|---|
| train | train_split |
| Other values | test_split |

学習
モデルの構築をしていきます。
train_splitをクリックして、ラボを選択します。- ビジュアルMLのAutoML 予測を選択して目的変数(
Rings)とモデル(Quick Prototypes)を選択します。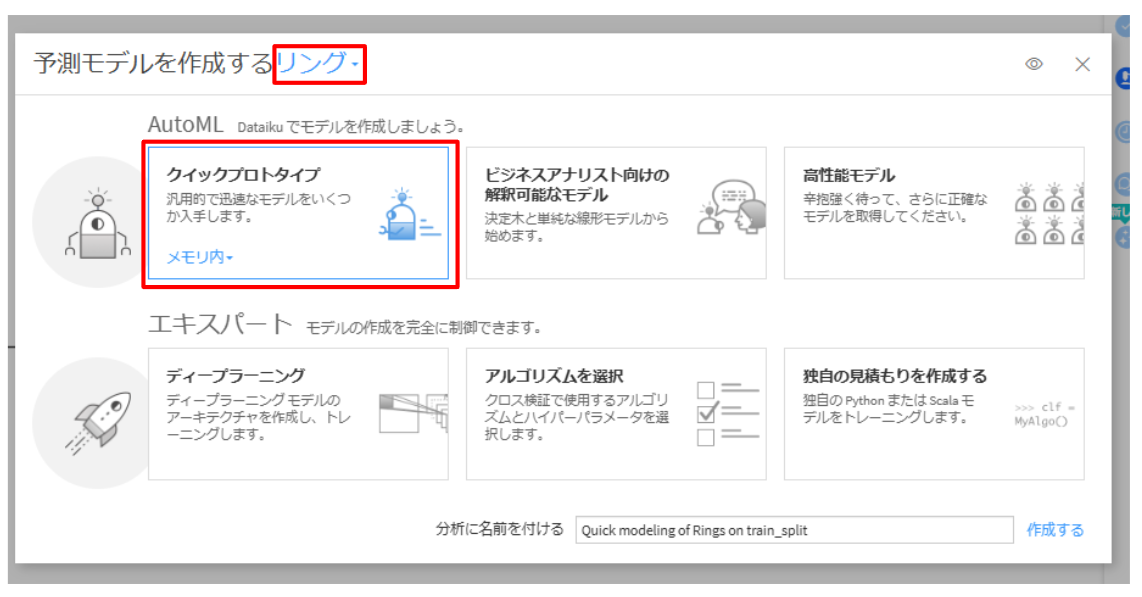
- 各種設定を行い、学習させます。
基本:メトリクス
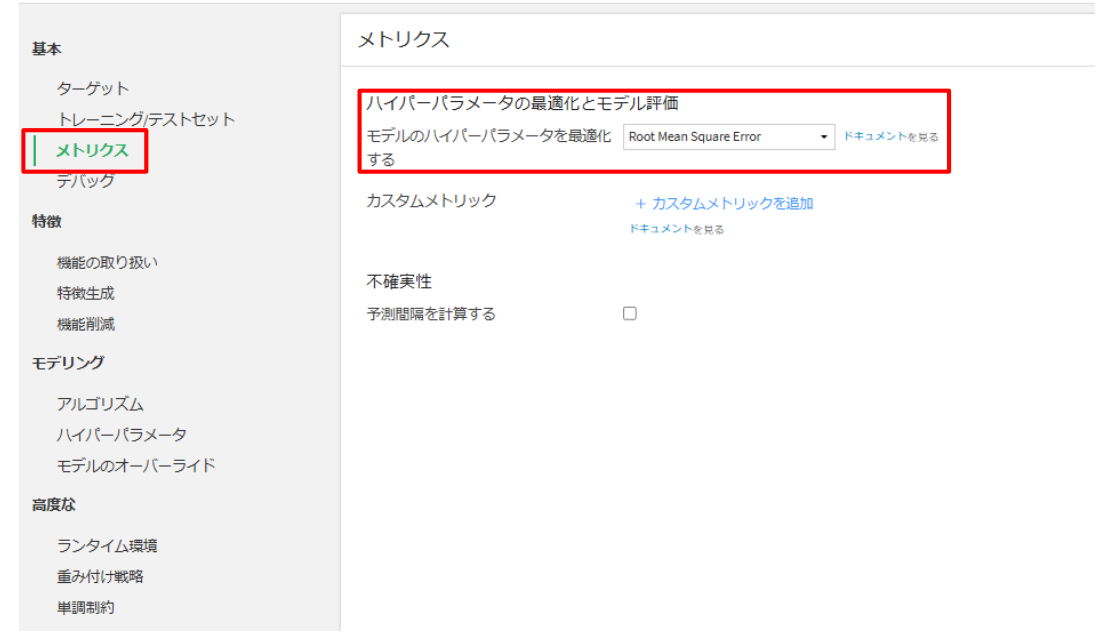
- 特徴:機能の取り扱い(ダミー変数化した
SexとSex_FとSex_Mの2つの値が分かれば残りのSex_Iの値が決まるため、Sex_Iは不要になるので削除します。)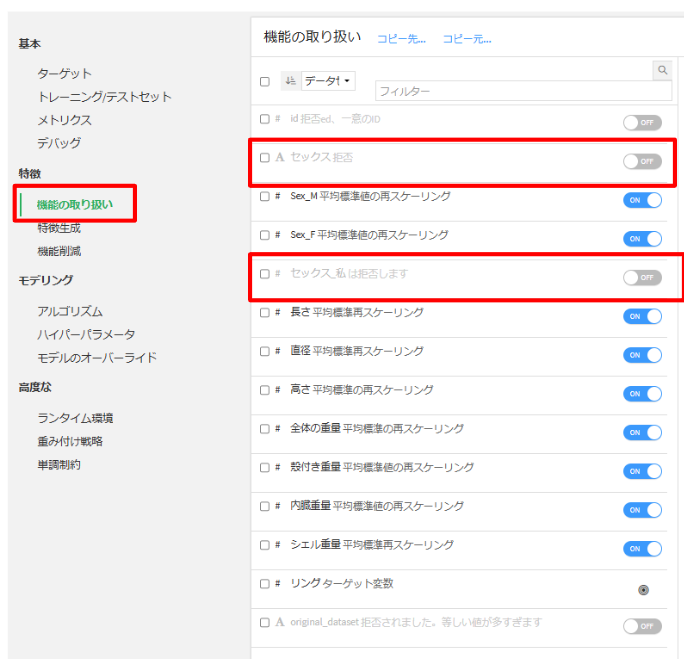
モデリング:アルゴリズム(XGBoost)
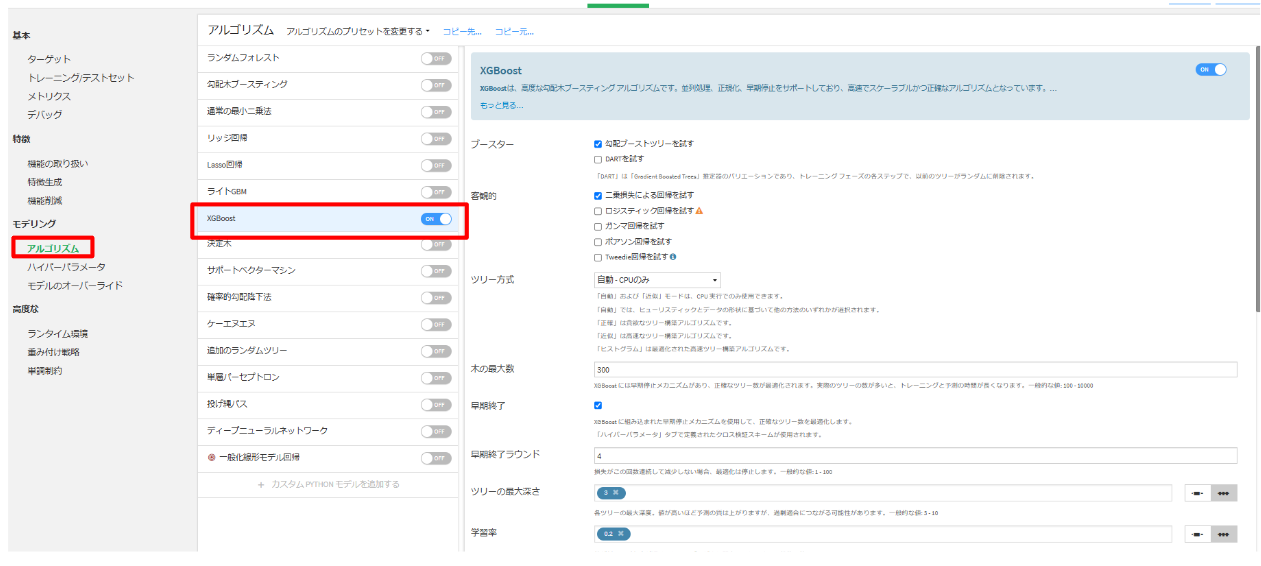




XGBoostとは?
最初に作成したモデルの誤差を修正するモデルを繰り返し作成し、最終的に高精度なモデルを構築する手法。
仕組み
- 初期モデルの構築(最初の決定木を作成)
- 誤差を修正するモデルの追加(前のモデルのズレを補正)
- 複数のモデルを組み合わせて高精度なモデルを作成
評価

- 説明可能性
- 機能の重要性:
shell weightの重要度が大きい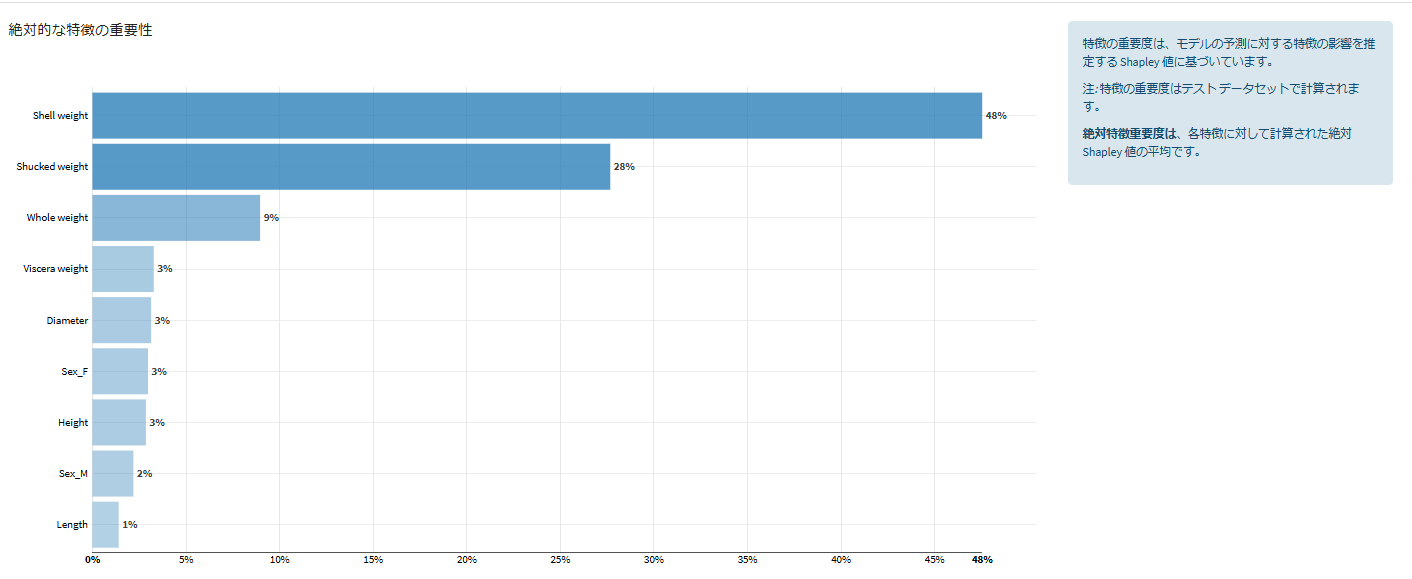
- 機能効果:
shell weightの値が大きいほど、Ringsが高くなる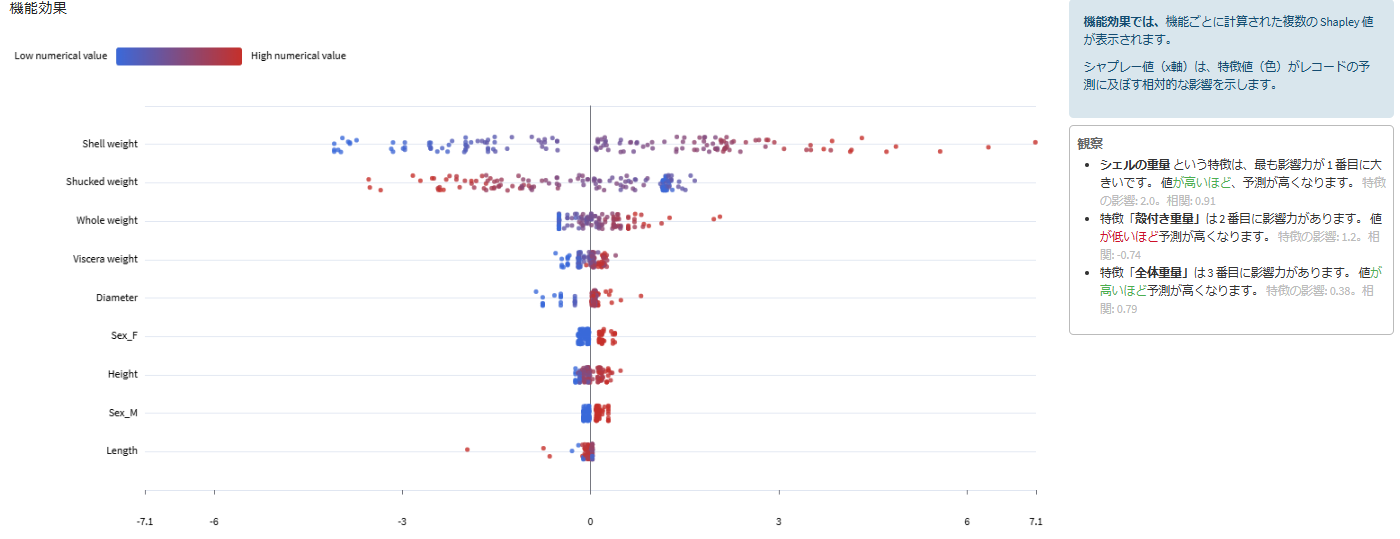
- 機能の重要性:


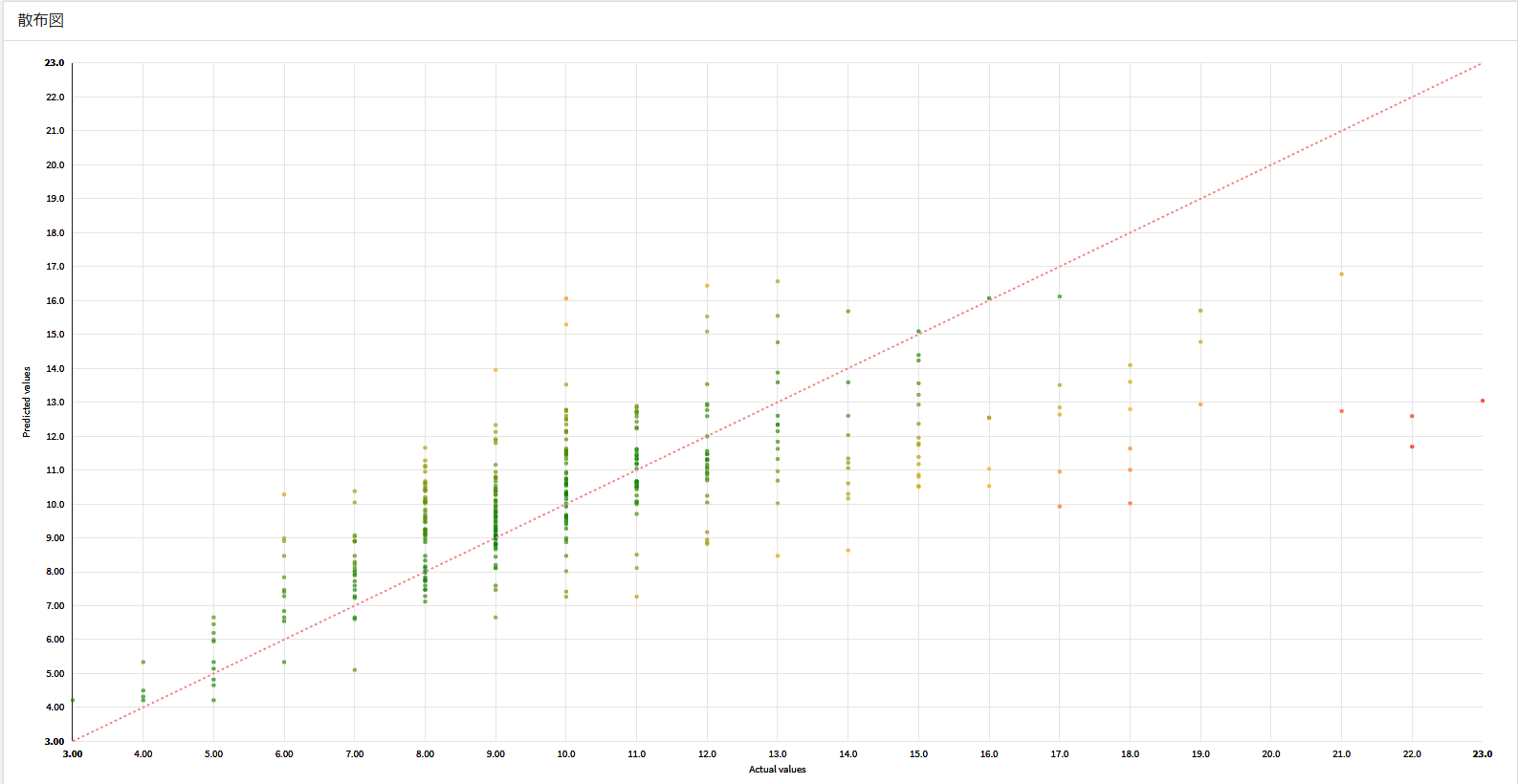
- 散布図:実数が高いほど予測精度が悪くなる

予測

- 評価したモデルを展開します。
- モデルを利用したデータ予測で、スコアリングを選択します。(出力名:
test_split_scored) - 予測したいデータセット(
test_split)を入力に選択します。 - 出力する列を選択して実行します。

提出

train_split_scoredを選択して、ヘッダーなしでエクスポートします。- SIGNATE上で、提出します。
結果

結果は、約2.13でした。Ringsの予測結果が誤差2.13あることを意味します。
この誤差は年齢が若いほど相対的に大きな影響を与えると考えられます。例えば、収穫時期の判断を誤ると、十分に成長していないアワビを収穫してしまい、小ぶりな個体が市場に出回るリスクがあります。
一方で、年齢がある程度高くなると、アワビはすでに成長しきっているため、誤差の影響は相対的に小さくなると考えられます。そのため、誤差 2.13 の影響は年齢によって異なり、モデルの予測結果の解釈にも影響を与える可能性があります。
改善点
- 特徴量の選定や作成を工夫する
- 変数A * 変数Bなどで新しい変数を作成する
- より高性能のLightGBMなどを用いる
まとめ
今回は、Dataikuを用いてアワビの年齢予測を行いました。前処理は最小限にとどめましたが、Dataikuではビジュアルレシピの準備を活用することで、ノーコードでさまざまなデータ加工が可能です。そのため、モデル構築だけでなく、前処理を含む幅広いデータ処理を直感的に行えます。
また、予測結果の誤差は約 2.13 であり、特に年齢が若いアワビほど誤差の影響が大きくなることが考えられました。これにより、収穫のタイミングを見極める際には慎重な判断が必要であることが分かりました。今後、特徴量の追加や前処理の工夫を行うことで、さらに精度を向上させることができるかもしれません。
ぜひ、Dataikuを活用して売上予測や顧客分析など、ビジネスの課題解決にデータ分析を取り入れてみてください!
